阿里HumanAIGC 团队开源实时数字人项目ChatAnyone
简介
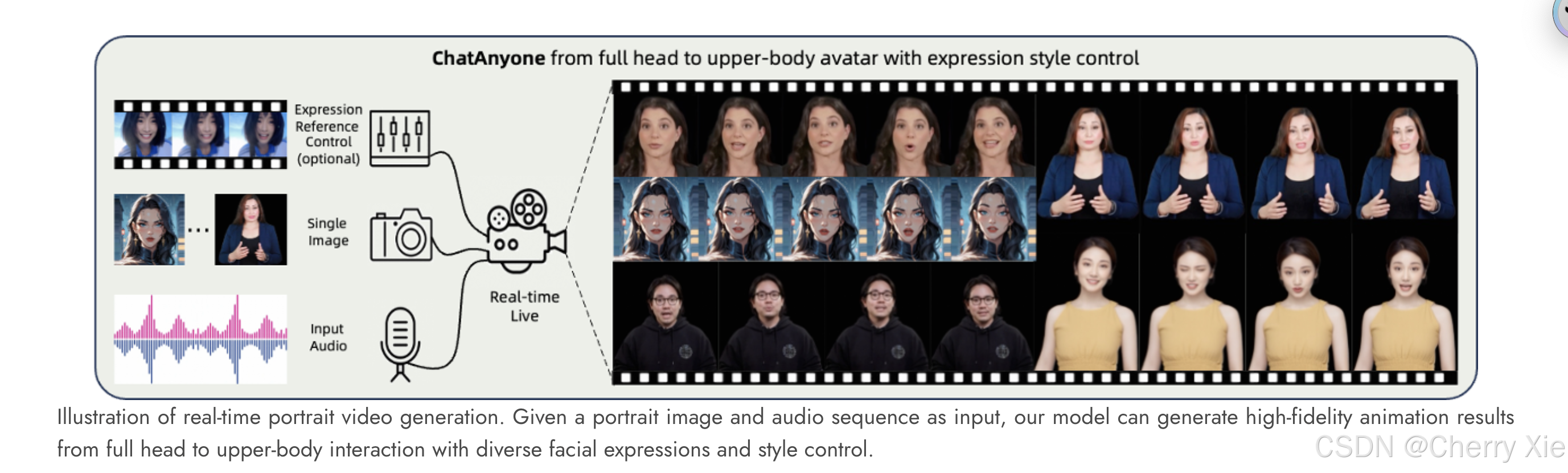
ChatAnyone 是一个由 HumanAIGC 团队开发的开源项目,专注于从单张肖像照片和音频生成实时风格化的上半身动画视频。该项目发布于 2025 年,论文《ChatAnyone: Stylized Real-time Portrait Video Generation with Hierarchical Motion Diffusion Model》由 Jinwei Qi 等人在 ArXiv 上发表,进一步阐述了其技术细节。项目背景源于虚拟主播、数字人和实时互动应用的需求增长,技术架构基于分层运动扩散模型,支持高效的实时生成。
项目背景
开发背景与目标
-
行业趋势:近年来,虚拟主播、数字人和在线教育领域的需求快速增长,用户对沉浸式体验的需求日益增加。传统的静态头像或简单语音交互已无法满足需求,实时生成动态、逼真的视频成为行业趋势。
-
技术挑战:ChatAnyone 的目标是解决实时视频生成的技术难题,包括口型同步、表情自然化、风格化输出以及双人互动场景的支持。研究显示,其在 RTX 4090 上实现了 30fps 的生成速度,分辨率最高支持 512×768,满足了实时应用的要求 [Post ID: 0].
