【强化学习】#2 有限马尔可夫决策过程
主要参考学习资料:《强化学习(第2版)》[加]Richard S.Suttion [美]Andrew G.Barto 著
概述
- 马尔可夫决策过程综合动作、状态、收益建立了强化学习最基础的数学模型。
- 回报是智能体需要最大化的全部未来收益的函数,折扣对未来收益进行加权。
- 交互任务根据其是否能自然分解为幕分为分幕式任务和持续性任务。
- 策略的价值函数给出了每个状态或“状态-动作”二元组的期望回报值。
- 最优价值函数给出了价值函数在所有策略中的最大值,相应的策略为最优策略。
- 贝尔曼最优方程是最优价值函数必须满足的一致性条件,在非理想情况下只能近似求解。
目录
- “智能体-环境”交互接口
- 目标和收益
- 回报和分幕
- 分幕式和持续性任务的统一表示法
- 策略和价值函数
- 最优策略和最优价值函数
“智能体-环境”交互接口
马尔可夫决策过程(MDP)是一种通过交互式学习来实现目标的理论框架。进行学习及实施决策的机器被称为智能体,智能体之外所有与其相互作用的事物都被称为环境。智能体选择动作,环境对这些动作做出相应的响应,并向智能体呈现出新的状态。环境也会产生一个收益,这就是智能体在动作选择过程中想要最大化的目标。
我们对此过程建立数学模型。在每个时刻 t t t,智能体观察到所在的环境状态的某种特征表达 S t ∈ S S_t\in\mathcal S St∈S,并在此基础上选择一个动作 A t ∈ A ( s ) A_t\in\mathcal A(s) At∈A(s)。下一时刻,作为其动作的结果,智能体接收到一个数值化的收益 R t + 1 ∈ R R_{t+1}\in\mathcal R Rt+1∈R,并进入一个新的状态 S t + 1 S_{t+1} St+1。从而,MDP和智能体共同给出了一个序列:
S 0 , A 0 , R 1 , S 1 , A 1 , R 2 , ⋯ S_0,A_0,R_1,S_1,A_1,R_2,\cdots S0,A0,R1,S1,A1,R2,⋯
在有限MDP中, S \mathcal S S、 A \mathcal A A和 R \mathcal R R都只有有限个元素。在这种情况下,随机变量 R t R_t Rt和 S t S_t St具有定义明确的离散概率分布,并且只依赖于前继状态和动作。在给定前继状态 s s s和动作 a a a的值时,这些随机变量的特定值 s ′ ∈ S s'\in\mathcal S s′∈S和 r ∈ R r\in\mathcal R r∈R在 t t t时刻出现的概率是:
p ( s ′ , r ∣ s , a ) = ˙ P r { S t = s ′ , R t = r ∣ S t − 1 = s , A t − 1 = a } p(s',r|s,a)\dot=\mathrm{Pr}\{S_t=s',R_t=r|S_{t-1}=s,A_{t-1}=a\} p(s′,r∣s,a)=˙Pr{St=s′,Rt=r∣St−1=s,At−1=a}
函数 p p p定义了MDP的动态特性,为每个 s s s和 a a a的选择都指定了一个概率分布。 S t S_t St和 R t R_t Rt的每个可能的值出现的概率只取决于前一个状态 S t − 1 S_{t-1} St−1和动作 A t − 1 A_{t-1} At−1,即状态具有马尔可夫性。
从四参数动态函数 p : S × R × S × A → [ 0 , 1 ] p:\mathcal S\times\mathcal R\times\mathcal S\times\mathcal A\rightarrow[0,1] p:S×R×S×A→[0,1]中,我们可以计算出关于环境的任何其他信息,例如状态转移概率 p : S × S × A → [ 0 , 1 ] p:\mathcal S\times\mathcal S\times\mathcal A\rightarrow[0,1] p:S×S×A→[0,1]:
p ( s ′ ∣ s , a ) = ˙ ∑ r ∈ R p ( s ′ , r ∣ s , a ) p(s'|s,a)\dot=\displaystyle\sum_{r\in\mathcal R}p(s',r|s,a) p(s′∣s,a)=˙r∈R∑p(s′,r∣s,a)
