【Deepseek学习大模型推理】MOONCAKE: A KVCache-centric Architecture 第一部分引言部分
摘要
MOONCAKE 是月之暗面(Moonshot AI)开发的大语言模型聊天机器人服务 Kimi 的推理服务平台。该平台以 KVCache 为中心,采用分离式架构——不仅将预填充(prefill)和解码(decoding)集群解耦,还通过高效利用 GPU 集群中未被充分利用的 CPU、DRAM、SSD 和网卡(NIC)资源,构建了分离式 KVCache。MOONCAKE 的核心是其基于 KVCache 的全局缓存系统,以及一个旨在最大化吞吐量同时严格遵守延迟相关服务等级目标(SLOs)的调度器。
实验表明,MOONCAKE 在处理长上下文输入场景中表现优异。基于真实流量测试,相较于基线方法,MOONCAKE 在满足 SLO 的前提下,将有效请求容量提升了 59%∼498%。目前,MOONCAKE 已在数千个节点上部署,每天处理超过 千亿 token。在实际生产环境中,其创新架构使 Kimi 在 NVIDIA A800 和 H800 集群上的请求处理能力较此前系统分别提升 115% 和 107%。
1 引言
随着大语言模型(LLMs)在各类场景中的快速应用[1-4],LLM 推理服务的工作负载呈现出显著的多样化特征。这些工作负载在输入/输出长度、请求到达分布上存在差异,更重要的是,它们对服务等级目标(SLOs)提出了不同需求。作为模型即服务(MaaS)提供商,Kimi [5] 的核心目标之一是解决一个包含多重复杂约束的优化问题:优化目标是最大化整体有效吞吐量(直接影响收入),而约束条件则体现为不同层级的 SLOs。这些 SLOs 通常涉及与延迟相关的要求,主要包括首 Token 响应时间(TTFT)和 Token 间隔时间(TBT)。
为实现这一目标,前提是充分利用 GPU 集群中的各类资源。具体而言,尽管 GPU 服务器目前多以高集成化节点形式提供(如 DGX/HGX 超级计算机[6]),但需将其解耦并重组为多个分离式资源池,每个资源池针对不同但协作的目标进行优化。例如,许多研究者[7-9]建议将预填充(prefill)服务器与解码(decoding)服务器分离,因为这两个阶段的 LLM 推理服务具有截然不同的计算特性。
在进一步推进这一分离策略的过程中,我们通过整合 GPU 集群的 CPU、DRAM、SSD 及 RDMA 资源(统称为 MOONCAKE Store),设计了一种分离式 KVCache。这一创新架构利用未被充分使用的资源,实现了高效的近 GPU 前缀缓存(near-GPU prefix caching),显著提升了全局缓存容量和节点间传输带宽。由此构建的分布式 KVCache 系统体现了“以更多存储换取更少计算”的设计原则。
如图 1 所示,这一策略使 Kimi 在满足许多关键实际场景的 SLO 要求时,最大吞吐量能力大幅提升。后文将首先从数学角度分析该策略对 LLM 推理服务的益处,并基于真实数据实证评估其有效性(§2.2);随后详细阐述实现这一 PB 级分离式缓存的设计方案——其通过高达 8×400 Gbps 的 RDMA 网络互联(§3.2)。
基于这一理念,我们还发现 KVCache 的调度 是 LLM 推理服务的核心,因此提出了对应的分离式架构。图 2 展示了我们当前以 KVCache 为中心的 LLM 服务分离式架构(命名为 MOONCAKE)。对于每个请求,全局调度器(Conductor)会按以下步骤选择一对预填充(prefill)与解码(decoding)实例进行调度:
- 转移可复用 KVCache:向选定的预填充实例尽可能多地转移可复用的 KVCache;
- 分块/分层预填充:以分块或分层方式完成预填充阶段,并将生成的输出 KVCache 持续流式传输至对应的解码实例;
- 加载缓存并批量解码:在解码实例加载 KVCache,并将请求加入连续批处理(continuous batching)流程以生成最终输出。
