Pandas的应用
目录
- 一、导入库
- 二、Series对象
- 2.1 创建Series对象
- 2.2 索引
- 2.2.1 普通索引
- 2.2.2 切片索引
- 2.2.3 花式索引和布尔索引
- 2.3 获取Series对象的属性,以及一些统计方法
- 2.4 数据处理
- 2.4.1 处理空值
- 2.4.2 去重
- 2.4.3 使用map函数和apply函数对Series对象的数据进行映射
- (1)map函数
- (2)apply函数
- 三、DataFrame对象
- 3.1 三种方式创建DataFrame对象
- 3.2 DataFrame的相关操作
- 3.3 数据清洗/数据预处理
- 3.4 数据透视
- 3.4.1 基本的挖掘信息的方法,如求平均找最大值等
- 3.4.2 数据聚合
- 3.4.2.1 数据分组聚合
- 3.4.2.2 透视表
- 3.4.3 计算月环比
- 3.4.4 滑动窗口
- 3.4.5 判断两个变量的相关性
一、导入库
import pandas as pd
二、Series对象
pandas中的series、numpy中的array、python中的list,这三者类似,都可以用来表示一维数组。
2.1 创建Series对象
# pandas中的series对象,data参数表示数据,index参数表示数据对应的标签
ser1 = pd.Series(data=[120, 2, 3, 4], index=['一季度', '二季度', '三季度', '四季度'])
print(ser1)# 也可以通过字典创建series对象,键就是数据的标签,值就是数据
ser2 = pd.Series({'一季度':120, '二季度':2, '三季度':3, '四季度':4})
print(ser2)
2.2 索引
2.2.1 普通索引
# 普通索引
print('普通索引')
ser1 = pd.Series(data=[100, 200, 300, 400], index=['一季度', '二季度', '三季度', '四季度'])
print(ser1[0]) # 通过位置索引
print(ser1['一季度']) # 通过标签索引
print()ser1[0] = 230
print(ser1[0])
ser1['一季度'] = 560
print(ser1[0])
print()
2.2.2 切片索引
# 切片索引
print('切片索引')
print(ser1)
ser2 = ser1[1:3] # 使用位置切
print(ser2)
ser3 = ser1['一季度':'二季度'] # 使用数据标签切
print(ser3)
print()# 对切片赋值
ser1[1:3] = 400, 500 # 位置范围上的值更改
print(ser1)
ser1['一季度':'三季度'] = [1, 2, 3] # 标签范围上的值更改
print(ser1)
print()
2.2.3 花式索引和布尔索引
# 花式索引
print('花式索引')
print(ser1)
# 对指定数据的值更改
ser1[['一季度','三季度']] = 999, 111
print(ser1)# 布尔索引
ser4 = ser1[ser1>200]
print(ser4)
2.3 获取Series对象的属性,以及一些统计方法
ser1 = pd.Series(index=['一季度','二季度','三季度', '四季度'], data=[1, 2, 3, 2])
print(ser1)
print()# Series对象的属性
print(ser1.dtype) # 数据类型
print(ser1.hasnans) # 有没有空值
print(ser1.index) # 索引
print(ser1.values) # 值
print(ser1.is_unique) # 每个值是否独一无二
print()# 统计相关
print(ser1.count()) # 计数
print(ser1.sum()) # 求和
print(ser1.mean()) # 求平均
print(ser1.median()) # 找中位数
print(ser1.max()) # 找最大
print(ser1.min()) # 找最小
print(ser1.std()) # 求标准差
print(ser1.var()) # 求方差
print(ser1.mode()) # 求众数2.4 数据处理
2.4.1 处理空值
# 使用np.nan表示空值 (在python中, nan属于小数类型)
ser1 = pd.Series(data=[10, 20, np.nan, 30, np.nan])
print(ser1, end='\n\n')# 删除空值
ser2 = ser1.dropna()
print(ser2, end='\n\n')# 填充空值
ser3 = ser1.fillna(value=40) # 把空值填充成40
print(ser3)
2.4.2 去重
ser1 = pd.Series(data=['apple', 'banana', 'apple', 'pitaya', 'apple', 'pitaya', 'durian'])
# 统计每个元素的出现次数
print(ser1.value_counts(), end='\n\n')
# unique函数去重
ser2 = ser1.unique()
print(ser2)
# drop_duplicates函数去重
ser3 = ser1.drop_duplicates()
print(ser3)
2.4.3 使用map函数和apply函数对Series对象的数据进行映射
(1)map函数
# 使用map函数完成值的映射
ser1 = pd.Series(['cat', 'dog', np.nan, 'rabbit'])
