算法——结合实例了解广度优先搜索(BFS)搜索
一、广度优先搜索初印象
想象一下,你身处一座陌生的城市,想要从当前位置前往某个景点,你打开手机上的地图导航软件,输入目的地后,导航软件会迅速规划出一条最短路线。这背后,就可能运用到了广度优先搜索(BFS,Breadth-First Search)算法。
广度优先搜索是一种用于遍历或搜索图(Graph)或树(Tree)的算法 ,它的核心思想是从起始节点开始,以广度为优先逐层向外扩展。就像平静湖面投入一颗石子,激起的涟漪会一圈一圈向外扩散,BFS 从起始节点出发,先访问与它直接相连的所有节点,再依次访问这些节点的未访问过的邻居节点,以此类推,直到找到目标节点或遍历完所有可达节点。这和深度优先搜索(DFS,Depth-First Search)形成鲜明对比,DFS 是沿着一条路径尽可能深地探索下去,直到无法继续才回溯到前一个节点继续探索其他分支。
在实际应用中,BFS 特别适合解决需要寻找最短路径、层级结构或者连通性等问题。比如在地图导航中找最短路线,在社交网络分析中寻找两人之间的最短关系链,在迷宫游戏里寻找从起点到终点的最短路径等。
二、BFS 的工作原理
(一)关键步骤
选择起始节点:在开始搜索前,首先要确定一个起始节点。这个节点是整个搜索过程的起点,后续的搜索都是基于这个节点展开的。比如在一个社交网络中寻找用户 A 和用户 B 之间的最短关系链,用户 A 就可以作为起始节点。
用队列维护顺序:BFS 使用队列(Queue)这种数据结构来存储待访问的节点。队列具有先进先出(FIFO,First-In-First-Out)的特性,这与 BFS 逐层扩展的思想相契合。在搜索开始时,将起始节点加入队列。
循环处理队列:只要队列不为空,就从队列中取出一个节点进行处理。假设当前取出的节点为 X,接着检查节点 X 是否为目标节点。如果是,那么就找到了目标,搜索过程结束;如果不是,则访问节点 X 的所有未访问过的邻居节点,并将这些邻居节点加入队列。这个过程不断重复,直到队列为空或者找到目标节点。例如在一个地图中寻找从地点 A 到地点 Z 的最短路径,从地点 A 开始,将其相邻的地点(如 B、C、D)加入队列,然后处理队列中的 B,再将 B 的未访问过的相邻地点加入队列,如此循环,直到找到地点 Z 或者队列为空。
(二)核心数据结构
队列在 BFS 中起着至关重要的作用。它保证了搜索过程按照层次顺序进行,即先访问的节点的邻居节点在后续被访问。以二叉树的层次遍历为例,首先将根节点入队,然后从队列中取出根节点进行访问,接着将根节点的左子节点和右子节点依次入队。此时队列中存储的是根节点的下一层节点,下一次循环时,会从队列中取出这两个子节点进行访问,并将它们的子节点入队,以此类推,从而实现了二叉树的层次遍历,这正是 BFS 在二叉树结构中的应用体现。
(三)与 DFS 的对比
搜索策略:DFS 是尽可能深地搜索图的分支,当节点的所有边都已被探寻过,搜索将回溯到发现该节点的那条边的起始节点。而 BFS 从根节点(或某个任意节点)开始访问,并探索最近邻的节点,如果所有最近邻的节点都已被访问过,搜索将回溯到发现最近邻节点的节点 ,逐层向外扩展。例如在一个迷宫中,DFS 会沿着一条通道一直走到底,直到无法继续才回头换另一条通道;BFS 则是从起点开始,同时向所有相邻的通道探索,一层一层地向外扩散。
数据结构:DFS 通常使用栈(Stack)来实现,因为栈的后进先出(LIFO,Last-In-First-Out)特性与 DFS 的回溯策略相匹配,在递归实现 DFS 时,系统栈会自动记录函数调用的层次和返回地址,从而实现回溯。而 BFS 通常使用队列来实现,利用队列的先进先出特性保证先访问的节点的邻居节点在后续被访问。
遍历顺序:DFS 的遍历顺序取决于搜索树的深度,通常不是按照节点的层次顺序。比如对于一个简单的树结构,根节点为 A,A 有两个子节点 B 和 C,B 又有子节点 D 和 E,C 有子节点 F,DFS 的遍历顺序可能是 A - B - D - E - C - F 。而 BFS 按照节点的层次顺序遍历,对于上述树结构,BFS 的遍历顺序是 A - B - C - D - E - F。
搜索效率:对于某些图,DFS 可能需要更长的时间才能访问所有节点,因为它会深入搜索一个分支直到无法继续,然后再回溯,在一个非常深且分支众多的树中,DFS 可能会在一个很深的分支中浪费大量时间,而目标节点可能在较浅的其他分支。对于某些图,特别是当目标节点距离根节点较近时,BFS 可能更快找到目标节点,因为它会首先访问所有与根节点相邻的节点 ,如果目标节点就在根节点的下一层,BFS 能迅速找到,而 DFS 可能会深入到其他分支而错过。