-
应用场景:项目支持从单张照片生成上半身动画,适用于虚拟主播直播、播客视频生成、在线教育互动等场景。例如,生成双主持人播客视频,降低内容创作者的制作成本。
团队背景
HumanAIGC 是阿里巴巴集团旗下同易(Tongyi)团队的一部分,专注于以人为中心的生成式 AI 技术开发。该团队在生成式 AI 领域有多项研究成果,包括实时肖像视频生成、虚拟试穿和人物动画等。
尽管 HumanAIGC 被宣传为开源项目,但部分用户对其开源承诺有所质疑。例如,AnimateAnyone 和 Emote Portrait Alive 等相关项目曾被提及为开源,但最终未完全开放源代码,引发了社区讨论 [Web ID: 22]. 这种现象可能反映了大厂在技术创新与商业利益之间的平衡考量。
项目亮点
-
实时生成:在 RTX 4090 上实现 30fps 的生成速度,分辨率最高支持 512×768,适合消费级硬件。
-
风格化支持:支持卡通风格等多种输出风格,增强视频的可定制性。
-
双人互动:支持生成双主持人播客视频,适用于多人协作场景。
-
音频驱动:结合语音特征提取,实现口型同步和表情驱动,增强视频的真实感。
技术架构
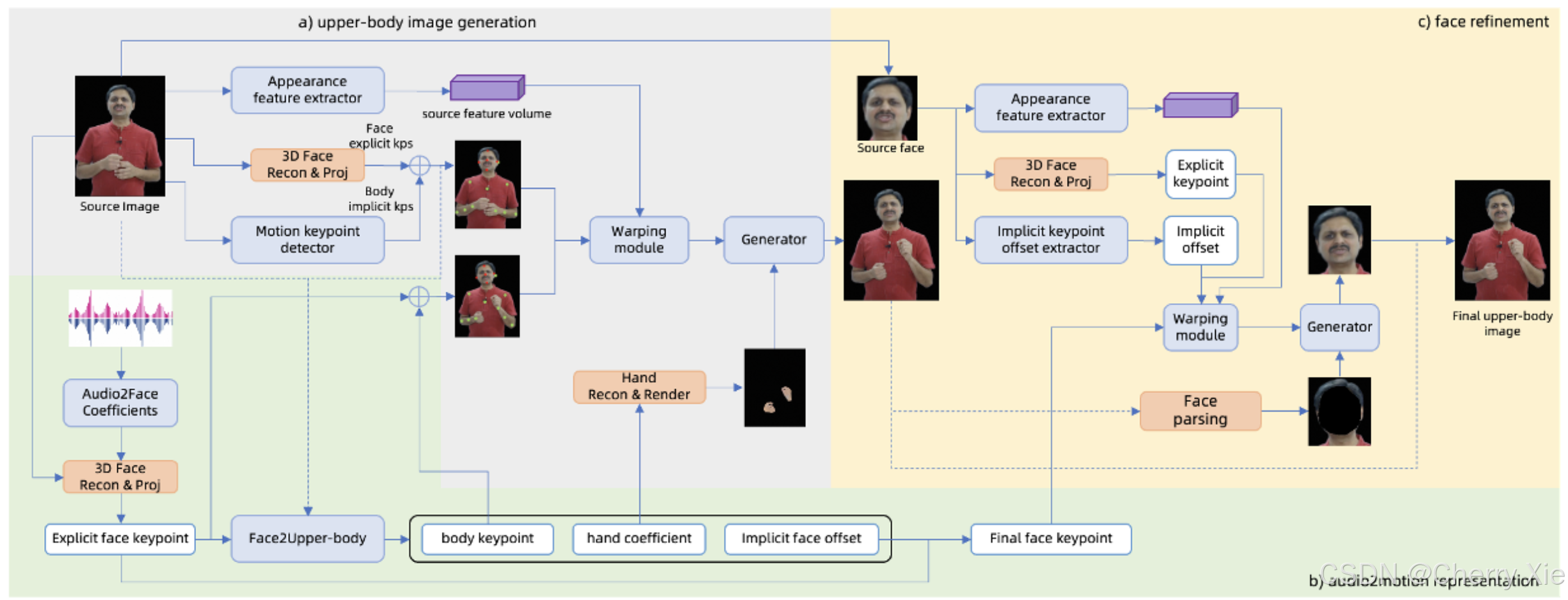
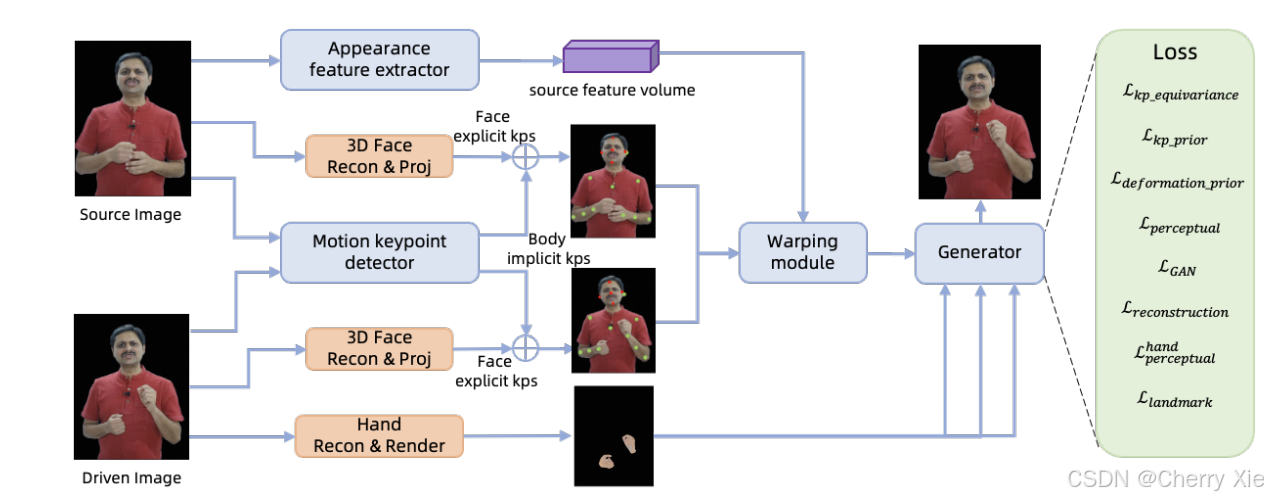
ChatAnyone 的技术架构基于 Hierarchical Motion Diffusion Model(分层运动扩散模型),通过分解视频生成过程,实现高效的实时渲染。以下是其技术架构的详细分析:
核心技术:分层运动扩散模型
-
分层设计:将视频生成分解为多个层次,包括整体姿态、面部表情和手势动作。每个层次使用独立的扩散模型进行生成,减少了计算复杂度,同时提升了生成效果的自然度。
-
运动建模:通过分层模型,分别处理不同层次的运动(如头部、手部、身体),确保生成的视频具有流畅的动作和自然的过渡。
-
扩散模型:利用扩散模型(Diffusion Models)的强大生成能力,结合条件控制(如音频输入)实现音频驱动的视频生成。
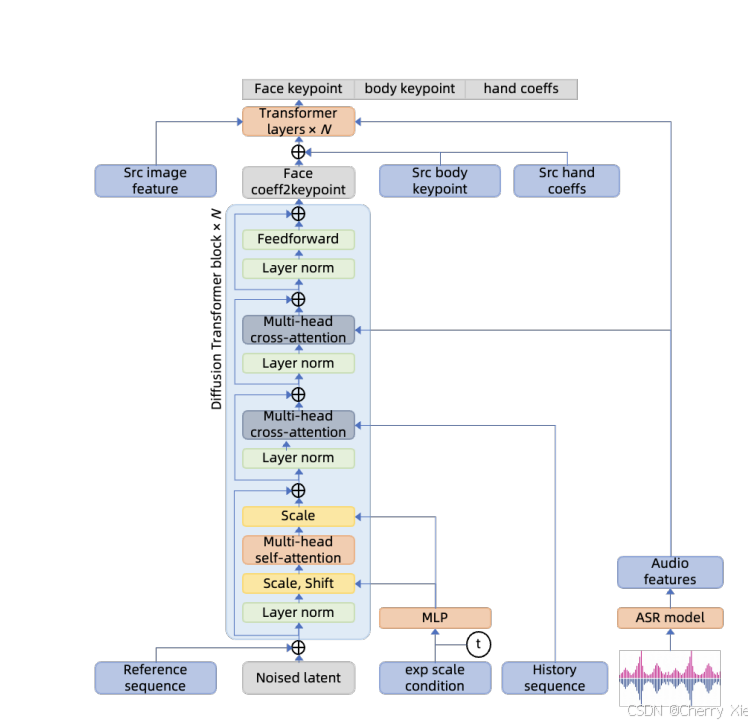
音频处理与驱动
