【大模型】RAG(Retrieval-Augmented Generation)检索增强生成
RAG 是 Retrieval-Augmented Generation(检索增强生成) 的缩写,是一种结合 信息检索(Retrieval) 和 生成式 AI(如大语言模型) 的技术架构。它是目前最主流也最实用的 “大模型 + 企业知识”结合方式。
📚 RAG 是什么?一句话定义:
RAG 是让大模型“带上资料”再回答问题的一种方法。
传统大模型是“闭卷考试”(只靠预训练记忆),而 RAG 是“开卷考试”:
→ 在生成回答前先去知识库里查找资料(检索) → 然后参考这些资料来生成答案(生成)。
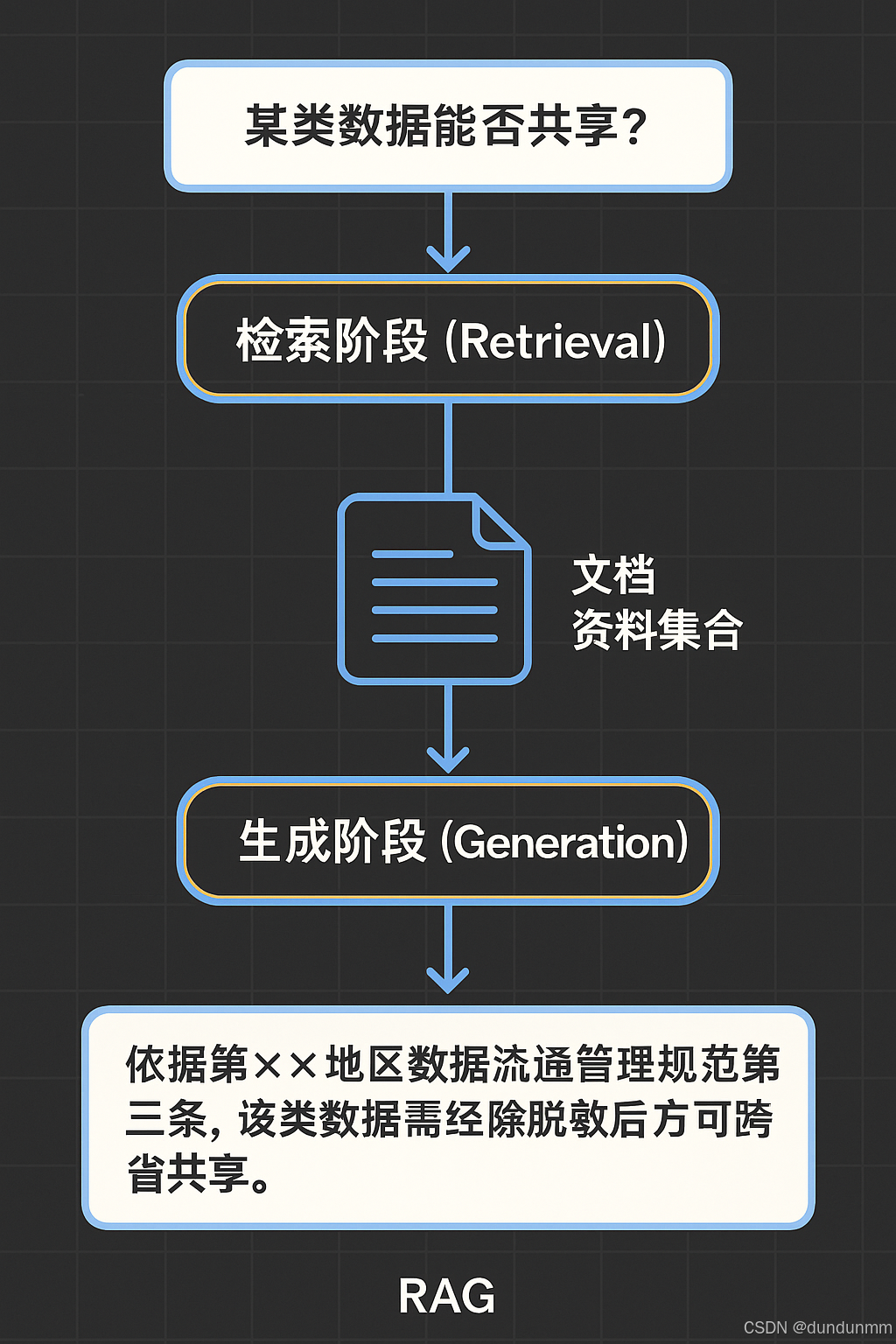
⚙️ RAG 的核心流程(图示理解)
┌───────────────┐│ 用户提问: ││ “某类数据能否共享?” │└───────────────┘↓┌─────────────────────────┐│ 检索阶段(Retrieval) ││ 从知识库/文档中找出相关段落 │└─────────────────────────┘↓┌────────────────────────────┐│ 生成阶段(Generation) ││ 把资料+问题一起送进大模型 ││ → 生成有出处、有逻辑的答案 │└────────────────────────────┘
🧠 RAG 解决了什么问题?
| 问题 | 传统大模型 | RAG |
|---|---|---|
| 企业/行业知识 | 不了解 | 可以接入 |
| 内容时效性 | 有滞后 | 动态更新 |
| 回答可追溯 | 无法溯源 | 可展示出处 |
| 合规/安全性 | 不可控 | 可控知识范围 |
🔍 举个例子:企业数据平台中的应用
用户问题:
“某类数据可以跨省共享吗?”
如果用传统大模型:
模型可能凭记忆回答,不一定符合本地法规。
如果用 RAG:
-
先从数据安全政策库、流通管理办法中找相关文件段落;
-
再把这些内容加到 prompt 里,一起喂给模型生成;
-
模型回答:“依据《××地区数据流通管理规范》第三条,该类数据需经过脱敏后方可跨省共享。”
🧩 技术组件简要:
| 模块 | 工具推荐 |
|---|---|
| 文本向量化 | OpenAI Embedding、BGE、Sentence-BERT |
| 文档管理 | 本地文档、数据库、Notion、WIKI 等 |
| 向量数据库 | FAISS、Qdrant、Pinecone |
| 检索框架 | LangChain、LlamaIndex、Haystack |
| 大语言模型 | GPT-4、Claude、Mistral、Gemini 等 |
✅ RAG 在数据要素平台中的价值
| 场景 | 应用 |
|---|---|
| 数据共享平台 | 政策/数据/标准的智能问答 |
| 安全管理平台 | 合规判断、脱敏规则推荐 |
| 数据市场 | 数据说明书自动解读 |
| 数据目录 | 自然语言搜索 + 结果溯源 |
🎯 总结一句话:
RAG 是让大模型看懂你企业内的资料,并用它来帮你回答问题、做决策。