空间复杂度:DFS 在递归实现中,空间复杂度可能取决于递归调用的深度(或栈的大小),在最坏情况下,当图是一条链状结构时,DFS 的空间复杂度为 O (V),V 为节点数。在迭代实现中,DFS 的空间复杂度通常较低 。BFS 的空间复杂度可能更高,因为它需要存储当前层次的所有节点,这通常需要一个与节点数量成比例的队列空间,在最坏情况下,当图是一个完全二叉树时,BFS 需要存储最底层的节点,数量接近节点总数的一半,空间复杂度为 O (V)。
应用场景:DFS 适用于需要找到所有解或需要回溯的场景,如迷宫问题中寻找所有从起点到终点的路径、图的连通性问题、拓扑排序等。BFS 适用于需要找到最短路径或最小值的场景,如在地图导航中找最短路线、社交网络分析中寻找两人之间的最短关系链、在无权图中寻找最短路径等。
三、BFS 的时间复杂度
(一)邻接表表示
在使用邻接表表示图时,BFS 的时间复杂度为 O (V + E) ,其中 V 是顶点数,E 是边数。这是因为在 BFS 过程中,每个顶点都会被访问一次,其时间复杂度为 O (V) 。同时,对于每个顶点,都需要遍历其所有的邻接边,而每条边恰好会被访问一次,这部分的时间复杂度为 O (E)。例如,在一个社交网络中,将用户看作顶点,用户之间的好友关系看作边,使用邻接表存储这个社交网络。在进行 BFS 时,每个用户(顶点)都会被访问一次,以查找其好友(邻接边),而每条好友关系(边)也只会被访问一次,所以总的时间复杂度为 O (V + E) 。
(二)邻接矩阵表示
当图使用邻接矩阵表示时,BFS 的时间复杂度为 O (V²) 。因为在邻接矩阵中,判断两个顶点之间是否有边相连,需要遍历整个矩阵的对应行和列,对于每个顶点,查找其邻接顶点的操作时间复杂度为 O (V) 。由于有 V 个顶点,所以总的时间复杂度为 O (V²) 。比如在一个表示城市交通网络的邻接矩阵中,城市是顶点,城市之间的道路是边,在进行 BFS 时,对于每个城市(顶点),都需要遍历整个矩阵来确定其与其他城市(顶点)的连接情况,这就导致了较高的时间复杂度。
四、BFS 的应用场景
(一)最短路径查找
在无权图(边没有权重的图)中,BFS 是寻找最短路径的有效方法。以一个简单的地图为例,地图上的各个地点可以看作是图的节点,地点之间的连接(如道路)看作是边,且这些边没有权重(即所有道路通行成本相同)。假设我们要从城市 A 前往城市 Z,使用 BFS,从城市 A 开始,将其所有相邻的城市(如 B、C、D)加入队列,此时队列中的城市距离 A 的距离都为 1。然后从队列中取出城市 B,将 B 的所有未访问过的相邻城市加入队列,这些城市距离 A 的距离为 2。不断重复这个过程,直到找到城市 Z。由于 BFS 是逐层扩展的,所以当找到城市 Z 时,所经过的路径就是从 A 到 Z 的最短路径。在实际的导航应用中,如百度地图、高德地图等,在规划最短路线时,如果不考虑路况、道路收费等因素(即可以简化为无权图),BFS 就可以作为一种基础的路径规划算法。
(二)层级遍历
在二叉树的层序遍历中,BFS 能很好地实现按层级顺序访问节点。以一个简单的二叉树为例,根节点为 A,A 有左子节点 B 和右子节点 C,B 又有左子节点 D 和右子节点 E,C 有右子节点 F。使用 BFS 进行层序遍历,首先将根节点 A 加入队列。然后从队列中取出 A 并访问,接着将 A 的子节点 B 和 C 加入队列,此时队列中存储的是二叉树的第二层节点。下一次循环,从队列中取出 B 并访问,将 B 的子节点 D 和 E 加入队列;再取出 C 并访问,将 C 的子节点 F 加入队列,此时队列中存储的是二叉树的第三层节点。不断重复这个过程,直到队列为空,最终得到的访问顺序就是 A - B - C - D - E - F,这正是二叉树的层序遍历结果。在实际的数据库索引结构中,如 B 树、B + 树,其节点的层级遍历就可以利用 BFS 来实现,这有助于对索引结构进行分析和维护。
(三)社交网络分析
在社交网络中,BFS 可以用于寻找两个用户之间的最短关系链。假设我们有一个社交网络,用户是节点,用户之间的好友关系是边。要寻找用户 A 和用户 B 之间的最短关系链,从用户 A 开始,将 A 的所有好友加入队列,这些好友是 A 的一度关系。然后从队列中取出 A 的一个好友,比如用户 C,将 C 的所有未访问过的好友加入队列,这些好友是 A 的二度关系。持续这个过程,直到找到用户 B。此时,从 A 到 B 经过的路径就是他们之间的最短关系链。例如在微信的社交关系中,如果要查找用户张三和用户李四之间的最短联系路径,就可以运用 BFS 算法来实现。
(四)网络广播