尽管流程看似直观,但由于诸多限制因素,实例选择策略 实际极为复杂。在预填充阶段,核心目标是最大化 KVCache 复用以规避冗余计算,但分布式 KVCache 池面临容量与访问延迟的双重挑战。因此,Conductor 需以 KVCache 感知 的方式调度请求,并执行换出(swapping)、复制(replication)等调度操作:最热门的缓存块应复制到多个节点以避免读取拥塞,而最冷门的则应换出以降低保留成本。
相比之下,解码阶段的优化目标与约束条件截然不同。其目标在于聚合尽可能多的 Token 形成解码批次以提高模型浮点运算利用率(MFU),但这一目标不仅受限于 TBT SLO,还受制于显存(VRAM)中可容纳的聚合 KVCache 总量。
在 §4 中,我们将详述以 KVCache 为中心 的请求调度算法。该算法通过 TTFT 和 TBT SLOs 衡量用户体验与实例负载间的平衡,并包含一种 基于启发式的自动热点迁移方案 —— 无需精准预测未来 KVCache 使用情况即可实现热门缓存块复制。实验结果表明,该调度算法在实际场景中显著降低了 TTFT。
我们还将阐述系统实现过程中的关键设计选择,尤其是当前研究中未充分覆盖的部分。例如,关于 预填充/解码(P/D)分离架构,学术界对其大规模落地的可行性仍存争议,主要涉及带宽需求与分块预填充(如 Sarathi-Serve [10])的权衡。我们通过与 vLLM 对比证明:通过 高度优化的传输引擎,通信挑战可被有效应对,且 P/D 分离架构在严格 SLO 限制场景中更具优势(§5.2)。
此外,我们讨论了如何实现一个独立的预填充节点池,以无缝处理上下文长度的动态分布。为此,我们设计了 分块流水线并行(Chunked Pipeline Parallelism, CPP)机制,支持将单个请求的处理过程横向扩展至多个节点,这对降低长上下文输入的 TTFT 至关重要。相比传统基于序列并行(Sequence Parallelism, SP)的方案,CPP 减少了网络消耗,并降低了对频繁弹性扩展的依赖(§3.3)。
MOONCAKE目前是Kimi的推理服务平台,已成功应对指数级增长的工作负载(日处理token量超1000亿)。根据历史统计数据,MOONCAKE的创新架构使Kimi在A800和H800集群上分别实现了比原有系统高115%和107%的请求处理能力。为确保结果可复现性同时保护专有信息,我们基于实际工作负载回放轨迹,提供了与LLaMA3-70B架构相同的虚拟模型的详细实验结果。这些轨迹数据以及MOONCAKE的KVCache传输基础设施已开源,地址为https://github.com/kvcache-ai/Mooncake。
在基于公开数据集和真实工作负载的端到端实验中,MOONCAKE在长上下文场景中表现卓越。相比基线方法,MOONCAKE在满足SLO的同时,有效请求容量提升最高达498%。在§5.3中,我们将MOONCAKE Store与本地缓存设计对比,发现MOONCAKE Store的全局缓存设计显著提升了缓存命中率。实验显示,其缓存命中率最高达到本地缓存的2.36倍,从而节省了最多48%的预填充计算时间。据我们所知,MOONCAKE是首个在大规模部署场景中证明分布式KVCache池可跨不同对话会话和查询共享KVCache显著收益的系统。我们还评估了MOONCAKE中支持高速RDMA传输的传输引擎性能,结果显示其速度比现有解决方案快约2.4倍和4.6倍(§5.4)。
2 预备知识与问题定义
2.1 LLM服务的服务级别目标(SLO)
现代大型语言模型(LLMs)基于Transformer架构,其通过注意力机制和多层感知机(MLP)处理输入。流行的Transformer模型(如GPT[11]和LLaMA[12])采用仅解码器结构。每个推理请求在逻辑上分为两个阶段:预填充阶段(prefill stage)和解码阶段(decoding stage)。
