2025.04.16【GroupedandStackedbarplot】生信数据可视化技法
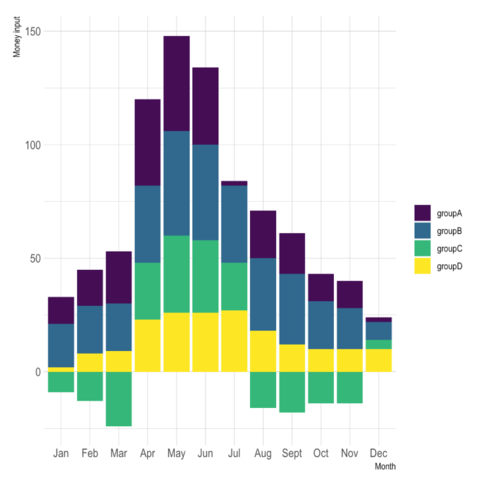
Negative values
This blogpost shows what happens when the dataset includes negative values.
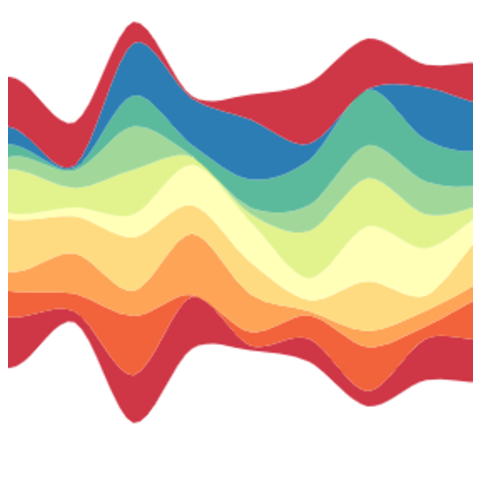
Most basic streamchart
The most basic streamchart you can build with R and the streamgraph package.
文章目录
- Negative values
- Most basic streamchart
- 2025.04.16【Grouped and Stacked barplot】| 生信数据可视化技法
- 引言
- 堆叠条形图(Stacked Barplot)
- 绘制堆叠条形图
- 分组条形图(Grouped Barplot)
- 绘制分组条形图
- 数据可视化的最佳实践
- 结论
2025.04.16【Grouped and Stacked barplot】| 生信数据可视化技法
引言
在生物信息学领域,数据可视化是理解复杂数据集的重要工具。今天,我们来探讨堆叠条形图(Stacked Barplot)和分组条形图(Grouped Barplot)的绘制方法。这两种图表类型用于展示不同实体及其子组的数值数据。在深入研究之前,确保你已经掌握了基本的条形图绘制技巧。
堆叠条形图(Stacked Barplot)
堆叠条形图通过将不同子组的值叠加在一起,直观地展示总量和各部分的分布。这种图表类型在展示基因表达数据、蛋白质丰度或任何需要按类别和子类别比较数据的场景中尤为有用。
绘制堆叠条形图
在R语言中,我们可以使用ggplot2包来绘制堆叠条形图。首先,我们需要安装并加载ggplot2包:
install.packages("ggplot2")
library(ggplot2)接下来,我们将创建一个示例数据集,用于绘制堆叠条形图:
# 创建示例数据集
data <- data.frame(Category = rep(c("A", "B", "C"), each = 3),Subgroup = rep(c("X", "Y", "Z"), times = 3),Value = c(10, 15, 7, 12, 20, 8, 9, 14, 6)
)现在,我们可以使用ggplot2来绘制堆叠条形图:
# 绘制堆叠条形图
ggplot(data, aes(x = Category, y = Value, fill = Subgroup)) +geom_bar(stat = "identity") +theme_minimal() +labs(title = "堆叠条形图示例", x = "类别", y = "数值")在这个例子中,aes函数用于定义图表的美学映射,geom_bar函数用于创建条形图,stat = "identity"表示我们直接使用数据中的值来绘制条形图。theme_minimal()用于应用一个简洁的主题,labs函数用于添加图表的标题和轴标签。
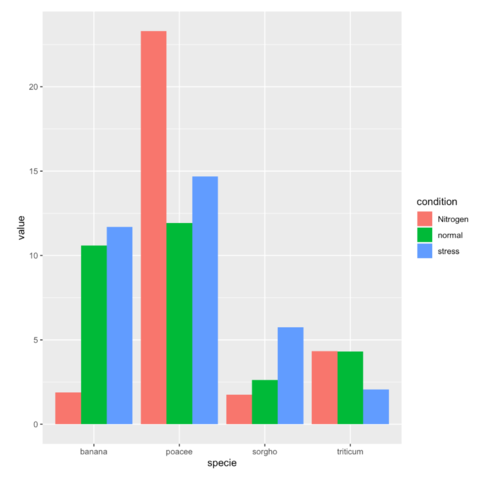
分组条形图(Grouped Barplot)
分组条形图将每个子组的条形并排放置,便于比较不同子组之间的数值差异。
绘制分组条形图
我们可以使用相同的数据集来绘制分组条形图。首先,我们需要对数据进行一些调整,以便每个子组的条形可以并排放置:
# 调整数据结构
data_long <- tidyr::pivot_longer(data, cols = c(Value), names_to = "Subgroup", values_to = "Value")现在,我们可以使用调整后的数据集来绘制分组条形图:
# 绘制分组条形图
ggplot(data_long, aes(x = Category, y = Value, fill = Subgroup)) +geom_bar(stat = "identity", position = "dodge") +theme_minimal() +labs(title = "分组条形图示例", x = "类别", y = "数值")在这个例子中,position = "dodge"参数用于将每个子组的条形并排放置。这样,我们可以轻松地比较不同子组之间的数值差异。
数据可视化的最佳实践
在生物信息学中,数据可视化不仅仅是展示数据,更重要的是传达信息和发现模式。以下是一些数据可视化的最佳实践:
-
选择合适的图表类型:根据数据的特点和分析目的选择合适的图表类型。例如,堆叠条形图适用于展示总量和各部分的分布,而分组条形图适用于比较不同子组之间的数值差异。
-
保持图表简洁:避免在图表中使用过多的颜色和元素,以免分散观众的注意力。简洁的图表更容易理解和解释。
-
使用有意义的颜色:颜色应该有助于区分不同的类别或子组,而不是仅仅为了装饰。避免使用过于鲜艳或对比度低的颜色。
-
添加注释和标签:为图表添加必要的注释和标签,以便观众可以快速理解图表的内容和含义。
-
考虑交互性:如果可能的话,考虑使用交互式图表,以便观众可以探索数据的不同方面。
结论
在生物信息学中,数据可视化是理解复杂数据集的重要工具。通过掌握堆叠条形图和分组条形图的绘制方法,我们可以更有效地传达我们的研究成果。希望这篇文章能帮助你更好地理解和应用这些图表类型。
🌟 非常感谢您抽出宝贵的时间阅读我的文章。如果您觉得这篇文章对您有所帮助,或者激发了您对生物信息学的兴趣,我诚挚地邀请您:
👍 点赞这篇文章,让更多人看到我们共同的热爱和追求。
🔔 关注我的账号,不错过每一次知识的分享和探索的旅程。
📢 您的每一个点赞和关注都是对我最大的支持和鼓励,也是推动我继续创作优质内容的动力。
📚 我承诺,将持续为您带来深度与广度兼具的生物信息学内容,让我们一起在知识的海洋中遨游,发现更多未知的奇迹。
💌 如果您有任何问题或想要进一步交流,欢迎在评论区留言,我会尽快回复您。