在网络广播中,BFS 可以模拟信息在网络中的传播过程。假设我们有一个计算机网络,节点代表计算机,边代表计算机之间的连接。当某个节点(比如节点 X)发送广播消息时,使用 BFS,首先将节点 X 的所有直接连接的节点加入队列,这些节点接收到消息,这是第一轮传播。然后从队列中取出一个节点,将该节点的所有未接收到消息的直接连接节点加入队列,这些节点接收到消息,这是第二轮传播。不断重复这个过程,直到所有可达节点都接收到消息。通过这种方式,可以清晰地模拟出广播消息在网络中的传播路径和传播范围。在实际的局域网广播中,BFS 的这种原理可以用于分析广播风暴的传播情况,从而采取相应的措施进行防范。
(五)Web 爬虫
在 Web 爬虫中,BFS 可以按照广度优先的方式遍历网页。从一个起始网页开始,将该网页的所有链接(即该网页与其他网页的 “边”)加入队列,这是第一层。然后从队列中取出一个链接,访问对应的网页,并将该网页中的所有新链接加入队列,这是第二层。不断重复这个过程,爬虫就可以按照广度优先的方式遍历整个网站或者互联网的一部分。例如,百度搜索引擎的爬虫在抓取网页时,就可以采用 BFS 策略,从一些种子网页开始,逐层抓取新的网页,从而建立起庞大的网页索引库。
(六)图的连通性判断
在判断图是否连通时,BFS 可以发挥作用。从图中的任意一个节点开始进行 BFS 搜索,如果在搜索结束后,所有节点都被访问到,那么说明图是连通的;如果存在未被访问到的节点,那么图是非连通的,并且可以通过多次从不同的未访问节点开始 BFS 搜索,找出图中的连通分量。例如在一个城市的交通网络中,如果把城市看作节点,道路看作边,通过 BFS 判断交通网络是否连通,有助于分析城市交通的完整性和可靠性。如果发现某个区域的节点在 BFS 搜索中未被访问到,就意味着该区域与其他区域的交通连接存在问题,可能需要进一步规划和建设交通设施。
(七)二分图检测
BFS 可以用于判断图是否为二分图。二分图是一种特殊的图,其节点可以被分成两个不相交的集合 A 和 B,使得图中的每条边的两个端点分别属于集合 A 和集合 B。从图中的任意一个节点开始进行 BFS,将该节点标记为集合 A 中的节点,然后将其所有邻居节点标记为集合 B 中的节点。接着,对于这些邻居节点,将它们的邻居节点标记为集合 A 中的节点(如果这些邻居节点还未被标记)。在这个过程中,如果发现某个节点的邻居节点已经被标记为与它相同的集合,那么说明图不是二分图;如果遍历完所有节点都没有出现这种情况,那么图是二分图。在实际的任务分配场景中,比如将任务分配给不同的团队,每个任务可以看作一个节点,任务之间的关联看作边,如果任务分配图是二分图,就可以将任务合理地分配给两个不同的团队,利用 BFS 判断图是否为二分图,有助于实现这种合理的任务分配。
五、BFS 的实例解析

(一)BFS 遍历二叉树
在二叉树的遍历中,层序遍历是 BFS 的典型应用。下面通过 Python 代码实现二叉树的层序遍历,并详细解释其执行过程。
from collections import deque
class TreeNode:
def \_\_init\_\_(self, value):
self.value = value
self.left = None
self.right = None
def bfs\_level\_order(root):
if root is None:
return
queue = deque()
queue.append(root)
while queue:
node = queue.popleft()
print(node.value, end=' ')
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
\# 创建一个简单的二叉树
\# A
\# / \\
\# B C
\# / \ \\
\# D E F
root = TreeNode('A')
root.left = TreeNode('B')
root.right = TreeNode('C')
root.left.left = TreeNode('D')
root.left.right = TreeNode('E')
root.right.right = TreeNode('F')
print("BFS层序遍历结果:")
bfs\_level\_order(root)
代码解释如下:
TreeNode 类定义:定义了一个TreeNode类,用于表示二叉树的节点。每个节点包含一个value值,以及指向左子节点left和右子节点right的引用。
bfs_level_order 函数实现:
首先判断根节点root是否为空,如果为空,直接返回,因为空树无需遍历。
