神经网络优化 - 高维变量的非凸优化
网络优化是指寻找一个神经网络模型来使得经验(或结构)风险最小化的过程,包括模型选择以及参数学习等。
关于经验风险最小化和结构风险最小化,请参考博文:
认识机器学习中的经验风险最小化准则_样本均值近似与经验风险最小化的关系-CSDN博客
认识机器学习中的结构风险最小化准则_结构风险机器学习-CSDN博客
深度神经网络是一个高度非线性的模型,其风险函数是一个非凸函数,因此风险最小化是一个非凸优化问题。此外,深度神经网络还存在梯度消失问题。因此,深度神经网络的优化是一个具有挑战性的问题。
神经网络的种类非常多,比如卷积网络、循环网络、图网络等。不同网络的结构也非常不同,有些比较深,有些比较宽,不同参数在网络中的作用也有很大的差异,比如连接权重和偏置的不同,以及循环网络中循环连接上的权重和其他权重的不同。
由于网络结构的多样性,我们很难找到一种通用的优化方法。不同优化方法在不同网络结构上的表现也有比较大的差异。
此外,网络的超参数一般比较多,这也给优化带来很大的挑战.
作为铺垫,前一博文我们介绍了低维空间的非凸优化问题:低维空间的非凸优化问题-CSDN博客
本文我们来正式学习高维变量(空间)的非凸优化。
低维空间的非凸优化问题主要是存在一些局部最优点。基于梯度下降的优化方法会陷入局部最优点,因此在低维空间中非凸优化的主要难点是如何选择初始化参数和逃离局部最优点。深度神经网络的参数非常多,其参数学习是在非常高维空间中的非凸优化问题,其挑战和在低维空间中的非凸优化问题有所不同。
一、这里解释一下:低维空间中非凸优化的“逃离局部最优点”
概念理解
-
局部最优点(Local Optimum)
在非凸优化中,局部最优点指的是在某个小范围内,目标函数的值比附近所有点都小(或大),但它并不一定是全局范围的最小(或最大)值。换言之,它是“这个山谷的最低点”,却可能高于另一座更深的山谷底部。 -
“逃离局部最优点”的含义
-
“逃离”意味着算法在某一次迭代中发现自己处于一个次优的谷底(局部最优),如果继续按常规梯度方向下降,则只会在这个谷底中震荡,无法到达更深的、全局最优的山谷。
-
要“逃离”,就需要引入额外机制,让搜索过程能够“跳出”当前的谷底,去探索其他区域,以期找到全局最优解或更优的局部解。
-
为什么会陷入局部最优
-
梯度为零:在局部最优点,目标函数梯度(或一阶导数)为零,普通的梯度下降算法无法再更新参数。
-
鞍点与平坦区域:还可能出现既非极大也非极小的鞍点,算法在此也会停滞。
-
目标地形复杂:非凸函数常有多个起伏不平的“山谷”和“山峰”,算法只要初始点落在某个山谷附近,就可能陷入该谷。
常见“逃离”策略
-
多次随机初始化(Random Restarts)
-
从不同的初始点多次运行优化算法,记录各次结果,取最优者。这样可增加至少一次落到全局最优区域的概率。
-
-
模拟退火(Simulated Annealing)
-
引入温度参数,允许算法以一定概率接受“上坡”(目标值变差)的步骤;随着温度逐渐降低,这种随机越过山脊的机会减少,从而有机会跳出局部谷底。
-
-
添加噪声(Noise Injection)
-
在每次梯度更新时加入小随机扰动,扰动有助于摆脱梯度为零的陷阱,将参数推离局部极值点。
-
-
动量方法(Momentum)
-
利用过去梯度的累积方向,帮助克服鞍点或浅谷的拖拽效应,使得优化路径能继续往前越过局部障碍。
-
-