“状态-动作”二元组的期望收益 r : S × A → R r:\mathcal S\times\mathcal A\rightarrow\mathbb R r:S×A→R:
r ( s , a ) = ˙ E [ R t ∣ S t − 1 = s , A t − 1 = a ] = ∑ r ∈ R r ∑ s ′ ∈ S p ( s ′ , r ∣ s , a ) r(s,a)\dot=\mathbb E[R_t|S_{t-1}=s,A_{t-1}=a]=\displaystyle\sum_{r\in\mathcal R}r\sum_{s'\in\mathcal S}p(s',r|s,a) r(s,a)=˙E[Rt∣St−1=s,At−1=a]=r∈R∑rs′∈S∑p(s′,r∣s,a)
“状态-动作-后继状态”三元组的期望收益 r : S × A × S → R r:\mathcal S\times\mathcal A\times\mathcal S\rightarrow\mathbb R r:S×A×S→R:
r ( s , a , s ′ ) = ˙ E [ R t ∣ S t − 1 = s , A t − 1 = a , S t = s ′ ] = ∑ r ∈ R r p ( s ′ , r ∣ s , a ) p ( s ′ ∣ s , a ) r(s,a,s')\dot=\mathbb E[R_t|S_{t-1}=s,A_{t-1}=a,S_t=s']=\displaystyle\sum_{r\in\mathcal R}r\frac{p(s',r|s,a)}{p(s'|s,a)} r(s,a,s′)=˙E[Rt∣St−1=s,At−1=a,St=s′]=r∈R∑rp(s′∣s,a)p(s′,r∣s,a)
MDP框架非常抽象与灵活。一般来说,动作可以是任何我们想要做的决策,而状态则可以是任何对决策有所帮助的事情。
目标和收益
在强化学习中,智能体的目标被形式化表征为收益。在每个时刻,收益都是一个单一标量数值 R t ∈ R R_t\in\mathbb R Rt∈R。所有的目标都可以归结为最大化智能体接收到的收益累积和的期望值。
如果要想智能体为我们做某件事,我们提供收益的方式必须要使得智能体在最大化收益的同时也实现我们的目标。例如,围棋智能体只有当最终获胜时才能获得收益,而非达到某个子目标。如果实现这些子目标也能获得收益,比如吃掉对方的子,那么它可能会找到一种以输掉比赛为代价的方式来达成它们。
回报和分幕
智能体最大限度提高长期收益的目标必然与时刻 t t t后接收的收益序列 R t + 1 , R t + 2 , R t + 3 , ⋯ R_{t+1},R_{t+2},R_{t+3},\cdots Rt+1,Rt+2,Rt+3,⋯有关。为了正式化定义这个目标,我们给出回报 G t G_t Gt,它被定义为收益序列的一些特定函数,我们寻求的则是最大化期望回报。在最简单的情况下,回报是后续收益的总和:
G t = ˙ R t + 1 + R t + 2 + R t + 3 + ⋯ + R T G_t\dot=R_{t+1}+R_{t+2}+R_{t+3}+\cdots+R_T Gt=˙Rt+1+Rt+2+Rt+3+⋯+RT
其中 T T T是最终时刻。最终时刻的概念被用于分幕式任务,在这类任务中,智能体和环境的交互能被自然地分成一系列被称为幕的子序列,每个子序列都存在最终时刻,例如一盘游戏、走一次迷宫等重复性的交互过程。每幕都以一种特殊状态结束,被称为终结状态,随后会重新从某个标准起始状态或起始状态的分布中的某个状态样本开始。在分幕式任务中,我们有时要区分非终结状态集,记为 S \mathcal S S,和包含终结与非终结状态的所有状态集,记为 S + \mathcal S^+ S+。最终时刻 T T T是一个随机变量,通常随着幕的不同而不同。
与分幕式任务相对的是持续性任务,即智能体和环境的交互不能被自然地分为单独的幕,而是持续不断地发生,例如一个连续的过程控制任务或长期运行机器人的应用。持续性任务的最终时刻 T = ∞ T=\infty T=∞,这将导致最大化回报很容易趋于无穷,为此我们需要引入折扣的概念。