-
语音特征提取:从输入音频中提取语音特征(如梅尔频谱),用于驱动唇部动作和面部表情。
-
口型同步:通过音频特征控制唇部运动,确保生成的视频与音频同步。
-
表情生成:结合音频情感信息,生成自然的表情变化,增强视频的真实感。
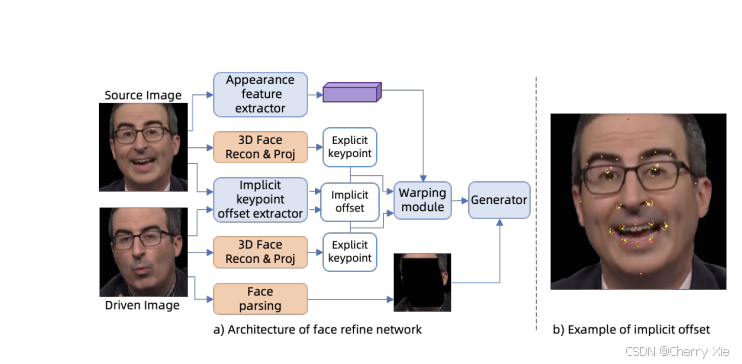
图像生成与风格化
-
肖像生成:从单张照片生成动态肖像,支持风格化输出(如卡通风格)。
-
分辨率支持:最高支持 512×768 的分辨率,适用于高清视频输出。
实时性能优化
-
硬件加速:项目在 RTX 4090 上实现 30fps 的实时生成,依赖 GPU 加速。
-
模型优化:通过分层设计和高效的扩散模型,减少了计算延迟,支持实时应用。

性能对比
详见技术报告
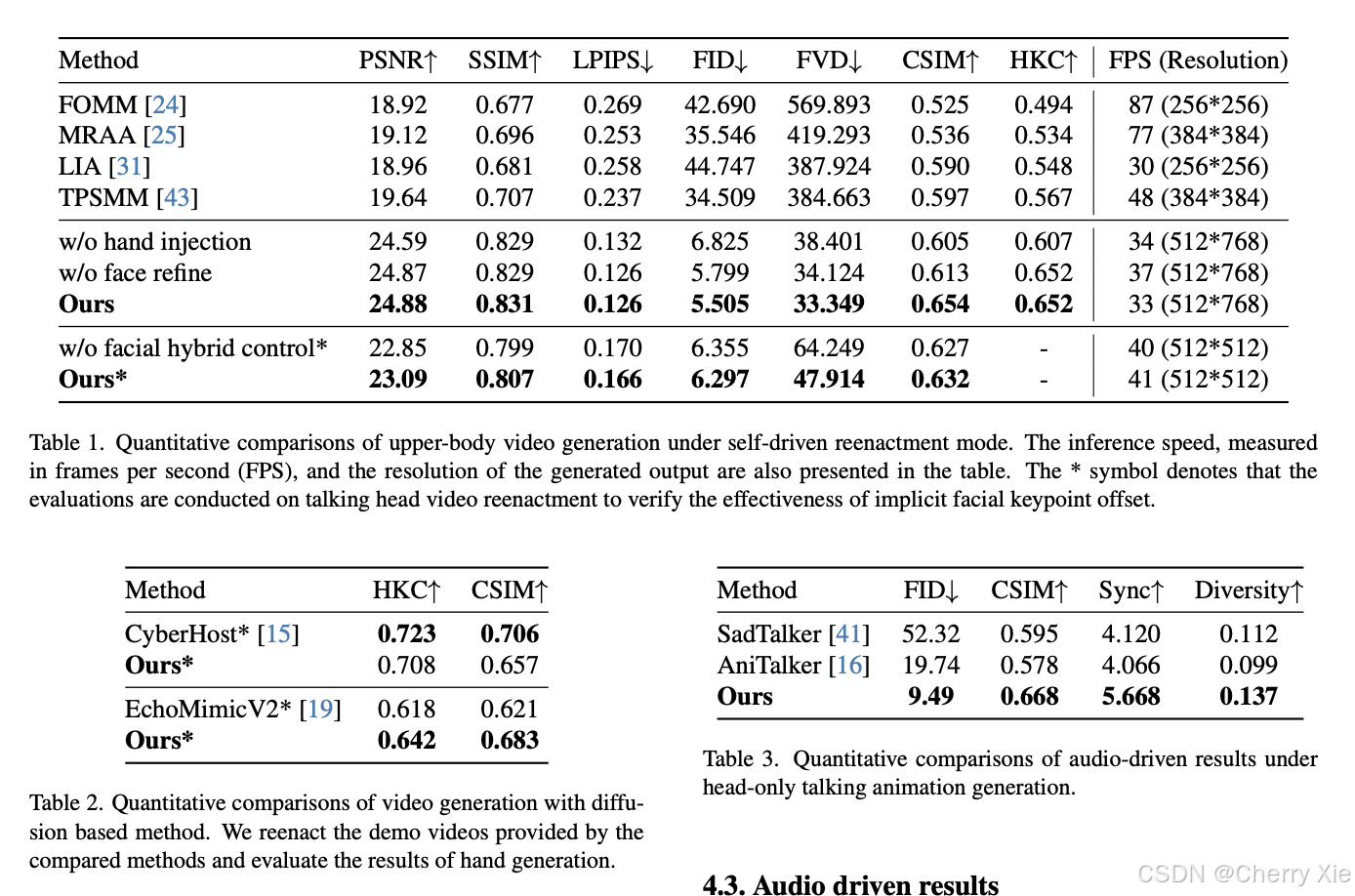
看看效果
相关文献
官方地址:https://humanaigc.github.io/chat-anyone/
技术报告:https://arxiv.org/pdf/2503.21144