演化或群体算法(Genetic Algorithms, Particle Swarm)
-
使用多种候选解同时搜索,通过选择、交叉、变异等操作,群体解可跳出局部最优,逐代逼近全局最优。
-
“逃离局部最优点”就是让优化算法不被眼前的小山谷困住,而有能力去尝试更远处的区域,以期寻找到全局最优或更优的局部解。常见做法包括多次随机启动、模拟退火、噪声注入、动量方法和群体智能等,它们从不同角度帮助“跳出”或“越过”局部最优的障碍。
二、从鞍点角度分析高维变量(空间)的非凸优化
在高维空间中,非凸优化的难点并不在于如何逃离局部最优点,而是如何逃离鞍点(Saddle Point)。鞍点的梯度是 0,但是在一些维 度上是最高点,在另一些维度上是最低点,如下图:
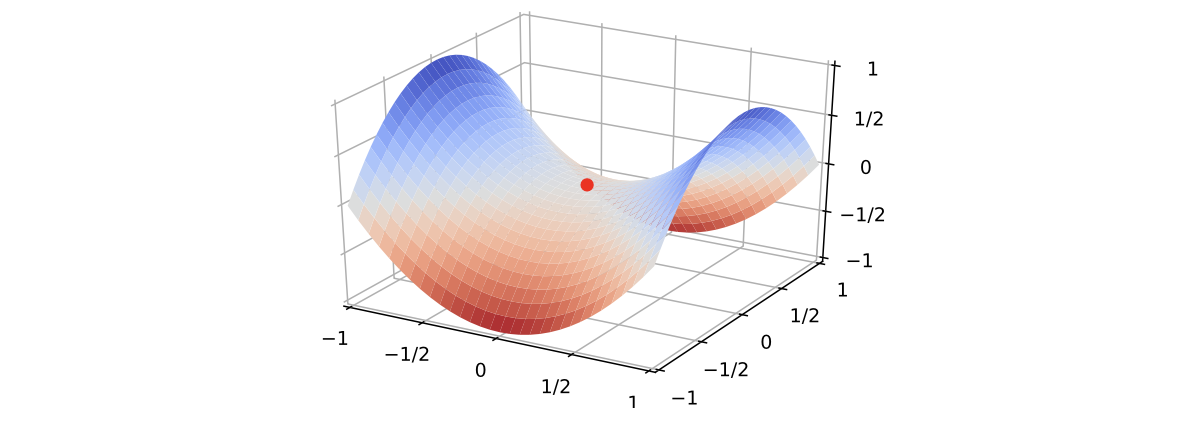
鞍点的叫法是因为其形状像马鞍。鞍点的特征是一阶梯度为0,但是二阶梯度的 Hessian 矩阵不是半正定矩阵。
在高维空间中,局部最小值(Local Minima)要求在每一维度上都是最低点,这种概率非常低。假设网络有10,000维参数,梯度为0的点(即驻点(Sta-tionary Point))在某一维上是局部最小值的概率为 𝑝,那么在整个参数空间中,驻点是局部最优点的概率为 𝑝10,000,这种可能性非常小。也就是说,在高维空间 中大部分驻点都是鞍点。
基于梯度下降的优化方法会在鞍点附近接近于停滞,很难从这些鞍点中逃 离。因此,随机梯度下降对于高维空间中的非凸优化问题十分重要,通过在梯度方向上引入随机性,可以有效地逃离鞍点。后面的博文中会详细介绍。
Hessian 矩阵是什么?

这个矩阵在优化中非常重要,可以用来判断驻点(梯度为零的点)是极小点、极大点还是鞍点:
-
若 Hessian 正定(所有特征值都大于零),则该驻点是局部极小。
-
若 Hessian 负定(所有特征值都小于零),则该驻点是局部极大。
-
若 Hessian 不定(既有正特征值也有负特征值),则该驻点是鞍点。
半正定矩阵是什么?

在优化中:
-
如果 Hessian 是半正定的,那么函数在该点附近是“向上开口”的(或平坦),可能是局部极小或鞍点,但不会是局部极大。
-
半正定性质保证二次近似不会在任何方向上出现向下的“山形”,常用于证明凸函数的二次泰勒展开是下界。
这些数学定义的理解,需要额外去翻阅资料去了解,大家感兴趣可以自行深入了解一下,这里只总结性的列一下,辅助理解高维空间中,逃离鞍点的复杂性。
三、从平坦最小值分析高维变量(空间)的非凸优化
深度神经网络的参数非常多,并且有一定的冗余性,这使得每单个 参数对最终损失的影响都比较小,因此会导致损失函数在局部最小解附近通常 是一个平坦的区域,称为平坦最小值。
下图给出了平坦最小值和尖锐最小值(Sharp Minima)的示例:
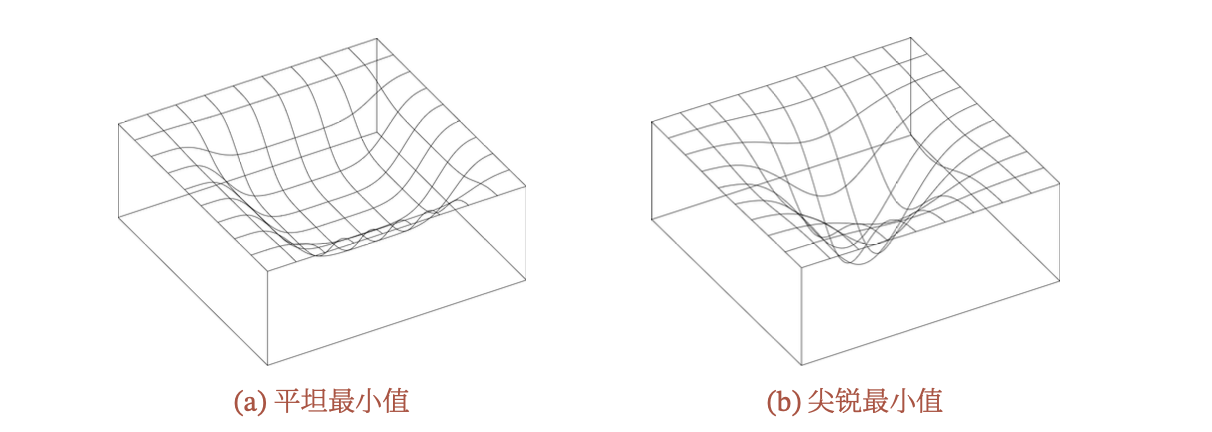
在一个平坦最小值的邻域内,所有点对应的训练损失都比较接近,表明我们这里的很多描述都是在训练神经网络时,不需要精确地找到一个局部最小解,只要在一个局部最小解 的邻域内就足够了。平坦最小值通常被认为和模型泛化能力有一定的关系。一般而言,当一个模型收敛到一个平坦的局部最小值时,其鲁棒性会更好,即微小的参数变动不会剧烈影响模型能力(鲁棒性的定义);而当一个模型收敛到一个尖锐的局部最小值 时,其鲁棒性也会比较差。具备良好泛化能力的模型通常应该是鲁棒的,因此理想的局部最小值应该是平坦的。