print(ser1)# 值的映射
ser2 = ser1.map({'cat':'kitten', 'dog':'puppy'})
print(ser2)# 将指定字符串的format方法作用到Series对象的数据上, 并忽略空值
ser3 = ser1.map('I am a {}'.format, na_action='ignore')
print(ser3)
(2)apply函数
# 使用apply函数
ser1 = pd.Series(data=[20, 21, 12], index=['London', 'New York', 'Helsinki'])
print(ser1)# 使用apply函数,将平方函数作用的到数据上
ser2 = ser1.apply(np.square) #也可以用lambda函数ser2 = ser1.apply(lambda x : x ** 2)
print(ser2)# lambda函数的x就是Series中的数据,value是第二个参数args传入的
ser3 = ser1.apply(lambda x, value: x - value, args=(5, ))
print(ser3)
三、DataFrame对象
pandas中的DataFrame对象,类似numpy中的二维数组。
3.1 三种方式创建DataFrame对象
# 1.使用numpy的二维数组创建df对象, 每个一维数组代表一行
scores = np.random.randint(60, 101, (5, 3))
courses = ['语文', '数学', '英语']
stu_ids = np.arange(1001, 1006)
df1 = pd.DataFrame(data=scores, columns=courses, index=stu_ids)
print(df1)# 2.使用字典创建df对象
scores1 = {'语文' : [1, 2, 3, 4, 5],'数学' : [1, 2, 3, 4, 5],'英语' : [1, 2, 3, 4, 5]
}
stu_ids1 = [1, 2, 3, 4, 5]
df2 = pd.DataFrame(data=scores1, index=stu_ids1)
print(df2)# 3.读取csv文件创建df对象
df3 = pd.read_csv('data/2018年北京积分落户数据.csv', index_col='id') # index_col参数是将id这一列变成行索引,而不再作为普通的数据列
print(df3)
3.2 DataFrame的相关操作
# 读取csv文件创建df对象
df1 = pd.read_csv('data/2018年北京积分落户数据.csv', index_col='id') # 1.df的属性
df1.head() # 获取df的前五行
df1.tail() # 获取df的后五行# 2.获取df的某一列,不带loc
print(df1['name']) # 获取了一个Series对象# 3.获取df的某一行, 带loc,用id(index)获取
print(df1.loc[2056]) # 也是获取了一个Series对象# 4.获取多个列
print(df1[['name', 'company']])# 5.获取多个行
print(df1.loc[[2056, 2360, 3344]])# 6.对df切片
print(df1.loc[1:10])# 7.修改df某个单元格的数据,要同时指定行和列,只改df对应单元格的值但不改csv的
df1.loc[2347, 'name'] = '未来的'
print(df1.loc[2347])# 8.数据筛选,用到的是布尔索引
df2 = df1.loc[df1.score > 119]
print(df2)
# 也可以组合多个条件进行数据筛选
df3 = df1.loc[(df1.score>118) & (df1.company == '北京航天数据股份有限公司')]
print(df3)
# 数据筛选也可以用query方法,更好
df4 = df1.query('score > 118 and company == \'北京航天数据股份有限公司\'')
print(df4)# 9.拼接df
# 拼接多个df(上下拼接,或者直接对齐index左右拼接)
df5 = pd.concat([df2, df3])
print(df5)
# 拼接df(根据某列的值进行关联合并,类似SQL join)
# df = pd.merge(df1, df2, on='id', how='inner')
3.3 数据清洗/数据预处理
df = pd.DataFrame(data=np.array([[1,2,np.nan,3],[np.nan,7,8,9]]), columns=['w','l','d','e'], index=np.arange(1, 3))# 一、处理缺失值:如果原表(excel表或sql表)的某单元格为空或为nan,读取成df时就会显示成NaN
# 找出缺失值/空值
df.isna()
# 删除缺失值
df.dropna()
# 填充缺失值
df.fillna(value=0)# 二、处理重复值
# 去重
df.drop_duplicates('w') # 'w'列如果有重复元素就去掉后面出现的重复的# 三、处理异常值
# 1.Z-score方法检测异常值
def detect_outliers_zscore(data, threshold=3):avg_value = np.mean(data)std_value = np.std(data)z_score = np.abs((data - avg_value) / std_value)return data[z_score > threshold]
