运筹学之指派问题(原始匈牙利算法以及KM算法)
1.图论概念review
1.1 无向完全图
无向完全图 : 完全图是一个无向图,其中 每一对不同的顶点之间都恰好有一条边直接相连。即,若图有 n 个顶点,则任意两个顶点间均存在唯一的一条边。边数是 n ( n − 1 ) / 2 n(n-1)/2 n(n−1)/2 .
1.2 完全二分图
完全二分图 :其顶点集 V被严格划分为两个互不相交的子集 X 和 Y,且 X 中的每个顶点与 Y 中的每个顶点均有且仅有一条边相连,但 X 或 Y内部的顶点之间没有边。完全二分图 G m n G_m^n Gmn的m和n分别表示两个子集X和Y的顶点数。边数为 m × n m \times n m×n.
1.3 完美匹配
什么是完美匹配,指代一种能够覆盖图中所有顶点的特殊匹配结构。
二分图场景:在二分图中,若两部分的顶点数量相等,且存在一个匹配集合M(里面元素都是边)同时覆盖两部分的全部顶点,则该匹配称为完美匹配。
1.4 最大匹配
什么是最大匹配,有些情况下做不到完美匹配,只能尽量实现最多的配对,叫最大匹配。
总结,完美匹配一定是最大匹配,而最大匹配不一定是完美匹配。
1.5 顶点全覆盖
顶点全覆盖:图中边的集合,使得每个顶点恰好与一条边相关联,不存在未被覆盖的顶点。
1.6 增广路径
这是图论中用于求解二分图最大匹配问题的核心概念,其定义需满足以下条件:
-
路径结构:连接两个未匹配顶点的路径,且路径上的边交替属于匹配边与非匹配边。
例如,路径形如:未匹配顶点→可匹配边→已匹配边→…→可匹配边→未匹配顶点。如图下所示:

-
长度特性:路径长度为奇数(边数为奇数),其中可选匹配边数量比已匹配边多一条.
1.7 交错路径概念
给定图G的一个匹配集合M(放的元素都是边),如果一条路径的边交替出现在M中和不出现在M中,我们称之为一条M-交错路径。
而如果一条M-交错路径,它的两个端点都不与M中的边关联,我们称这条路径叫做M-增广路径。
举个例子:
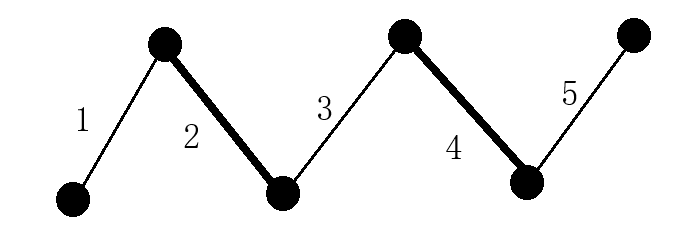
上图有五条边,只有2和4在已匹配集合M里,1、3和5都是可选匹配。
- 已匹配边:2和4
- 可选匹配边:1、3和5
你会发现1、3以及5也可以是一个匹配集合。总体来看1、2、3、4以及5这条路径是匹配集合M的一条交错路径,同时它还满足两个端点不与M中的边所关联。
既然这样就可以从1, 2, 3, 4以及5 这条路径中找到一个更大的匹配,而这个匹配比原先的匹配集合M多一条边,将是一个比原先M更大的匹配集合。
回顾我们的目标,是在确定的已匹配集合下寻找新的增广路径,因为出现一条增广路径,意味目前匹配中增加一条边。
这种复杂问题的求解思路,变成了寻找增广路径。当图中再也没有增广路径了,就意味着我们找到了该图的最大匹配。
我们这里所讨论的匹配,是图论中的任务分配问题,通常是针对于二部图发起的,想想也是,匹配不就是配对么,自然是两两成对了。
2. 历史背景与术语起源
- 原始匈牙利算法:由Kuhn于1955年提出,专门针对无权二分图的最大匹配问题,通过寻找增广路径实现顶点全覆盖。
- 改进版算法(KM算法):Munkres在1957年引入权重处理机制,通过顶标调整与辅助矩阵优化,扩展至带权二分图的最小/最大权重匹配场景,故称为Kuhn-Munkres(KM)算法或Munkres算法
3.原始匈牙利算法
3.1 例解
初始化化一个图,它们的待匹配关系如下:

我们是基于二部图来讨论,上图就是这样的二部图,顶点集合分两类,X集合和Y集合
- X集合:x1,x2,…,x6
- Y集合:y1,y2,…,x7
我们的目标:是 尽可能多 地给X集合找到匹配顶点。注意,最大匹配是互相的,如果X集合能尽量多地匹配到Y集合,反过来,Y集合也不可能有更多地匹配到X集合。那我们开始做分步匹配说明:
step 1:刚开始,已匹配集合M肯定一个点都没有,我们随意选取待匹配集合的一条边,如(x1,y1)这条边,构建最初的匹配结果出来,如下图所示,已匹配的边用粗线标出:

step 2:接着给x2添加匹配,如下图的(x2,y2)边。

目前很顺利,到这里,我们的已匹配集合M,里面已经有(x1,y1)与(x2,y2)两条边。
step 3:然后我们想给x3顶点添加匹配,发现x3有待匹配边3条,按顺序从左到右,其中第一条待匹配边(x3,y1)中的y1已经被step1的x1顶点占用了,那么x3要强抢y1,建立(x3,y1)已匹配关系,那么(x1,y1)的匹配关系消失了,这时候x1另谋出路,发现自己还有另外两条可以匹配的关系,按顺序从左到右,发现(x1,y2),但是y2已经被x2占用了,同样事情发生了,x1强抢y2,x2需要自谋生路,非常好,x2也发现了自己还有一个可以匹配的关系(x2,y5),y5情况是无人占领,非常好,这一步到此结束,很明显这个寻找过程是递归形式。匹配如下所示:

我们把刚才涉及讨论到的顶点都拿出来:(x3,y1,x1,y2,x2,y5),很明显,这是一条路径P。
在step2中,我们已经有匹配集合M,而P呢,就是M的一条增广路径。
前面提过,若发现了一条增广路径,意味着出现了数目更多的匹配关系。于是这里的step3中,我们把M中的配对点拆除,重新组合,得到了一个比step2更大的匹配集合M,里面元素是(x3,y1),(x1,y2),(x2,y5)这三条边。
这就是原始匈牙利算法的核心关键。
依葫芦画瓢,x4,x5按顺序加进来,最终得到本图的最大匹配关系,如下图所示:

另外我们也能发现,如果把y4让给x6,x5会没有匹配关系了,但不影响最大匹配关系。
总结,匈牙利算法就是为了寻找最大匹配,通过不断寻找原有匹配M的增广路径,因为找到一条M匹配的增广路径,意味出现一个更大的匹配M’,恰好比M多一条边。另外我们也发现了,最大匹配不是唯一,但最大匹配的大小却是唯一的。
4.改进的匈牙利算法(KM算法)
求解指派任务中时间最小或者成本最低的问题。
4.1 解法概要
step 1: 变换效率矩阵,使得每行每列至少有一个零
- 行变换:找出每行最小元素,从该行各元素中减去
- 列变换:找出每列最小元素,从该列各元素中减去
step2:找出独立零元素(不在同行同列的零),并用直线覆盖全部零元素
技巧:行有独立划掉列,列有独立划掉行
step3:再变换矩阵来增多独立零元素个数
- 在未划线的元素中找出最小元素
- 未划线的各个元素减去这个最小元素
- 交叉划线的元素均加上这个最小元素
4.2 例解

step 1: 变换效率矩阵,使得每行每列至少有一个零
- 行变换:找出每行最小元素,从该行各元素中减去
- 列变换:找出每列最小元素,从该列各元素中减去

step2:找出独立零元素(不在同行同列的零),并用直线覆盖全部零元素
技巧:行有独立划掉列,列有独立划掉行
- 先看第一行,第一行有独立的零,把零框出来,然后把该列划掉(行有独立划掉列)

这么划的意义是什么?结合例题来解释,就是一项工作只能由一个人来完成,那么这个工作已经指派给了这个人,其他人就不用负责了,所以把这一列划掉。 - 接着看第二行,其中第一列被划掉,故第二行第一列元素不用管,那么只看4,5以及0。接着显然这行有独立零元素,同样做法,把零框出来,然后把该列划掉(行有独立划掉列)。如下所示:

- 然后看第三行,由于前面两步已经把第一列和第四列划掉,那么第三行,只有元素0和0.这属于不是独立零的情况,那么我们就不划了。
- 再看第四行,同样判断做法,只有元素3和6,没有独立零,我们也不划了。
- 现在我们换矩阵的列方向来看,可以看到第二列是有独立零的: [ 1 , 4 , 0 , 5 ] T [1,4,0,5]^T [1,4,0,5]T,按照口诀,把零框出来,列有独立划掉行。可以得到:

说明第二项任务指派了给第三人来完成。 - 第三列已经没有零了,我们回过头来看总体,整个矩阵,只框出3个零出来,但是这是4阶方阵,我们需要四个零,故我们需要进行step3。
step3:再变换矩阵来增多独立零元素个数
- 首先在未划线的元素中找到最小元素。我们结合上面最终得出的矩阵可以看到,最小元素就是1
- 然后在没划线的各个元素 减去 这个最小元素。
- 最后处在交叉划线的元素,要 加上 这个最小元素
我们可以看到,矩阵是长这样的变化,得到了一个新的矩阵 c i j 2 c_{ij}^2 cij2,这将放在step4中求解。

step4:找出独立零元素,再检验

从图上可以看到新的矩阵 c i j 2 c_{ij}^2 cij2,接下来我们接着看看怎么求解:
- 第1,3以及4行没有独立零,只有第2行有独立零,故做法同样,框出独立零,行有独立划掉列,得到:

- 现在从矩阵的列方向看,可以看到第一列有独立零,故做法同样,框出独立零,列有独立划掉行,得到:

- 接着我们看第二列,同样做法,由于第一行元素在上面那一步被划掉,故第二列第一行的元素不用管,那么第二列只剩下 [ 3 , 0 , 2 ] T [3,0,2]^T [3,0,2]T,出现了独立零,老规矩,框出独立零,列有独立划掉行,得到:

- 从上面的矩阵图可以看到,还是只有三个独立零。独立零元素本应该未n阶方阵的n个,故本例还没有达到最优解。
step5:再变换矩阵来增多独立零元素个数
如同step3一样
- 首先在未划线的元素中找到最小元素。我们结合上面最终得出的矩阵可以看到,最小元素就是1
- 然后在没划线的各个元素 减去 这个最小元素。
- 最后处在交叉划线的元素,要 加上 这个最小元素
得到新矩阵 c i j 3 c_{ij}^3 cij3:

step6 :找出独立零元素,再检验
接着上面的新矩阵 c i j 3 c_{ij}^3 cij3,我们继续
-
可以看到矩阵第1,2以及3行都没有独立零,只有第4行,老规矩,框零元素,行有独立划掉列,得到:

-
注意 :刚才上面划掉了第4列,可以发现,第二行这时候出现独立零了(因为第四列全部元素被划掉,包括第二行第四列的零元素),此时第二行元素为[0,2,3],那么老规矩,框零元素,行有独立划掉列,得到:

-
注意 :刚才上面划掉了第1列和第4列,可以发现,第一行这时候出现独立零了,此时第一行元素为[0,1],那么老规矩,框零元素,行有独立划掉列,得到:

-
现在第三行有独立零了,框零元素,行有独立划掉列,可得到:

注意 :其实你说是第三列有独立零也行,做成列有独立划掉行,也是没问题,因为我们已经解决了问题,框出的零已经有四个。
step7:写出结果及答案

4.3 衍生问题
-
1.如果不是求最小值,是求最大值Max如何处理?
这个好说,找出系数矩阵最大值M,然后令系数矩阵变为 m-系数矩阵各元素值,得到新的系数矩阵,再按照求解步骤走就行。 -
2.系数矩阵如果不是方阵,如何处理?
- 任务<人数:增加虚拟任务,虚拟任务对应的系数全部设为0
- 人数<任务:增加虚拟人,虚拟人对应的系数全设为0
-
3.若指定一个人做多个任务呢?
这个也好说,如果一个人可以做k个事情,就把这个人的系数复制k份,相当于增加了虚拟人,如果不是方阵,接着增加虚拟任务。 -
4.若某个人不能做某项工作呢?
这个也好说,把问题转换为求解最小值后,如果第i个人不能做第j项任务,则把系数矩阵的元素 c i j c_{ij} cij设置为一个比系数矩阵中最大值大一些的数。
5.表上作业法与改进版匈牙利算法的区别
| 维度 | 表上作业法 | 改进版匈牙利算法 |
|---|---|---|
| 问题类型 | 运输问题(多对多资源分配) | 指派问题(一对一或一对多匹配) |
| 核心操作 | 表格检验数计算与闭回路调整 | 增广路径搜索与顶标动态调整 |
| 适用数据结构 | 二维供需矩阵 | 二分图或邻接表 |
| 优化目标 | 最小化全局运输成本 | 最大化匹配效率或权值 |
注:两者均为线性规划问题的特例解法,但针对不同场景设计,表上作业法侧重连续变量调运,而改进版匈牙利算法侧重离散匹配优化。
6.参考资料
- https://zhuanlan.zhihu.com/p/572858620
- https://zhuanlan.zhihu.com/p/668517725
- https://www.cnblogs.com/jamespei/p/5555734.html
- https://www.bilibili.com/video/BV1vB4y1X73q