(这里的很多描述都是经验性的,并没有很好的理论证明)
四、从局部最小解的等价性分析高维变量(空间)的非凸优化
在非常大的神经网络中,大部分的局部最小解是等价的, 它们在测试集上性能都比较相似。此外,局部最小解对应的训练损失都可能非常接近于全局最小解对应的训练损失 。虽然神经网络 有一定概率收敛于比较差的局部最小值,但随着网络规模增加,网络陷入比较差的局部最小值的概率会大大降低。在训练神经网络时,我们通常没有必要找全局 最小值,这反而可能导致过拟合。
在高维非凸优化中,神经网络的局部最小解通常表现出“等价性”(equivalence),即绝大多数局部最小点在目标值(损失)和泛化能力上差异极小。
(一)概要
-
高维效应:随着参数维度增加,损失函数的随机成分平均化,绝大多数局部极小点集中在一个狭窄的“能量带”中,损失值相近。
-
自旋玻璃理论:借鉴物理中自旋玻璃模型,高维随机场的局部极小多且值近。
-
参数对称性:神经网络层内部的置换对称使得同一个模型函数对应多个参数解,进一步增多“等价”局部极小。
(二)几何与自旋玻璃视角
-
能量地形多峰结构
-
在数千甚至数百万维参数空间中,目标函数类似“多峰山脉”。
-
随机矩阵理论显示,绝大多数局部极小值点对应的 Hessian 特征值分布都集中在相似区间,这意味着它们的“深度”(损失值)近似一致。
-
-
自旋玻璃模型对比
-
Choromanska 等人在 AISTATS 2015 中将深度网络损失与自旋玻璃能量函数做类比,证明局部极小值的损失值几乎等价。
-
这表明在高度非凸的高维场景下,真正的全局最优与普通局部最优在数值上区别微小,不至显著影响模型性能。
-
(三)参数对称性与模式连通
-
置换对称
-
同一隐藏层中神经元的任意置换不会改变网络函数输出,使得参数空间存在巨大的等价类。
-
这意味着若一个解是局部极小,那么对其神经元重命名后仍是一个等价解,增大了局部极小的数量且使其等价。
-
-
模式连通性(Mode Connectivity)
-
Garipov 等人(ICML 2018)和 Draxler 等人(ICLR 2018)观察到,不同训练得到的局部极小点之间可以通过低损失的“拱桥”相连,说明它们位于同一个连通“谷底”区域。
-
这种结构进一步支持所有局部极小的等价性:它们并非孤立,而是在同一平坦区域的不同“点”。
-
(四)实证与理论支持
-
Kawaguchi 的全局极小无“坏”局部论
-
Kawaguchi(NIPS 2016)证明,对于线性或某些简化非线性网络,所有局部极小都是全局极小,强化了等价性的理论基础。
-
-
Dauphin 的鞍点主导论
-
Dauphin 等(NIPS 2014)指出,高维非凸场景下,梯度下降更易被大量高索引鞍点而非局部极小所阻,于是能到达平坦的局部极小区域,这些区域损失相近且泛化好。
-
(五)小结
-
在高维非凸优化中,参数维度越高,局部极小点的“深度”分布越集中,几乎等价。
-
这种等价性来源于统计平均效应、自旋玻璃类比和网络自身的对称结构。
-
理论与实验均表明,只要算法能避开鞍点并到达平坦区域,不同初始化往往收敛到等价的低损失解,从而保证泛化性能稳定。
注:关于这部分,个人建议,我们更多的认识到,有“局部最小解的等价性”这个理论存在,然后理解其在高维变量(空间)的非凸优化中的应用及其合理性即可。当然若想进一步理解其原理和理论依据,可以去深究一下上面提到的各种理论和研究。