在预填充阶段,所有输入Token以并行方式处理,因此该阶段通常计算密集。此阶段生成第一个输出Token,同时存储计算得到的键值中间结果(即KVCache)。解码阶段则利用该KVCache自回归生成新Token。由于自回归生成的限制,解码阶段每次迭代仅能处理单个Token,导致其内存受限且计算时间随批量大小呈次线性增长。因此,连续批处理(continuous batching)[13, 14]是解码阶段广泛采用的优化方法:在每次迭代前,调度器检查状态,将新到达的请求加入批次,并移除已完成的请求。
由于预填充阶段和解码阶段的显著差异特性,MaaS(Model-as-a-Service)提供商采用不同指标衡量其对应的服务级别目标(SLO)。具体而言,预填充阶段主要关注从请求到达至生成首个Token的延迟,即首Token生成时间(TTFT);而解码阶段则聚焦于同一请求连续生成Token之间的延迟,即Token间生成时间(TBT)。
在实际部署中,若监控检测到未达SLO的情况,需通过增加推理资源或拒绝部分新请求来缓解集群负载。然而,由于当前GPU资源供应的临时性限制,弹性扩展推理集群通常不可行。因此,我们选择主动拒绝预测无法满足SLO的请求以降低集群负载。我们的核心目标是在满足SLO的前提下最大化整体吞吐量,这一概念在其他研究中被称为“有效吞吐量”(goodput)[8, 15]。
2.2 以存储换计算
为满足上述严格的SLO要求,一种常用解决方案是缓存已生成的KVCache并在发现前缀匹配时复用。然而,现有方法[16–18]通常将缓存限制在本地HBM和DRAM中,假设全局调度所需的传输带宽过高。但如§5.3所述,本地DRAM容量仅支持理论缓存命中率的50%,这使得全局缓存设计成为必要。本节通过数学分析实际所需的带宽,解释分布式缓存的优势(尤其针对LLaMA3-70B等大模型),更多实验结果将在§5.4.2展示。
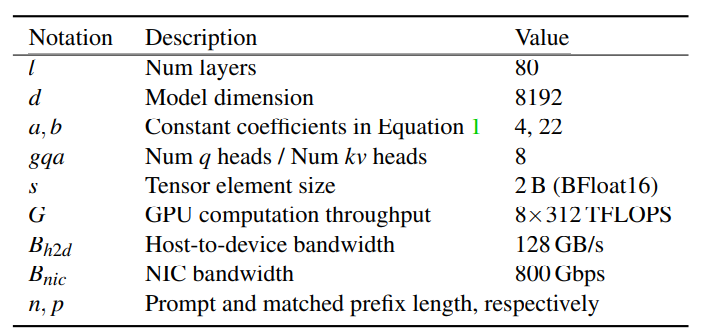
我们的分析基于表1的符号定义,并结合LLaMA3-70B的具体参数。本质上,当前主流LLM均为自回归语言模型,每个Token的KVCache仅依赖自身及前置Token。因此,相同输入前缀对应的KVCache可复用且不影响输出精度。若当前请求的长度为n的提示(prompt)与已缓存KVCache共享长度为p的公共前缀,则其预填充过程可优化为:
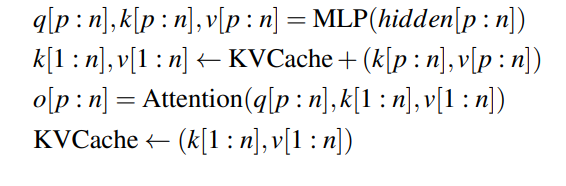
(注:KVCache+表示将新计算的k/v与缓存的k/v拼接)
给定输入长度n,预填充阶段的FLOPS(浮点运算次数)可计算为:
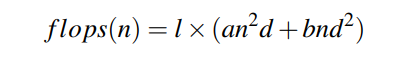
因此,复用KVCache可减少预填充阶段约 l × (a p² d + b p d²) 的计算成本。但需将缓存的KVCache传输至预填充GPU的HBM中,其数据量为 p × l × (2 × d / gqa) × s。假设平均计算吞吐量为G,平均KVCache加载速度为B(B由B_h2d和B_nic的较小值决定),当满足以下条件时,复用KVCache在TTFT优化上是可行的:
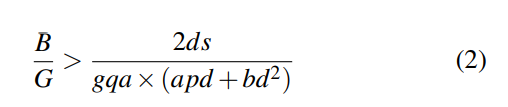
在此场景下,复用KVCache不仅能减少GPU时间和成本,还能通过降低TTFT提升用户体验。带宽B与计算吞吐量G的比值条件更容易在d值较大时满足(d与模型规模成正比)。例如,在搭载8×A800 GPU的机器上运行LLaMA3-70B且前缀长度为8192时,公式(2)要求的最小B为6 GB/s;对于8×H800机器,该需求上升至19 GB/s。此外,实际场景中由于传输阶段无法完全重叠,实际带宽需求更高。但如§5.4.2所示,单NVIDIA A800 HGX网络的100 Gbps网卡完全利用时,已足以满足该条件。
float 计算怎么来的?