# 2.IQR方法检测异常值
def detect_outliers_zscore(data, threshold=3):avg_value = np.mean(data)std_value = np.std(data)z_score = np.abs((data - avg_value) / std_value)return data[z_score > threshold]# 四、处理日期时间类型的数据
sales_df = pd.read_excel('data/2020年销售数据.xlsx', usecols=['销售日期', '销售区域', '销售渠道', '品牌', '售价'])# 查看每一列的数据类型
print(sales_df.info())
# 第一列是日期时间类型datetime64,进行拆解
sales_df['月份'] = sales_df['销售日期'].dt.month
sales_df['季度'] = sales_df['销售日期'].dt.quarter
sales_df['星期'] = sales_df['销售日期'].dt.weekday
print(sales_df)
print(sales_df.info())# 五、处理字符串类型的数据
jobs_df = pd.read_csv('data/某招聘网站招聘数据.csv', index_col='no')
print(jobs_df.info())
# 筛选出岗位是数据分析的
jobs_df = jobs_df[jobs_df.positionName.str.contains('数据分析')]
print(jobs_df.shape) # 有1515个数据分析的岗位
# 获取所有数据分析岗位的平均薪资->获取salary列的最低薪资和最高薪资,得到新的df
sal_temp_df = jobs_df.salary.str.extract(r'(\d+)[kK]?-(\d+)[kK]')
# 此时新df的每一个单元格都是string,转成int后才能求mean
sal_temp_df = sal_temp_df.applymap(int)
print(sal_temp_df)
# 求均值mean(axis=1代表对每一行求均值,代表该岗位的平均薪资。axis=0代表对每一列求均值,得到的是min那一列的均值和max那一列的均值)
jobs_df['salary'] = sal_temp_df.apply(np.mean, axis=1)
print(jobs_df)# 六、将字符串这种非数值类型数据处理成数值
persons_df = pd.DataFrame(data={'姓名': ['关羽', '张飞', '赵云', '马超', '黄忠'],'职业': ['医生', '医生', '程序员', '画家', '教师'],'学历': ['研究生', '大专', '研究生', '高中', '本科']}
)
# 1.使用独热编码将df中的字符串处理成哑变量矩阵
print(pd.get_dummies(persons_df['职业']))# 2.使用映射将字符串map成不同的数值
def handle_education(x):edu_dict = {'高中': 1, '大专': 3, '本科': 5, '研究生': 10}return edu_dict[x]print(persons_df['学历'].apply(handle_education))# 七、数据离散化
# 离散化指的是将连续的数据划分成有限个区间或类别(也就是把连续的数据扔到几个箱子里)
# 取值有限的就是离散型数据(比如性别),取值无限的就是连续型数据(比如身高)
luohu_df = pd.read_csv('data/2018年北京积分落户数据.csv', index_col='id')
print(luohu_df.score.describe()) # score这一列的最小值是90.75,最大值是122.59
# 数据范围90.75~122.59,那么可以将箱子范围设成90~125,每5分为1组,总共7个箱子
bins = np.arange(90, 126, 5)
print(bins)
# 将score离散化
luohu_df['score'] = pd.cut(luohu_df.score, bins, right=False) # right为False代表左闭右开
print(luohu_df)
3.4 数据透视
数据透视就是从数据中解读出有价值的信息,比如求平均数方差,比如在数据上做统计图。
3.4.1 基本的挖掘信息的方法,如求平均找最大值等
scores = np.random.randint(1, 10, (5, 3))
df = pd.DataFrame(data=scores, columns=['语文', '数学', '英语'], index=['关羽', '张飞', '赵云', '马超', '黄忠'])
print(df)# 求每门课程的平均分
print(df.mean())
# 求每个学生的平均分
print(df.mean(axis=1))
# 求每门课程的方差
print(df.var()) # 方差越大成绩越分散,越小成绩越集中
# 打印df的描述信息
print(df.describe())
# 对数据进行排序
print(df.sort_values(by='语文', ascending=False))
# 找出Top-N的数据(找出语文成绩的前三名)
print(df.nlargest(3, '语文'))
# 找出Top-N的数据(找出数学成绩的后三名)
print(df.nsmallest(3, '数学'))
3.4.2 数据聚合
数据聚合是指 将多个数据点通过某种方式合并成一个值,可以使用聚合函数sum/max/min/mean/count等。
3.4.2.1 数据分组聚合
