Flow 笔记
转:https://juejin.cn/post/7476850354796380197
Flow.launchIn()
Flow 有一个拓展函数 Flow.launchIn(),它的原理很简单,就是利用给定的 CoroutineScope 开启一个新协程,然后在这个新协程里面调用 Flow.collect()。
Collect.kt public fun <T> Flow<T>.launchIn(scope: CoroutineScope): Job = scope.launch { collect()
}
生产出来的数据可能会流经各个中间操作符,collect 只是数据的最后一站。launchIn() 一般是配合中间操作符 onEach() 一起使用的:
this.launch {flow.onEach { println(it) }.collect()}// 等同于上面的写法
flow
.onEach { println(it) }
.launchIn(this)
Flow.shareIn()
Flow 有一个拓展函数 Flow.shareIn() 用于将一个 Flow 转换为 SharedFlow:
// Share.kt fun <T> Flow<T>.shareIn(scope: CoroutineScope, // [Where] 指定在哪开启新协程调用 Flow.collect()started: SharingStarted, // [When] 指定什么时候调用 Flow.collect()replay: Int = 0 ): SharedFlow<T>
SharingStarted.Eagerly,Eagerly 是 "急切地、急迫地" 的意思,它会立刻调用上游 Flow 的 collect() 启动其生产流程,并将收集到的每个数据转发给所有收集者。
SharingStarted.Lazily,Lazy是"懒"的意思,不会立马开始启动上游 Flow 的生产流程,直到第一次调用 SharedFlow.collect()。
SharingStarted.WhileSubscribed(),当下游的所有订阅全都结束之后,它会把上游的所有的生产过程也结束掉,而且这时候如果再来新的订阅,它就会重新启动上游的数据流。
SharedFlow 官方文档里面写道:An active collector of a shared flow is calle a subscriber.
意思是普通 Flow 的 collector 称为(数据)收集者,但是 SharedFlow 的 collector 可以被视为订阅者。
SharedFlow 是一种 Hot Flow(热流),而普通的 Flow 是一种 Cold Flow(冷流)。
何谓冷流🥶和热流🥵呢?冷热的概念来源于 Flow 的特性,它们描述了流的行为方式和数据的发出时机。
冷流指的是每次收集(collect)流时,数据生产线会从头开始执行、发出数据。称其为冷流是因为它的行为像是在冷藏的状态下,只有在“激活”它(即调用 collect)时,才开始从头运行并发出数据。
热流指的是流的数据是实时生成并广播给所有观察者的。也就是说,热流的生产者在流创建后就会生产并发射数据,而不管有没有人去收集它,热流的数据生产和消费是独立的。称其为热流是因为它的行为像是一个实时的广播,总是活跃的,像是一个正在加热的设备,不会因是否有人“收听”而改变其状态。
SharedFlow 的 buffer 配合 replay 起到了缓存的作用。其实 buffer 还有另一个作用:在下游来不及消费时缓冲上游的数据。
在生产者-消费者模型中,当生产速度超过消费速度时,系统需要采取措施加以控制,通常的做法是暂停生产或丢弃来不及消费的数据。这种现象在 SharedFlow 中同样存在:当 Subscriber 的处理效率较低时,Buffer 中的数据若无法及时处理,缓冲区总有一刻将被填满。默认情况下,buffer 被填满后数据发射操作会被挂起(onBufferOverflow = SUSPEND)。
suspend fun main(): Unit = coroutineScope { // this: CoroutineScopeflow<Int> {val start = System.currentTimeMillis()(1..100).forEach {emit(it)println("emit $it finished at " +(System.currentTimeMillis() - start).toDuration(DurationUnit.MILLISECONDS).toString())}}.shareIn(scope = this,replay = 1,started = SharingStarted.Eagerly,).collect {delay(3000)}
}
上面的代码里,生产每条数据几乎不耗时,处理每条数据则要花费 3 秒。
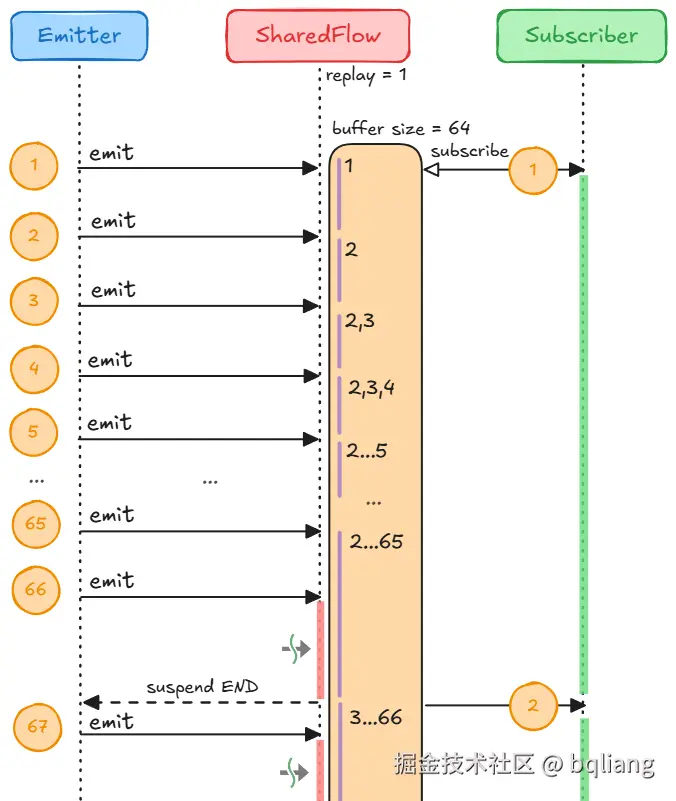
- Emmiter 发送 1,进入 buffer 被缓存,同时发给 Subscriber 处理(耗时 3 秒);
- Emmiter 发送 2,替换掉 buffer 中的 1,替换掉是因为 replay = 1,只需保留最新的 1 条数据;
- Emmiter 发送 3,进入 buffer 被缓冲,它不能替换掉 2,因为 2 还没有被现有的所有 Subscriber 消费,还得留着 2,等 Subscriber 处理完 1 了,把 2 给它处理;
- ...