根据折扣方法,回报是后续收益经过折扣系数加权后的收益总和,即折后回报:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ = ∑ k = 0 ∞ γ k R t + k + 1 G_t=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\cdots=\displaystyle\sum^\infty_{k=0}\gamma^kR_{t+k+1} Gt=Rt+1+γRt+2+γ2Rt+3+⋯=k=0∑∞γkRt+k+1
其中 γ ∈ [ 0 , 1 ] \gamma\in[0,1] γ∈[0,1]是折扣率,它决定了未来收益的现值。如果 γ < 1 \gamma<1 γ<1,那么只要收益序列 { R k } \{R_k\} {Rk}有界, G t G_t Gt就是一个有限值。随着 γ \gamma γ接近 1 1 1,折后回报将更多地考虑未来的收益,智能体将变得更有远见。相邻时刻的折扣回报可以用如下递归方式联系起来:
G t = ˙ R t + 1 + γ R t + 2 + γ 2 R t + 3 + γ 3 R t + 4 + ⋯ = R t + 1 + γ ( R t + 2 + γ R t + 3 + γ 2 R t + 4 + ⋯ ) = R t + 1 + γ G t + 1 \begin{equation}\begin{split}G_t&\dot=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\gamma^3R_{t+4}+\cdots\\&=R_{t+1}+\gamma(R_{t+2}+\gamma R_{t+3}+\gamma^2R_{t+4}+\cdots)\\&=R_{t+1}+\gamma G_{t+1}\end{split}\end{equation} Gt=˙Rt+1+γRt+2+γ2Rt+3+γ3Rt+4+⋯=Rt+1+γ(Rt+2+γRt+3+γ2Rt+4+⋯)=Rt+1+γGt+1
通常我们定义 G T = 0 G_T=0 GT=0,这样上式将适用于任意时刻 t < T t<T t<T。
分幕式和持续性任务的统一表示法
分幕式任务的描述除了时刻还要区分所在的幕。 S t , i S_{t,i} St,i表示幕 i i i中时刻 t t t的状态, A t , i A_{t,i} At,i、 R t , i R_{t,i} Rt,i、 π t , i \pi_{t,i} πt,i、 T i T_i Ti等也一样。但通常情况下我们只考虑某个特定的单一的幕序列或适用于所有幕的东西,因此会删除幕编号的显式引用。
统一分幕式(有限项)和持续性(无限项)任务的表示的一种思路是将回报定义为无限项的总和,并在有限项的情况下令最终时刻之后的项都等于 0 0 0。另一种思路是将回报表示为:
G t = ˙ ∑ k = t + 1 T γ k − t − 1 R k G_t\dot=\displaystyle\sum^T_{k=t+1}\gamma^{k-t-1}R_k Gt=˙k=t+1∑Tγk−t−1Rk
并允许 T = ∞ T=\infty T=∞或 γ = 1 \gamma=1 γ=1(但不能同时出现)的情况。
策略和价值函数
价值函数是状态(或“状态-动作”二元组)的函数,用来评估当前智能体在给定状态下的期望回报。智能体的期望回报取决于智能体所选择的动作,因此价值函数与特定的行为方式相关,我们称之为策略。
策略是从状态到每个动作的选择概率之间的映射。如果智能体在时刻 t t t选择策略 π \pi π,那么 π ( a ∣ s ) \pi(a|s) π(a∣s)是当 S t = s S_t=s St=s时 A t = a A_t=a At=a时的概率。
策略 π \pi π下状态 s s s的价值函数记为 v π ( s ) v_\pi(s) vπ(s),即从状态 s s s开始,智能体按照策略 π \pi π进行决策所获得的回报的概率期望值。对于MDP,我们正式定义 v π v_\pi vπ为:
v π ( s ) = ˙ E π [ G t ∣ S t = s ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s ] v_\pi(s)\dot=\mathbb E_\pi[G_t|S_t=s]=\mathbb E_\pi\left[\displaystyle\left.\sum^\infty_{k=0}\gamma^kR_{t+k+1}\right|S_t=s\right] vπ(s)=˙Eπ[Gt∣St=s]=Eπ[k=0∑∞γkRt+k+1 St=s]
其中 E π [ ⋅ ] \mathbb E_\pi[\cdot] Eπ[⋅]表示在给定策略 π \pi π时一个随机变量的期望值,函数 v π v_\pi vπ称为策略 π \pi π的状态价值函数。
同理,策略 π \pi π下在状态 s s s时采取动作 a a a的价值记为 q π ( s , a ) q_\pi(s,a) qπ(s,a),这就是根据策略 π \pi π,从状态 s s s开始,执行动作 a a a之后,所有可能的决策序列的期望回报:
q π ( s , a ) = ˙ E π [ G t ∣ S t = s , A t = a ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ S t = s , A t = a ] q_\pi(s,a)\dot=\mathbb E_\pi[G_t|S_t=s,A_t=a]=\mathbb E_\pi\left[\displaystyle\left.\sum^\infty_{k=0}\gamma^kR_{t+k+1}\right|S_t=s,A_t=a\right] qπ(s,a)=˙Eπ[Gt∣St=s,At=a]=Eπ[k=0∑∞γkRt+k+1 St=s,At=a]
函数 q π q_\pi qπ为策略 π \pi π的动作价值函数。
价值函数 v π v_\pi vπ和 q π q_\pi qπ都能从经验中估算得到。如果一个智能体遵循策略 π \pi π,且对每个遇到的状态都记录该状态后的实际回报的平均值,那么随着状态出现的次数接近无穷大,这个平均值会收敛到状态价值 v π ( s ) v_\pi(s) vπ(s)。如果为每个状态的每个动作都保留单独的平均值,那么这些平均值也会收敛到动作价值 q π ( s , a ) q_\pi(s,a) qπ(s,a)。这种估算方法称作蒙特卡洛方法,将在后续章节介绍。
在强化学习和动态规划中,价值函数都满足某种递归关系。对于任何策略 π \pi π和任何状态 s s s, s s s的价值与其可能的后继状态的价值之间存在以下关系:
v π ( s ) = ˙ E π [ G t ∣ S t = s ] = E π [ R t + 1 + γ G t + 1 ∣ S t = s ] = ∑ a π ( a ∣ s ) ∑ s ′ ∑ r p ( s ′ , r ∣ s , a ) [ r + γ R [ G t + 1 ∣ S t + 1 = s ′ ] ] = ∑ a π ( a ∣ s ) ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v π ( s ′ ) ] \begin{equation}\begin{split}v_\pi(s)&\dot=\mathbb E_\pi[G_t|S_t=s]\\&=\mathbb E_\pi[R_{t+1}+\gamma G_{t+1}|S_t=s]\\&=\displaystyle\sum_a\pi(a|s)\sum_{s'}\sum_rp(s',r|s,a)\left[r+\gamma\mathbb R[G_{t+1}|S_{t+1}=s']\right]\\&=\displaystyle\sum_a\pi(a|s)\sum_{s',r}p(s',r|s,a)[r+\gamma v_\pi(s')]\end{split}\end{equation} vπ(s)=˙Eπ[Gt∣St=s]=Eπ[Rt+1+γGt+1∣St=s]=a∑π(a∣s)s′∑r∑p(s′,r∣s,a)[r+γR[Gt+1∣St+1=s′]]=a∑π(a∣s)s′,r∑p(s′,r∣s,a)[r+γvπ(s′)]
其中,动作 a a a取自集合 A ( s ) \mathcal A(s) A(s),下一时刻状态 s ′ s' s′取自集合 S \mathcal S S(在分幕式问题中取自集合 S + \mathcal S^+ S+),收益值 r r r取自集合 R \mathcal R R。该式被称为贝尔曼方程,它对所有可能性采用其出现的概率进行了加权平均。这也说明起始状态的价值一定等于后继状态的(折扣)期望值加上对应收益的期望值。