创建一个deque队列queue,并将根节点root加入队列。这是 BFS 的起始点,队列用于存储待访问的节点。
使用while循环,只要队列不为空,就继续循环。在每次循环中:
从队列的左侧取出一个节点node,这是当前要访问的节点。
打印当前节点node的值,实现对节点的访问操作。
检查当前节点node的左子节点是否存在,如果存在,将其加入队列。这是为了后续访问左子节点。
检查当前节点node的右子节点是否存在,如果存在,将其加入队列。这是为了后续访问右子节点。
构建二叉树并执行遍历:创建了一个简单的二叉树结构,并调用bfs_level_order函数对其进行层序遍历,打印出遍历结果。
执行过程:
初始时,队列中只有根节点A。
从队列中取出A,打印A,然后将A的左子节点B和右子节点C加入队列,此时队列中有B和C。
从队列中取出B,打印B,将B的左子节点D和右子节点E加入队列,此时队列中有C、D和E。
从队列中取出C,打印C,将C的右子节点F加入队列,此时队列中有D、E和F。
依次从队列中取出D、E和F并打印,直到队列为空,遍历结束。最终输出的层序遍历结果为A B C D E F。
(二)使用 BFS 解决迷宫最短路径问题
迷宫问题是 BFS 的常见应用场景之一,主要目标是在给定的迷宫中找到从起点到终点的最短路径。以下是一个用 Python 实现的示例,假设迷宫用二维列表表示,其中0表示可通行的路径,1表示墙壁。
from collections import deque
def is\_valid\_move(maze, visited, row, col):
rows = len(maze)
cols = len(maze\[0])
return (0 <= row < rows) and (0 <= col < cols) and \\
(maze\[row]\[col] == 0) and (not visited\[row]\[col])
def bfs\_shortest\_path\_maze(maze):
if not maze or not maze\[0]:
return None
rows, cols = len(maze), len(maze\[0])
visited = \[\[False for \_ in range(cols)] for \_ in range(rows)]
queue = deque()
\# 起点位置和路径
start = (0, 0)
end = (rows - 1, cols - 1)
if maze\[start\[0]]\[start\[1]]!= 0 or maze\[end\[0]]\[end\[1]]!= 0:
return None # 无法从起点或到达终点
queue.append((start, \[start]))
visited\[start\[0]]\[start\[1]] = True
\# 定义四个可能的移动方向:上、右、下、左
directions = \[(-1, 0), (0, 1), (1, 0), (0, -1)]
while queue:
current\_pos, path = queue.popleft()
row, col = current\_pos
\# 检查是否到达终点
if current\_pos == end:
return path
\# 尝试所有可能的移动方向
for dr, dc in directions:
new\_row, new\_col = row + dr, col + dc
if is\_valid\_move(maze, visited, new\_row, new\_col):
visited\[new\_row]\[new\_col] = True
queue.append(((new\_row, new\_col), path + \[(new\_row, new\_col)]))
return None # 无路径
\# 示例迷宫
maze = \[
\[0, 1, 0, 0, 0],
\[0, 1, 0, 1, 0],
\[0, 0, 0, 0, 0],
\[0, 1, 1, 1, 0],
\[0, 0, 0, 1, 0]
]
shortest\_path = bfs\_shortest\_path\_maze(maze)
if shortest\_path:
print("找到最短路径,路径长度为", len(shortest\_path))
print("路径为:", shortest\_path)
else:
print("没有找到从起点到终点的路径")
代码解释如下:
is_valid_move 函数:用于判断在当前迷宫状态下,从当前位置(row, col)向某个方向移动是否合法。合法的条件包括:移动后的位置在迷宫范围内,该位置是可通行的(值为0),并且该位置尚未被访问过。
bfs_shortest_path_maze 函数:
首先检查迷宫是否为空或为空列表,如果是,则直接返回None,因为无法在空迷宫中寻找路径。
获取迷宫的行数rows和列数cols,并创建一个与迷宫大小相同的二维布尔列表visited,用于记录每个位置是否被访问过,初始时所有位置都为False。
创建一个deque队列queue,用于存储待探索的位置和从起点到该位置的路径。
定义起点start为(0, 0),终点end为(rows - 1, cols - 1)。如果起点或终点位置是墙壁(值不为0),则无法从起点到达终点,直接返回None。
将起点和包含起点的路径[(0, 0)]加入队列,并将起点标记为已访问。
定义四个可能的移动方向:上(-1, 0)、右(0, 1)、下(1, 0)、左(0, -1)。
使用while循环,只要队列不为空,就继续循环。在每次循环中:
从队列左侧取出当前位置current_pos和从起点到当前位置的路径path。
检查当前位置是否为终点,如果是,则返回当前路径,因为找到了从起点到终点的路径。
遍历四个移动方向,计算新的位置(new_row, new_col)。
如果新位置是合法的移动位置(通过is_valid_move函数判断),则将新位置标记为已访问,并将新位置和更新后的路径加入队列。
如果循环结束后仍未找到终点,则返回None,表示没有找到从起点到终点的路径。
测试部分:定义了一个示例迷宫,并调用bfs_shortest_path_maze函数寻找最短路径。如果找到路径,则打印路径长度和路径;如果未找到路径,则打印提示信息。
执行过程:
初始时,队列中只有起点(0, 0)和路径[(0, 0)],并将起点标记为已访问。
从队列中取出起点(0, 0)和路径[(0, 0)],检查是否为终点,不是则尝试四个方向的移动。只有向右移动(0, 1)是合法的,将(0, 1)和路径[(0, 0), (0, 1)]加入队列,并将(0, 1)标记为已访问。
从队列中取出(0, 1)和路径[(0, 0), (0, 1)],检查是否为终点,不是则尝试四个方向的移动。向下移动(1, 1)是合法的,将(1, 1)和路径[(0, 0), (0, 1), (1, 1)]加入队列,并将(1, 1)标记为已访问。
不断重复上述过程,依次探索新的合法位置并加入队列,直到找到终点(4, 4)。最终返回从起点到终点的最短路径,例如[(0, 0), (1, 0), (2, 0), (2, 1), (2, 2), (3, 2), (4, 2), (4, 3), (4, 4)] 。
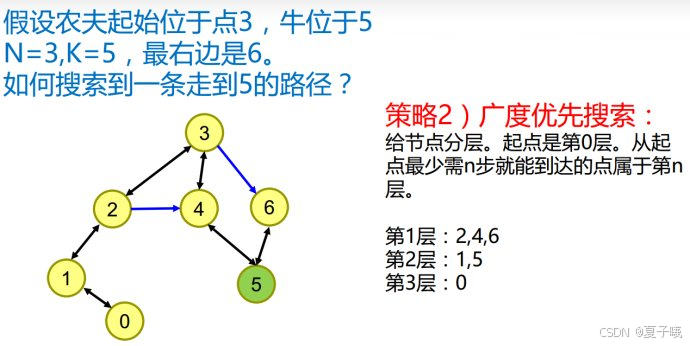
(三)农夫找牛
一位农夫在点n上,他要到奶牛所在的点k上,他可以每次从点X到点X-1或点X+1或点2*X,问他到达点k的最短次数.(0 ≤ N ≤ 100,000,0 ≤ K ≤ 100,000)
思路:看到这一道题,第一反应就是看看能否找到规律,然而很显然它没有规律可言,我们需要靠一种近似暴力的方法,而DFS在这里是行不通的,于是只能用BFS来解这道题了。
#include <iostream>
#include <stdio.h>
#include <cstring>
#include<queue>
#define pp pair<int,int>
using namespace std;
int n,k,ans;
queue<pp>q;
bool v[200004];
void bfs() {
q.push(pp(n,0));//先将n丢进队列
v[n]=1;
while(!q.empty()) {
if(q.empty())break;
pp now=q.front();
q.pop();
if(now.first==k) {
ans=now.second;
break;
}
now.second++;//接下来我们有3种操作,将现在的位置now.second 加1 或 减1 或 乘2
if(!v[now.first+1]&&now.first<k) {//边界条件不能少了
q.push(pp(now.first+1,now.second));
v[now.first+1]=1;//将已经走过的点标记为1,为什么呢??q队列中到这个数的次数是从小到大排序的,now.first+1这个点刚通过now.first被拜访过,它的此时次数肯定小于等于下一次拜访的次数.想一想为什么.