- Emmiter 发送 66,想要进入 buffer,此时 buffer 已经满了,于是生产流程只能停止(挂起);
- 直到第 3 秒,数据 1 被处理完毕,Subscriber 开始处理 buffer 中的 2,此时 2 被现有的所有 Subscriber 消费了,它不需要被缓冲了,同时,因为 replay = 1,2 不是最新那条数据,也没必要留着发送给未来的新订阅者。是时候将 2 逐出 buffer 了,腾出位置让门外的 66 进来。
- 生产流程得以继续,Emitter 发送 67,想要进入 buffer,此时 buffer 又已经满了,于是生产流程又只能停止(挂起)了......
使用 SharingStarted.WhileSubscribed(),还可以配置上游 Flow 结束和重启的规则。当下游的所有订阅全都结束之后,它会把上游的所有的生产过程也结束掉,而且这时候如果再来新的订阅,它就会重新启动上游的数据流。
suspend fun main(): Unit = coroutineScope { // this: CoroutineScopeval flow = flow {println("start emit")(1..3).forEach {delay(1000)emit(it)}}val sharedFlow = flow.shareIn(scope = this,started = SharingStarted.WhileSubscribed(),replay = 1,)val job = launch {println("collect1 start")sharedFlow.collectIndexed { index, value ->println("collect1: $value")if (index == 1) cancel() // 收集完第二个数据后停止收集}}job.join()println("collect1 finished")delay(1000)launch {println("collect2 start")sharedFlow.collect {println("collect2: $it")}}
}
第一次收集的时候,收集了两个数据就结束收集了,此时唯的一 collect 已经结束,所以上游的 Flow 生产流程也结束了,随后再次调用 SharedFlow.collect(),上游 Flow 生产流程再次被启动了,所以打印了两次 "start emit".
请注意,第二次调用 SharedFlow.collect() 时,上游的生产还没被重启,就先打印了一条数据(2),这是因为参数 replay = 1,那是 SharedFlow 缓存下来的数据。
WhileSubscribed() 有两个参数,它们都是用于配置延时
stopTimeoutMillis 用于配置结束的延时。具体来说,如果 SharedFlow 的所有 collect 都结束了,此时先不结束上游 Flow 的生产流程,从现在开始计时,如果计时过程中,有新的 SharedFlow.collect() 被调用,那么就不取消上游 Flow 的生产流程了。当然,如果计时结束了仍没有新的 SharedFlow.collect() 被调用,那么就会正式结束上游 Flow 的生产。
suspend fun main(): Unit = coroutineScope { // this: CoroutineScopeval flow = flow {println("start emit")(1..3).forEach {delay(1000)emit(it)}}val sharedFlow = flow.shareIn(scope = this,started = SharingStarted.WhileSubscribed(stopTimeoutMillis = 1000,),replay = 1,)val job = launch {println("collect1 start")sharedFlow.collectIndexed { index, value ->println("collect1: $value")if (index == 1) cancel()}}job.join()println("collect1 finished")delay(500)launch {println("collect2 start")sharedFlow.collect {println("collect2: $it")}}
}
"start emit" 只打印了一次,可见上游 Flow 确实没有重启。
第二个参数, replayExpirationMillis,
它设置的是缓存的失效时间。在上游 Flow 结束了,并且设置的 replayExpirationMillis 也超时之后(期间没有新的 SharedFlow.collect() 调用),SharedFlow 缓存下来的那些最近数据就会被清空。
replayExpirationMillis 的默认值是无限大,也就是永远不会在上游 Flow 结束后丢弃缓存的最近数据,如果设置成 0,它就是在上游 Flow 结束的一瞬间就清空缓存的最近数据。
suspend fun main(): Unit = coroutineScope { // this: CoroutineScopeval flow = flow {println("start emit")(1..3).forEach {delay(1000)emit(it)}}val sharedFlow = flow.shareIn(scope = this,started = SharingStarted.WhileSubscribed(stopTimeoutMillis = 0,replayExpirationMillis = 250,),replay = 1,)val job = launch {println("collect1 start")sharedFlow.collectIndexed { index, value ->println("collect1: $value")if (index == 1) cancel()}}job.join()println("collect1 finished")delay(500)launch {println("collect2 start")sharedFlow.collect {println("collect2: $it")}}