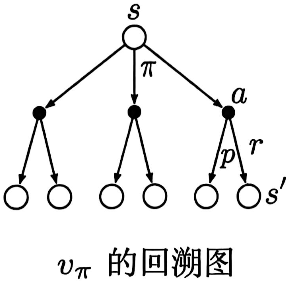
我们可以用回溯图表示这种状态价值和后继状态价值之间的关系。其中空心圆表示一个状态,实心圆表示一个“状态-动作”二元组。从状态 s s s开始,并将其作为根节点,智能体根据策略 π \pi π采取动作集合中任一动作。对每个动作,环境会根据其动态特性函数 p p p,以一个后继状态 s ′ s' s′及其收益 r r r作为响应。回溯图中的关系是回溯运算的基础,也是强化学习方法的核心内容。回溯操作就是将后继状态(或“状态-动作”二元组)的价值信息回传给当前时刻的状态(或“状态-动作”二元组)。
最优策略和最优价值函数
解决一个强化学习任务意味着要找出一个策略,使其能够在长期过程中获得大量收益。对于所有的 s ∈ S s\in\mathcal S s∈S,如果 v π ( s ) ⩾ v π ′ ( s ) v_\pi(s)\geqslant v_{\pi'}(s) vπ(s)⩾vπ′(s),则可以说 π ⩾ π ′ \pi\geqslant\pi' π⩾π′。总会存在至少一个策略不劣于其他所有策略,即最优策略,记为 π ∗ \pi_* π∗。最优策略共享相同的状态价值函数,即最优状态价值函数,记为 v ∗ v_* v∗,其定义为:
∀ s ∈ S , v ∗ ( s ) = ˙ max π v π ( s ) \forall s\in\mathcal S,v_*(s)\dot=\underset\pi\max{v_\pi(s)} ∀s∈S,v∗(s)=˙πmaxvπ(s)
最优策略也共享最优动作价值函数,记为 q ∗ q_* q∗,其定义为:
∀ s ∈ S , a ∈ A , q ∗ ( s , a ) = ˙ max π q π ( s , a ) \forall s\in\mathcal S,a\in\mathcal A,q_*(s,a)\dot=\underset\pi\max{q_\pi(s,a)} ∀s∈S,a∈A,q∗(s,a)=˙πmaxqπ(s,a)
对于“状态-动作”二元组 ( s , a ) (s,a) (s,a),这个函数给出了在状态 s s s下,先采取动作 a a a,之后按照最优策略决策的期望回报,因此可以用 v ∗ v_* v∗表示 q ∗ q_* q∗:
q ∗ ( s , a ) = E [ R t + 1 + γ v ∗ ( S t + 1 ) ∣ S t = s , A t = a ] q_*(s,a)=\mathbb E[R_{t+1}+\gamma v_*(S_{t+1})|S_t=s,A_t=a] q∗(s,a)=E[Rt+1+γv∗(St+1)∣St=s,At=a]
贝尔曼最优方程指出,最优策略下各个状态的价值一定等于这个状态下最优动作的期望值:
v ∗ ( s ) = max a ∈ A ( s ) q π ∗ ( s , a ) v_*(s)=\underset{a\in\mathcal A(s)}{\max}q_{\pi_*}(s,a) v∗(s)=a∈A(s)maxqπ∗(s,a)
以下是博主查阅其余资料自行总结的反证法:
根据定义,状态价值函数 v π ( s ) v_\pi(s) vπ(s)是根据策略 π \pi π选择动作 a a a的概率对相应的动作价值函数 q π ( s , a ) q_\pi(s,a) qπ(s,a)加权平均,那么必然有 v π ( s ) ⩽ max a q π ( s , a ) v_\pi(s)\leqslant\underset a\max q_\pi(s,a) vπ(s)⩽amaxqπ(s,a),对于一个最优策略 π ∗ \pi_* π∗,亦有其状态价值函数满足 v π ∗ ( s ) ⩽ max a q π ∗ ( s , a ) v_{\pi_*}(s)\leqslant\underset a\max q_{\pi_*}(s,a) vπ∗(s)⩽amaxqπ∗(s,a)。