}
if(!v[now.first-1]&&now.first-1>=0) {
q.push(pp(now.first-1,now.second));
v[now.first-1]=1;
}
if(now.first<k&&(!v[now.first*2])) {
q.push(pp(now.first*2,now.second));
v[now.first*2]=1;
}
}
return;
}
int main() {
scanf("%d%d",&n,&k);
bfs();
printf("%d\n",ans);
return 0;
}
(四)找到质数所需的最少次数
给你两个四位数的质数a,b,让你通过一个操作使a变成b.这个操作可以使你当前的数x改变一位上的数使其变成另一个质数,问操作的最小次数
注意:没有前导0!!!;
例如:1033到8179可以从1033->1733->3733->3739->3779->8779->8179
思路:可以先将10000以内所有的质数记录下来,再进行BFS。
#include<iostream>
#include<stdio.h>
#include<cstring>
#include<queue>
#include<time.h>
#define N 10003
#define pp pair<int,int>
using namespace std;
int T,n,m,ans;
bool v[N],vis[N],t[N];
queue<pp>q;
void pre() {//记录10000以内的质数
for(int i=2; i<=9999; i++) {
if(!v[i]) {
t[i]=1;//t[i]=1表示i是质数
for(int j=i; j<=9999; j+=i) {
v[j]=1;
}
}
}
}
void BFS() {
q.push(pp(n,0));//先将给我们的初始数加入q队列
while(!q.empty()) {
while(!q.empty()&&vis[q.front().first])q.pop();
if(q.empty())break;
pp now=q.front();
vis[q.front().first]=1;
q.pop();
if(now.first==m) {
ans=now.second;
break;
}
for(int i=1; i<=1000; i*=10) {//枚举位数
int r=now.first-((now.first/i)%10)*i;
for(int j=0; j<=9; j++) {//枚举当前位数更改的值
if(i==1000&&j==0)continue;//特判前导0的情况!!!
if(t[r+j*i]&&!vis[r+j*i]) {
q.push(pp(r+j*i,now.second+1));//BFS的核心转移代码
}
}
}
}
return;
}
int main() {
pre();
scanf("%d",&T);
while(T--) {
while(!q.empty())q.pop();
memset(vis,0,sizeof vis);
ans=-1;
scanf("%d%d",&n,&m);
BFS();
if(ans==-1)printf("Impossible\n");
else printf("%d\n",ans);
}
return 0;
}
六、总结 BFS 的要点与应用价值

广度优先搜索(BFS)是一种基础且重要的搜索算法,其核心在于从起始节点出发,借助队列实现逐层扩展搜索,直到找到目标节点或遍历完所有可达节点。在工作原理上,BFS 通过选择起始节点,将其加入队列,然后不断从队列中取出节点,访问该节点并将其未访问的邻居节点加入队列,从而实现按层次遍历。
从时间复杂度来看,使用邻接表表示图时,BFS 的时间复杂度为 O (V + E) ,这是因为每个顶点和每条边都会被访问一次;使用邻接矩阵表示图时,时间复杂度为 O (V²) ,因为需要遍历整个矩阵。
BFS 在众多领域有着广泛应用。在最短路径查找方面,它能在无权图中高效地找到从起点到终点的最短路径;层级遍历中,二叉树的层序遍历是其典型应用;社交网络分析里,可用于寻找两个用户之间的最短关系链;网络广播时,能模拟信息在网络中的传播过程;Web 爬虫按照广度优先的方式遍历网页;判断图的连通性以及检测二分图时,BFS 也发挥着重要作用。
通过二叉树层序遍历和迷宫最短路径问题这两个实例,我们深入了解了 BFS 的实现过程和应用方法。在二叉树层序遍历中,BFS 能够按照层次顺序依次访问节点,清晰地展示树的结构;在迷宫最短路径问题中,BFS 通过逐层探索,找到从起点到终点的最短路径,充分体现了其在解决实际问题中的优势。
BFS 以其独特的搜索策略和广泛的应用场景,在算法领域占据着重要地位,为解决各种实际问题提供了有力的工具和方法。