}
结果:
collect1 start
start emit
collect1: 1
collect1: 2
collect1 finished
collect2 start
collect2: 2 👈这句没输出
start emit
collect2: 1
collect2: 2
collect2: 3
stopTimeoutMillis 和 replayExpirationMillis 两个参数都是配置延时,一个是对于结束 Flow 的延时,一个是 Flow 结束之后,清空缓存数据的延时。
如果程序里有一个可以被订阅的事件流,该事件流会在多个地方被订阅,同时这个事件流的生产流程非常消耗资源,需要在所有订阅都结束的时候,及时的结束 Flow 的生产,这种场景下就非常适合用 WhileSubscribed() 来配置这种自动结束自动重启的 SharedFlow 了。
我们发现 MutableSharedFlow 是 SharedFlow 的子接口,同时它也是 FlowCollector 的子接口:
// SharedFlow.kt
public interface MutableSharedFlow<T>: SharedFlow<T>, FlowCollector<T> {override suspend fun emit(value: T) // 📌public fun tryEmit(value: T): Booleanpublic val subscriptionCount: StateFlow<Int>public fun resetReplayCache()
}
它重写了 emit 方法
有什么不同
FlowCollector 的 emit 方法是 Flow 数据传递的基础,无法自主发射新事件,无法合并多个数据源,而 SharedFlow 的 emit 方法则是为了支持多个订阅者之间的数据共享和广播
public fun <T> Flow<T>.shareIn(scope: CoroutineScope,started: SharingStarted,replay: Int = 0
): SharedFlow<T> {val config = configureSharing(replay)val shared = MutableSharedFlow<T>(replay = replay,extraBufferCapacity = config.extraBufferCapacity,onBufferOverflow = config.onBufferOverflow)@Suppress("UNCHECKED_CAST")val job = scope.launchSharing(config.context, config.upstream, shared, started, NO_VALUE as T)return ReadonlySharedFlow(shared, job)
}
发现了么,返回的是 ReadonlySharedFlow, shareIn() 生成的 SharedFlow 只能被动转发原始 Flow 的数据
MutableSharedFlow 继承 FlowCollector 是为了让它具备接收和处理元素的能力。
1. 遵循 Flow 框架的统一设计理念
在 Kotlin 的协程 Flow 框架里,FlowCollector 是一个核心接口,其定义了如何收集(也就是接收和处理)流中的元素。
MutableSharedFlow 继承 FlowCollector 能让它遵循 Flow 框架的统一设计,成为一个标准的流收集器。这意味着 MutableSharedFlow 可以和其他 Flow 操作符、构建器以及相关的工具无缝集成。
2. 便于作为收集器使用
由于 MutableSharedFlow 继承了 FlowCollector,所以它能够直接当作收集器传递给其他 Flow 的操作。例如,你可以把 MutableSharedFlow 实例传递给 Flow 的 collect 方法,从而把一个 Flow 中的元素收集到 MutableSharedFlow 里,示例代码如下:
fun main() = runBlocking {val mutableSharedFlow = MutableSharedFlow<Int>()val flow = flow {for (i in 1..5) {emit(i)delay(100)}}// 将 MutableSharedFlow 作为收集器使用flow.collect(mutableSharedFlow)
}
3. 解耦发射逻辑
尽管 SharedFlow 里有 emit 方法,但 MutableSharedFlow 继承 FlowCollector 能把发射逻辑进一步抽象和解耦。FlowCollector 接口只定义了 emit 操作,而 MutableSharedFlow 实现了这个接口,这样就把发射逻辑封装在 MutableSharedFlow 内部,使得代码的结构更加清晰,也更易于维护和扩展。
4. 提高代码的灵活性和可复用性
继承 FlowCollector 能让 MutableSharedFlow 在不同的场景下被复用。无论是在简单的数据流处理中,还是在复杂的异步编程架构里,MutableSharedFlow 都可以作为一个通用的收集器来使用,从而提高了代码的灵活性和可复用性。
综上所述,MutableSharedFlow 继承 FlowCollector 是为了更好地融入 Flow 框架,实现统一的设计理念,方便作为收集器使用,解耦发射逻辑,以及提高代码的灵活性和可复用性。
replay 的侧重点是“缓存重放”,如果你不想要重放,只想提升 Emitter 吞吐量,那么就应该使用 extraBufferCapacity
asSharedFlow
MutableSharedFlow 提供了一个 asSharedFlow() 扩展函数,它可以将 MutableSharedFlow 转换为 SharedFlow。当你希望将 MutableSharedFlow 对外暴露供订阅使用,但又不希望外部有权限发送数据时,就可以利用该函数创建一个只读的 SharedFlow:
class MyViewModel: ViewModel() {private val _event = MutableSharedFlow()val event: SharedFlow = _event.asSharedFlow()
}