在LLM推理的预填充阶段,FLOPS(每秒浮点运算次数)的计算公式来源于Transformer架构中自注意力机制和前馈神经网络(FFN)的计算复杂度分析。以下是公式的推导逻辑:
公式分解
给定输入长度为 ( n ),模型维度为 ( d ),层数为 ( l ),则预填充阶段的总计算量为:
flops ( n ) = l × ( a ⋅ n 2 d + b ⋅ n d 2 ) \text{flops}(n) = l \times \left( a \cdot n^2 d + b \cdot n d^2 \right) flops(n)=l×(a⋅n2d+b⋅nd2)
其中:
- a ⋅ n 2 d a \cdot n^2 d a⋅n2d:自注意力机制的计算复杂度。
- b ⋅ n d 2 b \cdot n d^2 b⋅nd2:**前馈神经网络(FFN)**的计算复杂度。
- l l l:模型层数,每层重复上述计算。
1. 自注意力机制的计算( a ⋅ n 2 d a \cdot n^2 d a⋅n2d)
自注意力的计算分为以下步骤:
-
生成Q/K/V矩阵:对输入序列的每个Token,通过线性变换生成查询(Q)、键(K)、值(V)矩阵。
- 每个矩阵的计算复杂度为 O ( n ⋅ d 2 ) O(n \cdot d^2) O(n⋅d2)(矩阵乘法: n × d n \times d n×d与 d × d d \times d d×d。
- 三个矩阵(Q, K, V)的总复杂度为 3 ⋅ n d 2 3 \cdot n d^2 3⋅nd2。
-
点积注意力计算:
- 计算Q与K的点积( O ( n 2 d ) O(n^2 d) O(n2d)),再与V相乘( O ( n 2 d ) O(n^2 d) O(n2d))。
- 总复杂度为 2 ⋅ n 2 d 2 \cdot n^2 d 2⋅n2d。
-
输出投影:将注意力结果通过线性变换映射回原始维度,复杂度为 O ( n d 2 ) O(n d^2) O(nd2)。
总计:
3 n d 2 + 2 n 2 d + n d 2 = 2 n 2 d + 4 n d 2 3n d^2 + 2n^2 d + n d^2 = 2n^2 d + 4n d^2 3nd2+2n2d+nd2=2n2d+4nd2
若合并系数,可简化为 a ⋅ n 2 d a \cdot n^2 d a⋅n2d,其中 ( a = 2 )(实际中可能因多头合并或优化调整为 ( a = 4 ))。
2. 前馈神经网络(FFN)的计算(( b \cdot n d^2 ))
FFN通常包含两个全连接层:
- 第一层:将输入维度 ( d ) 扩展到更高维度(如 ( 4d )),复杂度为 O ( n ⋅ d ⋅ 4 d ) = 4 n d 2 O(n \cdot d \cdot 4d) = 4n d^2 O(n⋅d⋅4d)=4nd2。
- 第二层:将高维映射回 ( d ),复杂度为 O ( n ⋅ 4 d ⋅ d ) = 4 n d 2 O(n \cdot 4d \cdot d) = 4n d^2 O(n⋅4d⋅d)=4nd2。
- 激活函数:如GELU,复杂度可忽略。
总计:
4 n d 2 + 4 n d 2 = 8 n d 2 4n d^2 + 4n d^2 = 8n d^2 4nd2+4nd2=8nd2
合并系数后表示为 b ⋅ n d 2 b\cdot n d^2 b⋅nd2,其中 ( b = 8 )(实际中可能因模型结构调整为 ( b = 22 ),如LLaMA3-70B的FFN设计更复杂)。
3. 系数调整与模型差异
- 系数 ( a ):在LLaMA3-70B中,可能因多头注意力合并或优化策略(如分组查询注意力GQA),( a ) 被调整为 4。
- 系数 ( b ):LLaMA3-70B的FFN可能采用更复杂的结构(如多层或扩展因子更大),导致 ( b = 22 )。
4. 最终公式
将自注意力和FFN的计算复杂度相加,并乘以层数 ( l ):
flops ( n ) = l × ( a ⋅ n 2 d ⏟ 自注意力 + b ⋅ n d 2 ⏟ FFN ) \text{flops}(n) = l \times \left( \underbrace{a \cdot n^2 d}_{\text{自注意力}} + \underbrace{b \cdot n d^2}_{\text{FFN}} \right) flops(n)=l×(自注意力 a⋅n2d+FFN b⋅nd2)
代入LLaMA3-70B的参数(( l=80, a=4, b=22 )):
flops ( n ) = 80 × ( 4 n 2 ⋅ 8192 + 22 n ⋅ 819 2 2 ) \text{flops}(n) = 80 \times \left( 4n^2 \cdot 8192 + 22n \cdot 8192^2 \right) flops(n)=80×(4n2⋅8192+22n⋅81922)
验证与意义
- 带宽与计算的权衡:公式用于判断复用KVCache的可行性(如公式2),当传输带宽 ( B ) 足够大时,复用缓存可减少计算量,从而降低TTFT。
- 模型规模的影响:随着模型维度 ( d ) 增大(如LLaMA3-70B),FFN的计算复杂度 b ⋅ n d 2 b \cdot n d^2 b⋅nd2主导总计算量,因此全局缓存设计对大模型更关键。
通过此公式,可以量化预填充阶段的计算需求,指导系统优化(如缓存策略、硬件选型)。