数据分组聚合:属于数据聚合,分组体现在groupby函数上,聚合指的是使用聚合函数,agg是调用多个聚合函数时用到的。
例子:
sales_df = pd.read_excel('data/2020年销售数据.xlsx')
print(sales_df.head())# 1.统计每个区域的销售总额
sales_df['销售额'] = sales_df['售价'] * sales_df['销售数量']
print(sales_df.head())
sum1_df = sales_df.groupby('销售区域').销售额.sum()
print(sum1_df) # 2.统计每个月的销售总额
sum2_df = sales_df.groupby(sales_df['销售日期'].dt.month).销售额.sum()
print(sum2_df)# 3.统计每个销售区域每个月的销售总额
sum3_df = sales_df.groupby(['销售区域', sales_df['销售日期'].dt.month]).销售额.sum()
print(sum3_df)# 4.统计每个区域的销售总额以及每个区域单笔金额的最高和最低
df4 = sales_df.groupby('销售区域').销售额.agg(销售总额='sum', 单笔最高='max', 单笔最低='min')
# 不需要给列起别名时也可以写成
# df4 = sales_df.groupby('销售区域').销售额.agg(['sum', 'max', 'min'])
print(df4)# 5.统计每个销售区域销售额的总和以及销售数量的最低值和最高值
df5 = sales_df.groupby('销售区域')[['销售额', '销售数量']].agg({'销售额': 'sum', '销售数量': ['max', 'min']})
print(df5)
3.4.2.2 透视表
透视表也是在做分组聚合,但是比groupby更强大。groupby只能输出窄表,透视表可以是宽表,并且透视表还能处理空值。
# df = sales_df.groupby(['销售区域', sales_df['销售日期'].dt.month]).销售额.sum()
sales_df['月份'] = sales_df['销售日期'].dt.month
df1 = pd.pivot_table(sales_df, index=['销售区域', '月份'], values='销售额', aggfunc='sum')
print(df1)
# df1这个透视表是一个行很多列很少的窄表,可以把它变成宽表
# index是行,columns是列,fill_value会把空值填充成0
df2 = pd.pivot_table(sales_df, index='销售区域', columns='月份', values='销售额', aggfunc='sum', fill_value=0)
print(df2)# 2.交叉表
# 交叉表是一种特殊的透视表,用series,不需要用到dataframe
sales_area, sales_month, sales_amount = sales_df['销售区域'], sales_df['月份'], sales_df['销售额']
df3 = pd.crosstab(index=sales_area, columns=sales_month, values=sales_amount, aggfunc='sum')
df3 = df3.fillna(0).astype('int')
print(df3)# 做数据透视(分组聚合)后作图呈现
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'FZJKai-Z03S'
df4 = pd.pivot_table(sales_df, index='销售区域', values='销售额', aggfunc='sum')
# 基于df4进行绘制
df4.plot(figsize=(8, 4), kind='bar')
# 设置绘制的参数
plt.xticks(rotation=0)
plt.show()
3.4.3 计算月环比
月环比就是这个月的销售额相比上个月增长多少(可以是正增长也可以是负增长),正增长就是这个月的销售额比上个月增长了,负增长就是这个月的销售额比上个月下降了。
import pandas as pd
sales_df = pd.read_excel('data/2020年销售数据.xlsx')
sales_df['月份'] = sales_df['销售日期'].dt.month
sales_df['销售额'] = sales_df['售价'] * sales_df['销售数量']
# 算出每月的总销售额
result_df = sales_df.pivot_table(index='月份', values='销售额', aggfunc='sum')
result_df.rename(columns={'销售额': '本月销售额'}, inplace=True)
print(result_df)
# 方法一:使用shift函数将本月销售额这一列整体向下移动一个单元格得到一个新的Series
result_df['上月销售额'] = result_df['本月销售额'].shift(1)
print(result_df)
result_df['月环比'] = (result_df['本月销售额'] - result_df['上月销售额']) / result_df['上月销售额']
result_df.style.format(formatter={'上月销售额': '{:.0f}', '月环比': '{:.2%}'},na_rep='------'
)
result_df.drop(columns=['上月销售额', '月环比'], inplace=True)
