VLLM历次会议(2024.4)
Prefix Caching。预先算好KV cache,遇见公共前缀,复用之,避免再计算一遍。
场景:1. 多轮对话。2.公共的system prompt。
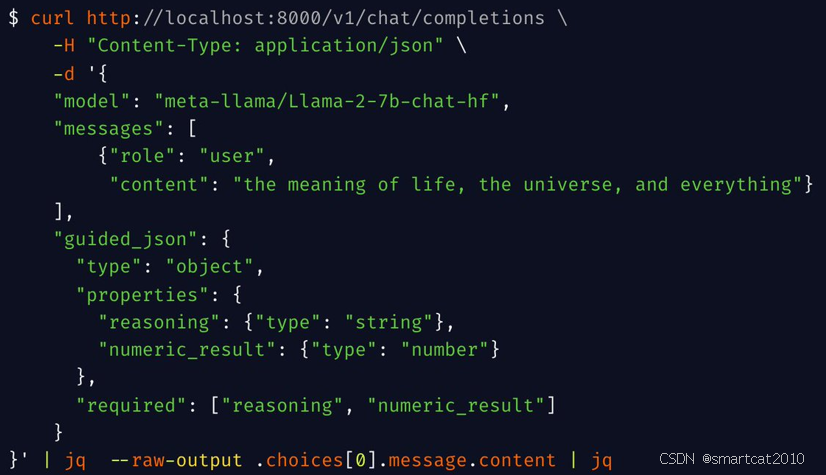
Guided Decoding(格式化输出)
通过Outlines工具实现。
支持正则表达式、JSON格式等。
输入:
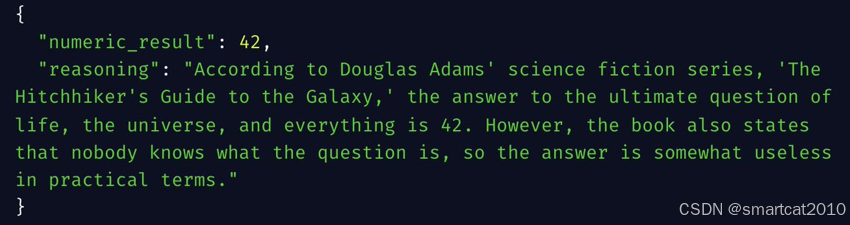
输出:
MoE优化:
●
Triton grouped GEMM kernel with tuned tile sizes
