Python实现的智能商品推荐系统分享+核心代码
智能商品推荐系统
项目简介
智能商品推荐系统是一个基于Python、Flask和SQLite开发的电商推荐平台,采用基于用户的协同过滤算法为用户提供个性化的商品推荐。系统通过分析用户的收藏和购物车行为,识别用户偏好,并推荐相似用户喜欢的商品,特别优先推荐与用户已交互商品相同类别的商品。
技术栈
- 后端:Python + Flask
- 数据库:SQLite
- 前端:HTML + CSS + JavaScript
- 推荐算法:基于协同过滤的推荐系统
系统功能
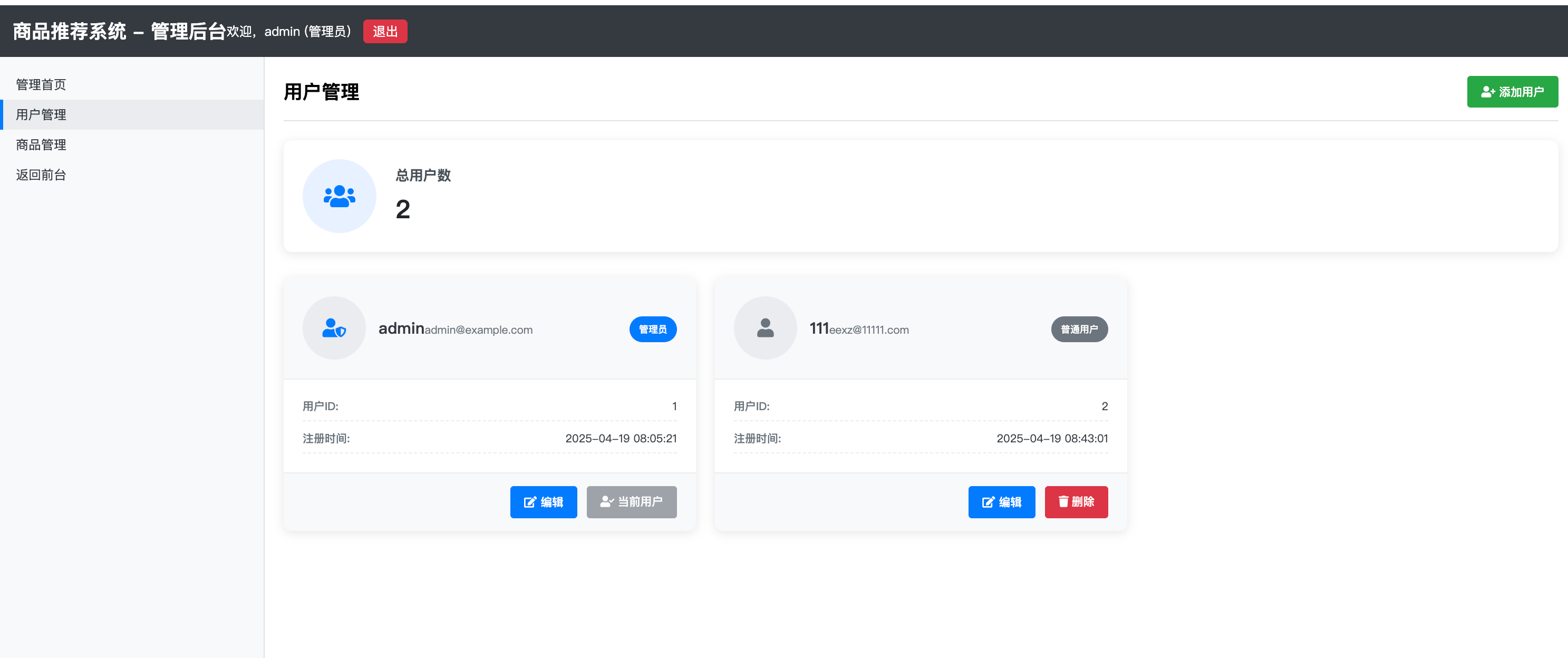
1. 用户管理
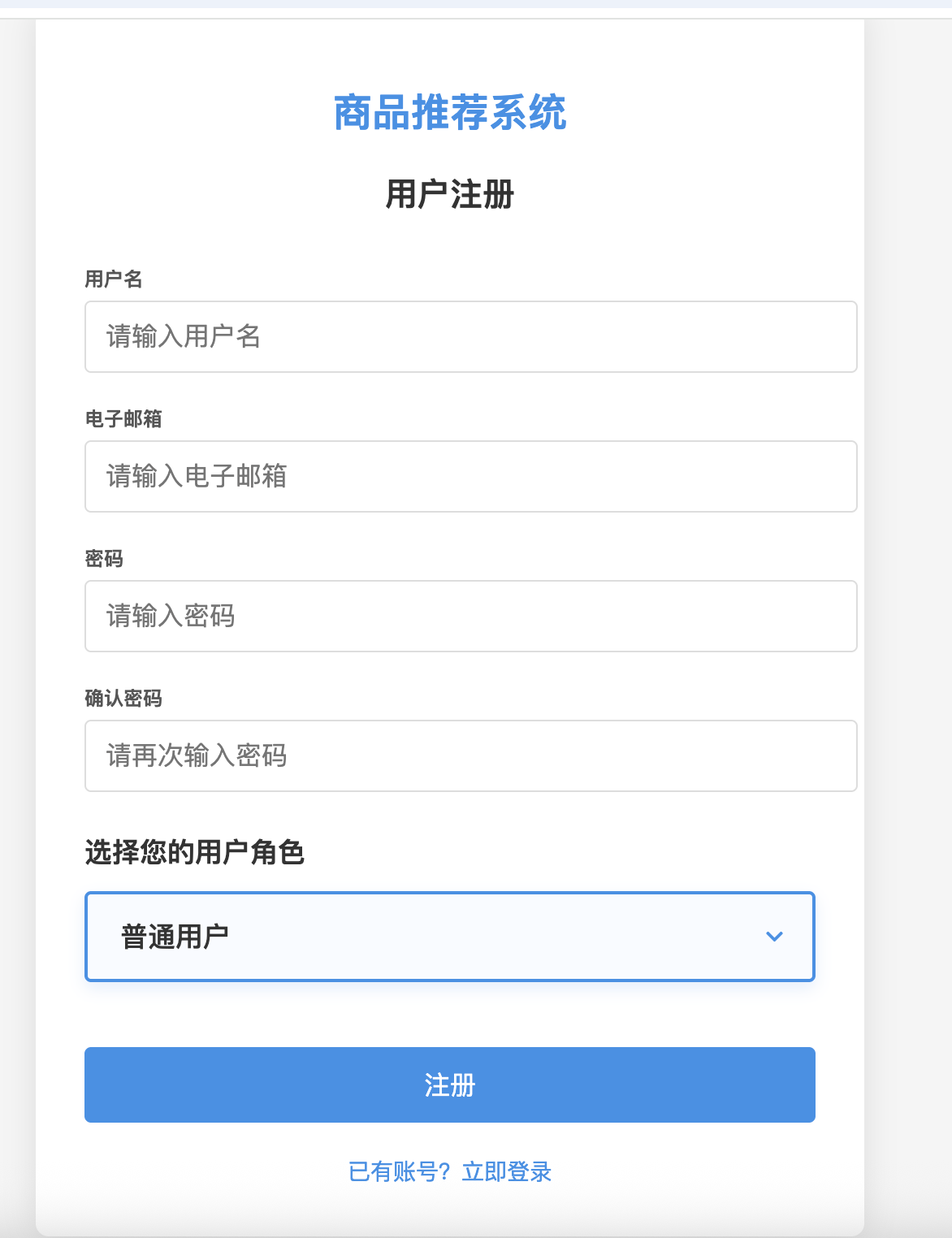
- 用户注册与登录
- 个人信息管理
- 权限控制(普通用户/管理员)
登录页面

注册页面
后台管理页面
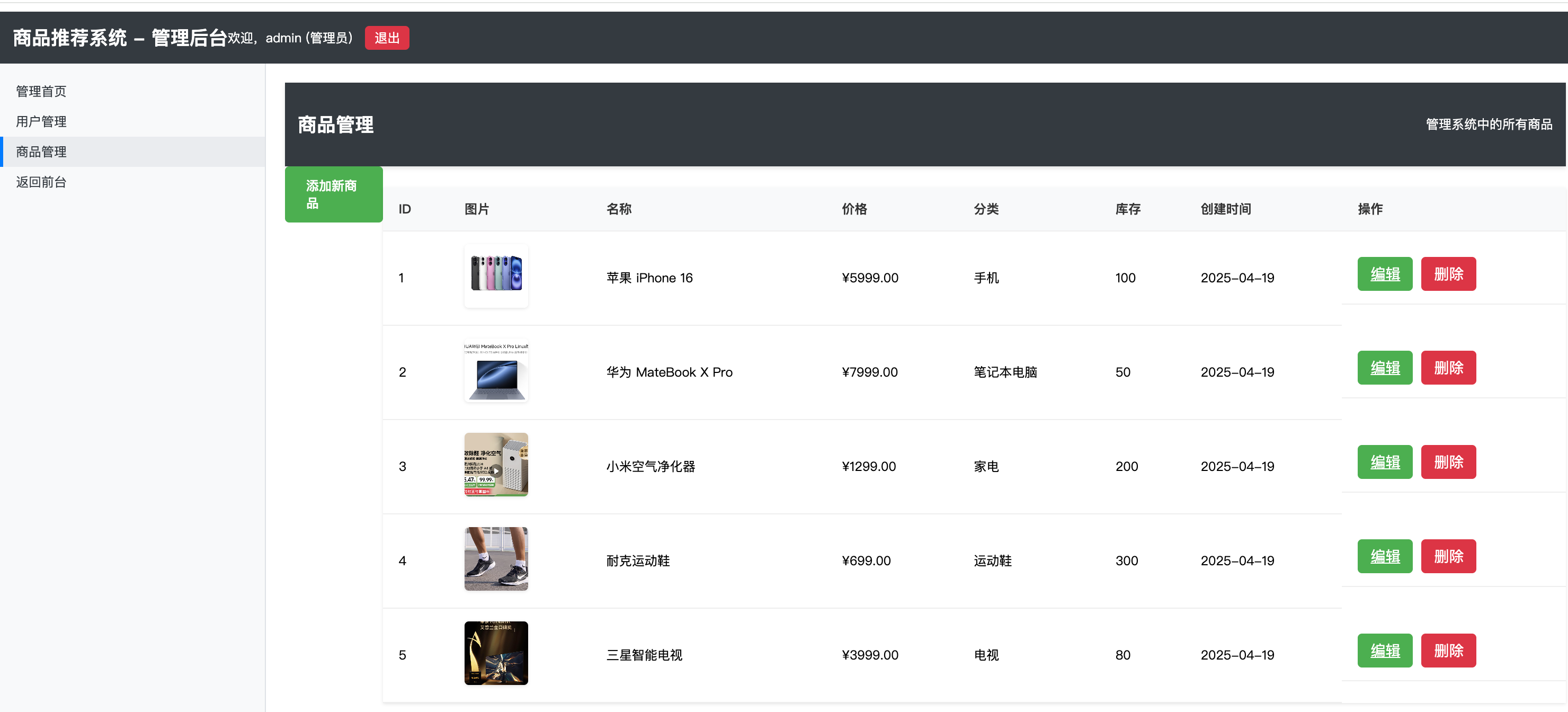
2. 商品管理
- 商品列表展示
- 商品详情页
- 商品分类浏览
- 商品库存管理
商品管理页面
3. 购物车功能
- 添加商品到购物车
- 实时更新购物车数量(无需刷新页面)
- 移除购物车商品(前端处理,同步到后端)
- 购物车商品数量调整
- 购物车总价实时计算
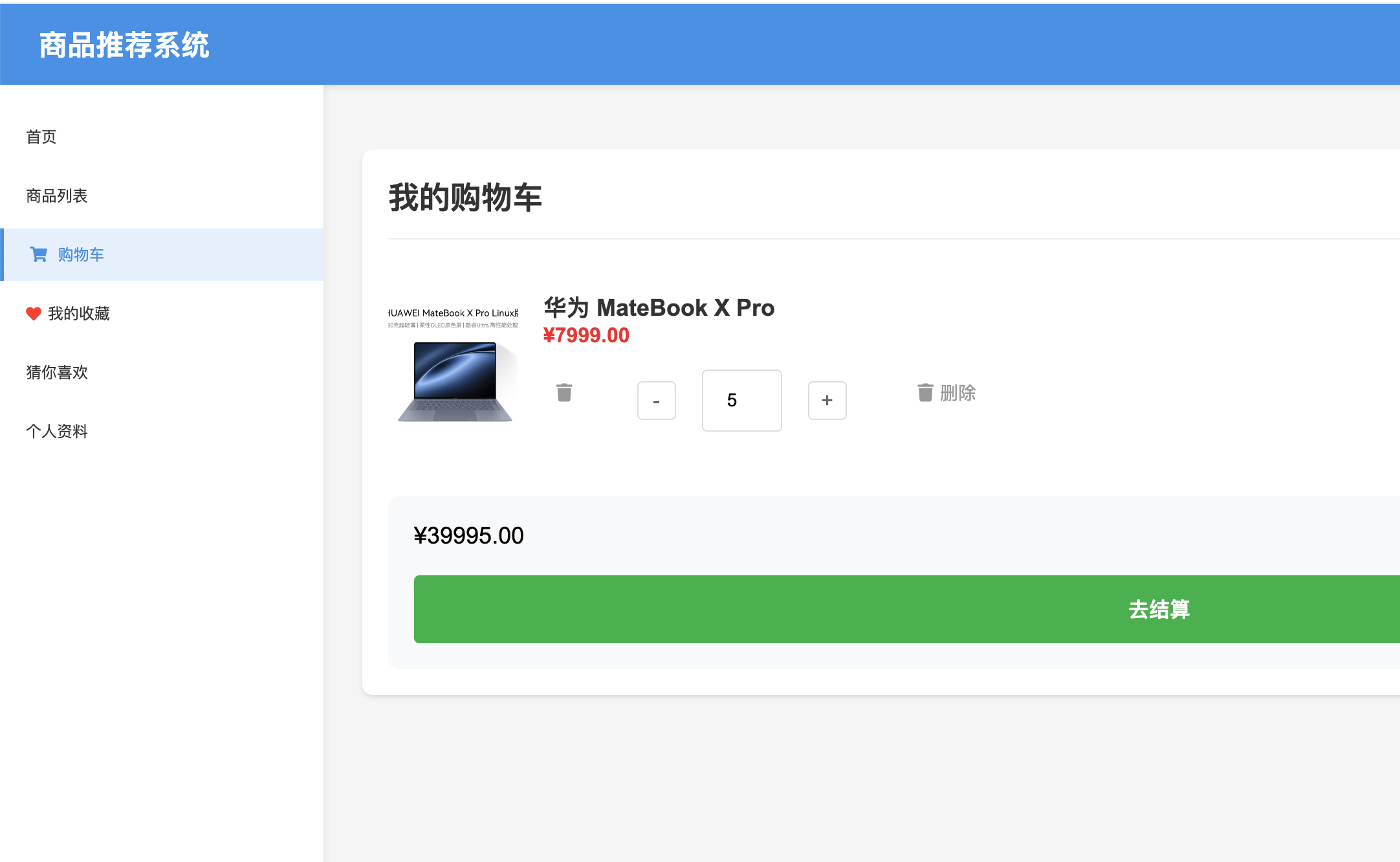
4. 收藏功能
- 商品收藏与取消
- 收藏列表管理
- 批量检查收藏状态(性能优化)
收藏页面

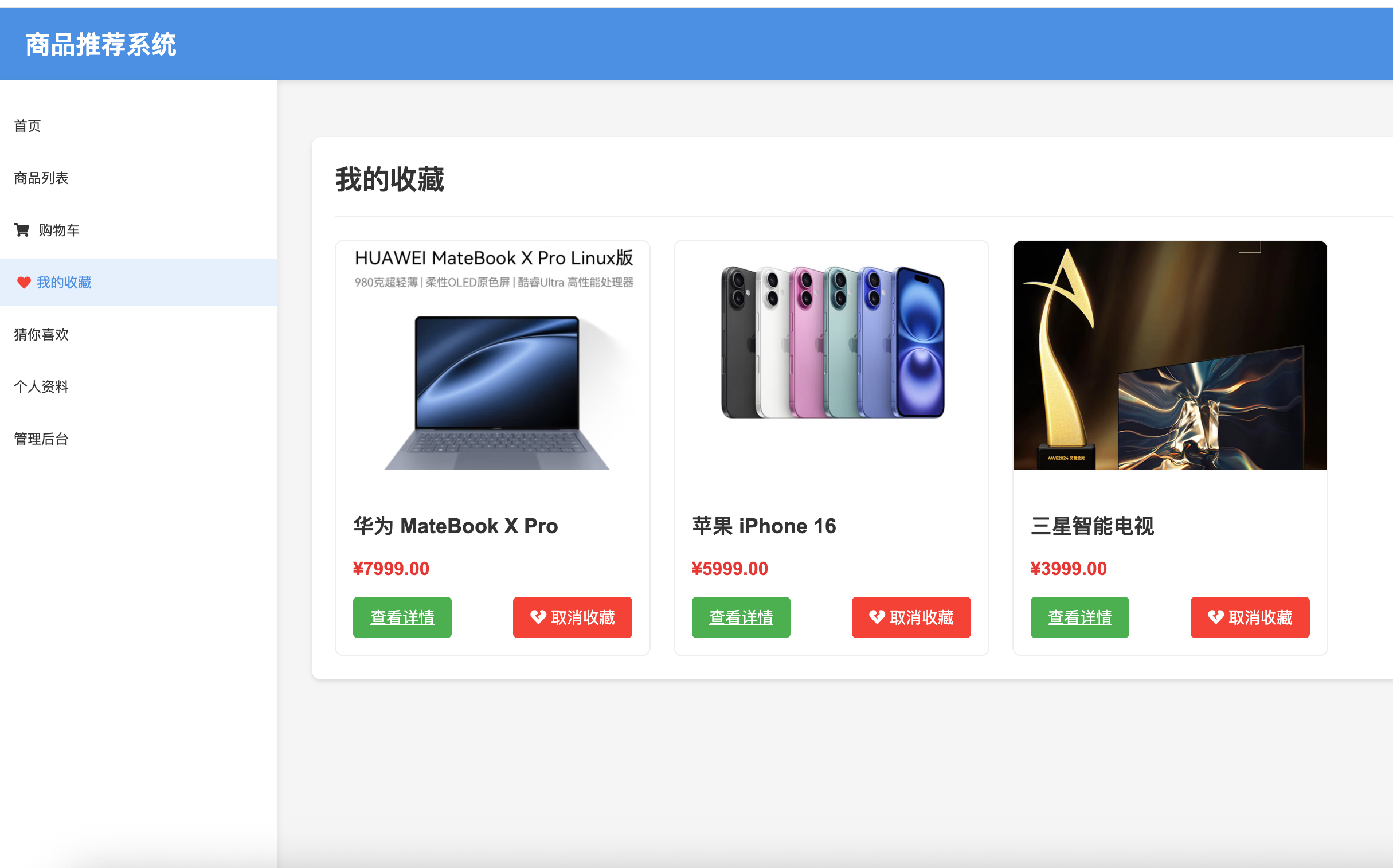
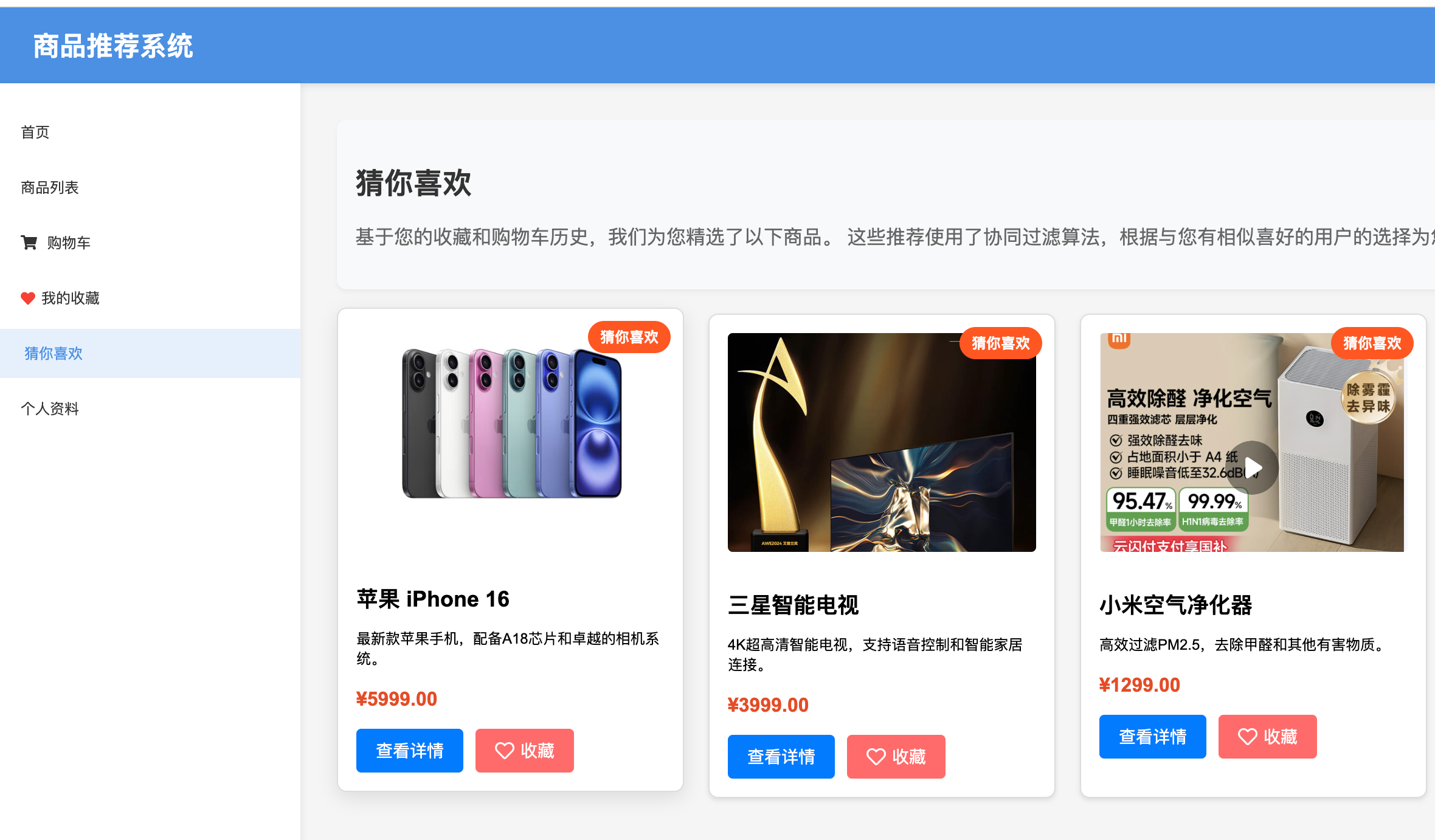
5. 推荐系统
- 基于协同过滤的个性化推荐