假设 v π ∗ ( s ) < max a q π ∗ ( s , a ) v_{\pi_*}(s)<\underset a\max q_{\pi_*}(s,a) vπ∗(s)<amaxqπ∗(s,a),那么必然存在一个更优的策略 π ∗ ′ \pi_*' π∗′,在状态 s s s选择 A = a r g m a x a q π ∗ ( s , a ) A=\underset a{\mathrm{argmax}} q_{\pi_*}(s,a) A=aargmaxqπ∗(s,a),之后仍按照策略 π ∗ \pi_* π∗选择,使得 v π ∗ ′ = max a q π ∗ ( s , a ) v_{\pi_*'}=\underset a\max q_{\pi_*}(s,a) vπ∗′=amaxqπ∗(s,a),这与最优策略的定义矛盾,因而最优策略的状态价值函数必然趋近于其动作价值函数的最大值。而在有限MDP的条件下(其余条件暂不深入展开),最优策略必然存在,因而必有 v π ∗ ( s ) = max a q π ∗ ( s , a ) v_{\pi_*}(s)=\underset a\max q_{\pi_*}(s,a) vπ∗(s)=amaxqπ∗(s,a)。
将最优动作价值函数写为期望或求和的形式,我们得到贝尔曼最优方程的两种形式:
v ∗ ( s ) = max a E [ R t + 1 + γ v ∗ ( S t + 1 ) ∣ S t = s , A t = a ] = max a ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v ∗ ( s ′ ) ] \begin{equation}\begin{split}v_*(s)&=\underset a\max\mathbb E[R_{t+1}+\gamma v_*(S_{t+1})|S_t=s,A_t=a]\\&=\underset a\max\displaystyle\sum_{s',r}p(s',r|s,a)[r+\gamma v_*(s')]\end{split}\end{equation} v∗(s)=amaxE[Rt+1+γv∗(St+1)∣St=s,At=a]=amaxs′,r∑p(s′,r∣s,a)[r+γv∗(s′)]
同理 q ∗ q_* q∗的贝尔曼最优方程为:
q ∗ ( s , a ) = E [ R t + 1 + γ max a ′ q ∗ ( S t + 1 , a ′ ) ∣ S t = s , A t = a ] = ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ max a ′ q ∗ ( s ′ , a ′ ) ] \begin{equation}\begin{split}q_*(s,a)&=\mathbb E\left[\left.R_{t+1}+\gamma\underset{a'}\max q_*(S_{t+1},a')\right|S_t=s,A_t=a\right]\\&=\displaystyle\sum_{s',r}p(s',r|s,a)\left[r+\gamma\underset{a'}\max q_*(s',a')\right]\end{split}\end{equation} q∗(s,a)=E[Rt+1+γa′maxq∗(St+1,a′) St=s,At=a]=s′,r∑p(s′,r∣s,a)[r+γa′maxq∗(s′,a′)]
一旦根据贝尔曼最优方程求得最优状态价值函数 v ∗ v_* v∗,确定最优策略只需对 q ∗ q_* q∗进行单步搜索,并基于此采取贪心策略即可。
显示求解贝尔曼最优方程来寻找最优策略的方法很少是直接有效的,其至少依赖三条在实际情况下很难满足的假设:
- 我们准确地知道环境的动态变化特性;
- 有足够的计算资源来求解;
- 马尔可夫性质。
在强化学习中,我们通常只能用近似解法来解决这类问题。
除此之外,存储容量也是一个很重要的约束。价值函数、策略和模型的估计通常需要大量的存储空间。在状态集合小而有限的任务中,用数组或表格来估计每个状态(或“状态-动作”二元组)是可能的,我们称之为表格型任务,对应的方法为表格型方法。但在许多实际情况下,有很多状态不能用表格中的一行表示。在这种情况下,价值函数必须采用近似方法,通常使用紧凑的参数化函数表示方法。