# 方法二:直接使用dataframe对象的pct_change方法(更简单更常用!)
result_df['月环比'] = result_df.pct_change()
print(result_df)
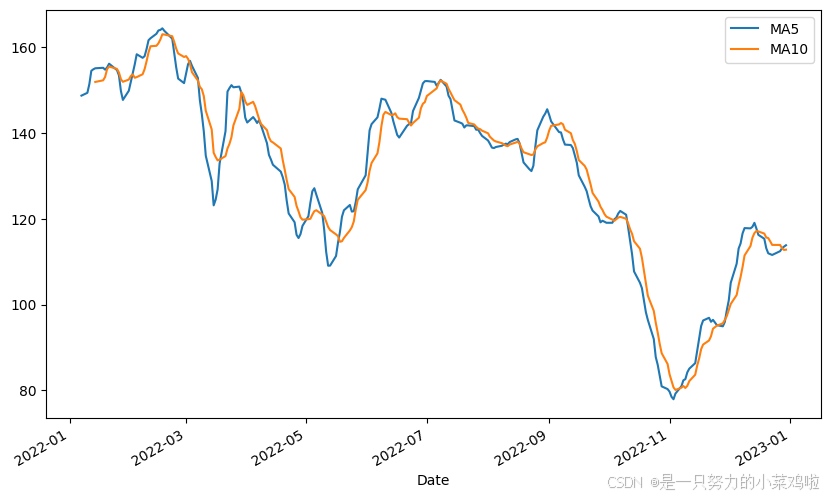
3.4.4 滑动窗口
可以给dataframe或者series设置窗口,然后在窗口内做运算。
例如如下的股票数据示例:在 最近五天的均值上作图 代替 直接在每个点上作图,也可以反应出成交量的趋势。得到的曲线会更加平滑,更容易看出整体趋势。
baidu_df = pd.read_excel('data/2022年股票数据.xlsx', sheet_name='BIDU', index_col='Date') # sheet_name参数指定要读excel文件中的哪个工作表
# 按照日期升序排序
baidu_df.sort_index(inplace=True)
# 分别代表股票的开盘价、最高价、最低价、收盘价和成交量
print(baidu_df)
# 1.给dataframe对象设置滑动窗口,每五行为一个窗口,并求窗口内的均值
df_mean5 = baidu_df.rolling(5).mean()
print(df_mean5)
# 2.给series对象设置滑动窗口
close_mean5 = baidu_df['Close'].rolling(5).mean()
close_mean10 = baidu_df['Close'].rolling(10).mean()
# 将两个series合并成一个dateframe,按照二者的index(Date)进行合并
result_df = pd.merge(close_mean5, close_mean10, left_index=True, right_index=True)
result_df.rename(columns={'Close_x': 'MA5', 'Close_y': 'MA10'}, inplace=True)
print(result_df)
# 将前五日的均值作图
result_df.plot(kind='line', figsize=(10, 6))
plt.show()
3.4.5 判断两个变量的相关性
- 使用 皮尔逊相关系数 rou 判断变量相关性。
- rou>0,两个变量正相关,二者的趋势一致(x变大y也跟着变大)。
- rou<0,两个变量负相关,二者的趋势相反。
- rou约等于0,两个变量不相关,是相互独立的。
- rou的绝对值越接近1相关性越强,越接近0相关性越弱。
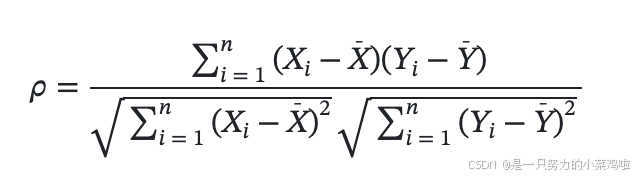
boston_df = pd.read_csv('data/boston_house_price.csv')
print(boston_df)
# 算房价与其他变量的相关性
corr_df = boston_df[['NOX', 'RM', 'PTRATIO', 'LSTAT', 'PRICE']].corr()
# 房价跟RM(房间数)呈正相关(房间数越多房价越高),跟LSTAT(低收入比例)呈负相关(低收入比例越高房价越低)
print(corr_df)