- 用户偏好类别识别
- 类别偏好加权(2.5倍权重)
- 热门商品推荐(优先推荐用户偏好类别)
6. 订单管理
- 订单创建与支付
- 订单状态跟踪
- 订单历史查询
- 订单取消功能
推荐算法详解
本系统采用基于用户的协同过滤算法(User-Based Collaborative Filtering)实现商品推荐:
-
用户行为数据收集:
- 购物车行为(权重为2×数量)
- 收藏行为(权重为1+1)
# wx:xiaotankelaoshi # 填充购物车数据(权重为2) cart_items = CartItem.query.all() for item in cart_items:if item.user_id in user_dict and item.product_id in product_dict:user_item_interactions[item.user_id][item.product_id] = 2 * item.quantity # 数量越多,权重越大# 填充收藏数据(权重为1) favorites = Favorite.query.all() for fav in favorites:if fav.user_id in user_dict and fav.product_id in product_dict:# 如果已经在购物车中,则增加权重,否则设为1current_weight = user_item_interactions[fav.user_id].get(fav.product_id, 0)user_item_interactions[fav.user_id][fav.product_id] = max(current_weight, 1) + 1 -
用户相似度计算:
- 使用余弦相似度计算用户之间的相似性
- 考虑共同交互的商品及其评分权重
# wx:xiaotankelaoshi @staticmethod def calculate_similarity(user1_items, user2_items):"""计算两个用户之间的余弦相似度"""# 获取两个用户共同交互的商品common_items = set(user1_items.keys()) & set(user2_items.keys())if not common_items:return 0.0# 计算分子(点积)numerator = sum(user1_items[item] * user2_items[item] for item in common_items)# 计算分母(两个向量的模长乘积)sum1 = sum(user1_items[item] ** 2 for item in user1_items)sum2 = sum(user2_items[item] ** 2 for item in user2_items)denominator = math.sqrt(sum1) * math.sqrt(sum2)if denominator == 0:return 0.0return numerator / denominator -
推荐生成:
- 找出与当前用户相似的其他用户
- 推荐相似用户喜欢但当前用户未交互的商品
- 为与用户已交互商品相同类别的商品增加2.5倍权重
# 获取用户喜欢的商品类别 # wx: xiaotankelaoshi user_preferred_categories = set() for product_id in current_user_items.keys():product = Product.query.get(product_id)if product and product.category:user_preferred_categories.add(product.category)# 计算推荐分数 product_scores = defaultdict(float) for other_user_id, similarity in user_similarities[:10]: # 只考虑前10个最相似的用户other_user_items = user_item_interactions[other_user_id]for product_id, rating in other_user_items.items():if product_id not in user_interacted_items: # 排除用户已交互的商品product = Product.query.get(product_id)category_bonus = 1.0 # 默认权重# 如果商品类别与用户喜欢的类别相同,增加权重if product and product.category and product.category in user_preferred_categories:category_bonus = 2.5 # 类别匹配时的权重提升# 加权评分product_scores[product_id] += similarity * rating * category_bonus -
热门商品补充:
- 当个性化推荐不足时,补充热门商品
- 优先推荐用户偏好类别的热门商品
- 确保推荐结果多样性
@staticmethod def get_popular_products(limit=10, preferred_categories=None):"""获取热门商品"""# 获取热门商品(基于购物车和收藏的总数)popular_products_query = db.session.query(Product,func.count(CartItem.id) + func.count(Favorite.id).label('popularity')).outerjoin(CartItem).outerjoin(Favorite).group_by(Product.id).order_by(func.count(CartItem.id) + func.count(Favorite.id).desc())# 如果有偏好类别,先获取该类别的热门商品preferred_products = []if preferred_categories:preferred_query = popular_products_query.filter(Product.category.in_(preferred_categories)).limit(limit)preferred_products = [product for product, _ in preferred_query.all()]# 如果偏好类别的商品不足,获取其他热门商品remaining_limit = limit - len(preferred_products)if remaining_limit > 0:existing_ids = [p.id for p in preferred_products]other_query = popular_products_queryif preferred_categories:other_query = other_query.filter(~Product.category.in_(preferred_categories))if existing_ids:other_query = other_query.filter(~Product.id.in_(existing_ids))other_query = other_query.limit(remaining_limit)other_products = [product for product, _ in other_query.all()]preferred_products.extend(other_products)return preferred_products
性能优化
系统在多个方面进行了性能优化:
-
批量API调用:
- 实现批量检查收藏状态接口(
/favorite/batch_check) - 将多次HTTP请求合并为一次请求,减少网络开销
- 实现批量检查收藏状态接口(
-
前端无刷新交互:
- 购物车操作完全在前端处理,无需页面刷新
- 保留后端API调用以确保数据持久化
-
静态资源优化:
- 配置静态文件缓存(一年有效期)
- 图片懒加载与错误处理
-
数据库查询优化:
- 使用适当的索引
- 减少不必要的数据库查询
项目结构
recommend-python/
├── app/
│ ├── __init__.py # 应用初始化
│ ├── models/ # 数据模型
│ │ ├── user.py # 用户模型
│ │ ├── product.py # 商品模型
│ │ ├── cart.py # 购物车模型
│ │ ├── favorite.py # 收藏模型
│ │ ├── order.py # 订单模型
│ │ └── recommendation.py # 推荐系统模型
│ ├── routes/ # 路由控制
│ │ ├── auth_routes.py # 认证路由
│ │ ├── product_routes.py # 商品路由
│ │ ├── cart_routes.py # 购物车路由
│ │ ├── favorite_routes.py # 收藏路由
│ │ ├── recommendation_routes.py # 推荐路由
│ │ └── order_routes.py # 订单路由
│ ├── static/ # 静态资源
│ │ ├── css/ # 样式文件
│ │ ├── js/ # JavaScript文件
│ │ └── images/ # 图片资源
│ └── templates/ # HTML模板
│ ├── auth/ # 认证相关模板
│ ├── product/ # 商品相关模板
│ ├── cart/ # 购物车相关模板
│ └── admin/ # 管理员相关模板
├── recommend.db # SQLite数据库
└── run.py # 应用启动脚本
运行说明
- 确保已安装Python 3.6+
- 安装依赖包:
pip install -r requirements.txt - 运行应用:
python run.py - 访问 http://localhost:5000 开始使用
特色亮点
- 无刷新用户体验:购物车和收藏操作无需刷新页面,提供流畅的用户体验
- 类别偏好推荐:优先推荐与用户已交互商品相同类别的商品,使推荐更符合用户期望
- 性能优化:批量API调用、静态资源优化等提高系统响应速度
- 响应式设计:适配不同设备屏幕,提供一致的用户体验
- 实时反馈:操作后提供视觉反馈,增强用户交互体验