Marlin
增加Marlin Kernel,INT4 quantization时可加速。
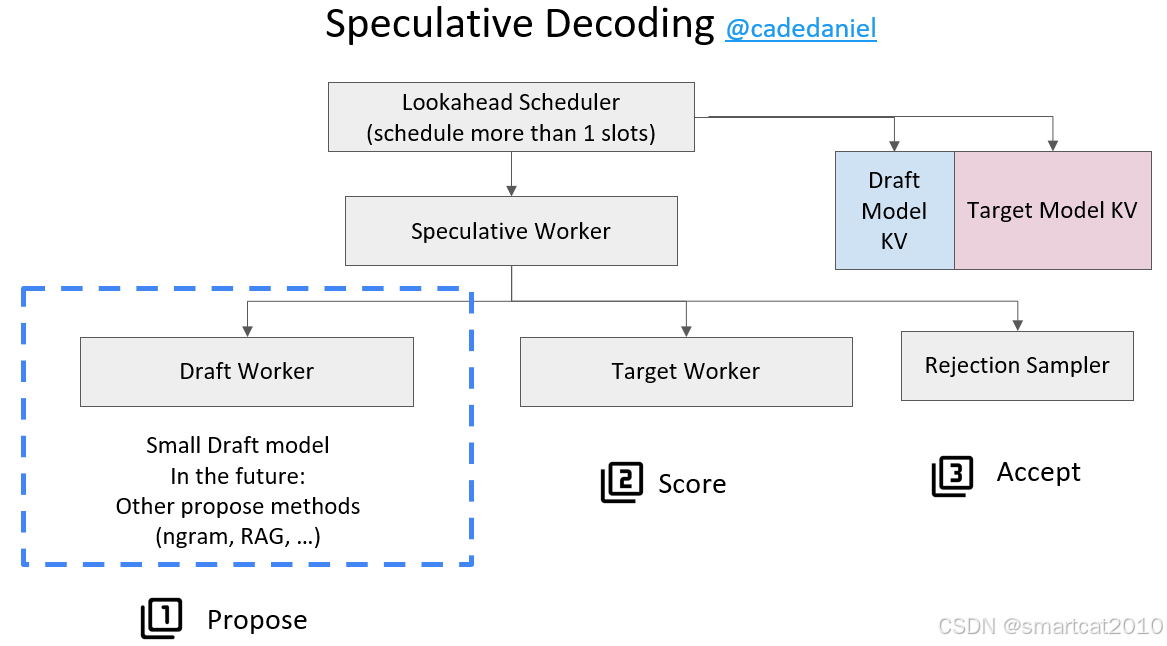
Speculative Decoding
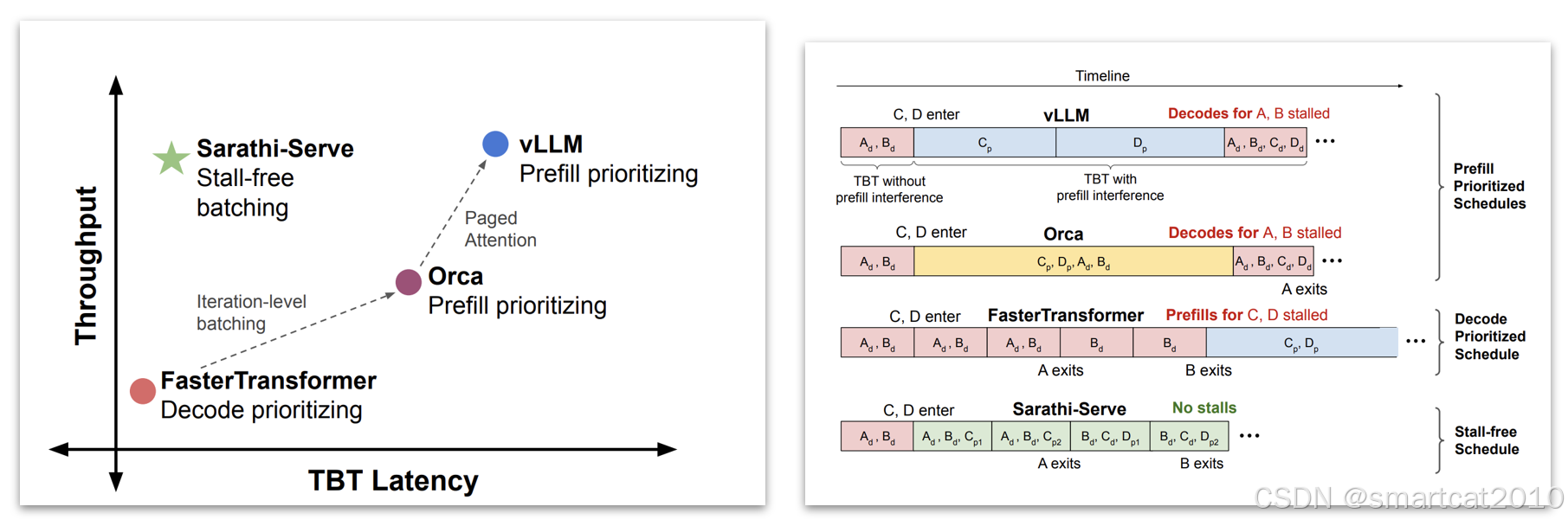
chunked-prefill的好处:
latency可以显著减少。VLLM continous batching是prefill优先。Sarathi-Serve用了chunked-prefill。VLLM后续会做这个。