PyTorch框架学习01
PyTorch,简称Torch,主流的经典的深度学习框架,如果你只想掌握一个深度学习框架,那就毫不犹豫的选择他吧!
Tensor概述
1. 概念
张量是一个多维数组,通俗来说可以看作是扩展了标量、向量、矩阵的更高维度的数组。张量的维度决定了它的形状(Shape),例如:
-
标量 是 0 维张量,如
a = torch.tensor(5) -
向量 是 1 维张量,如
b = torch.tensor([1, 2, 3]) -
矩阵 是 2 维张量,如
c = torch.tensor([[1, 2], [3, 4]]) -
更高维度的张量,如3维、4维等,通常用于表示图像、视频数据等复杂结构。
2. 特点
-
动态计算图:PyTorch 支持动态计算图,这意味着在每一次前向传播时,计算图是即时创建的。
-
GPU 支持:PyTorch 张量可以通过
.to('cuda')移动到 GPU 上进行加速计算。 -
自动微分:通过
autograd模块,PyTorch 可以自动计算张量运算的梯度,这对深度学习中的反向传播算法非常重要。
3. 数据类型
PyTorch中有3种数据类型:浮点数、整数、布尔。其中,浮点数和整数又分为8位、16位、32位、64位,加起来共9种。
为什么要分为8位、16位、32位、64位呢?
场景不同,对数据的精度和速度要求不同。通常,移动或嵌入式设备追求速度,对精度要求相对低一些。精度越高,往往效果也越好,自然硬件开销就比较高。
Tensor的创建
torch.tensor 创建
示例
import torch
import numpy as npdef test001():# 1. 用标量创建张量tensor = torch.tensor(5)print(tensor.shape)# 2. 使用numpy随机一个数组创建张量tensor = torch.tensor(np.random.randn(3, 5))print(tensor)print(tensor.shape)# 3. 根据list创建tensortensor = torch.tensor([[1, 2, 3], [4, 5, 6]])print(tensor)print(tensor.shape)print(tensor.dtype)if __name__ == '__main__':test001()torch.Tensor
注意这里的Tensor是大写,该API根据形状创建张量,其也可用来创建指定数据的张量。
import torch
import numpy as npdef test002():# 1. 根据形状创建张量tensor1 = torch.Tensor(2, 3)print(tensor1)# 2. 也可以是具体的值tensor2 = torch.Tensor([[1, 2, 3], [4, 5, 6]])print(tensor2, tensor2.shape, tensor2.dtype)tensor3 = torch.Tensor([10])print(tensor3, tensor3.shape, tensor3.dtype)# 指定tensor数据类型tensor1 = torch.Tensor([1,2,3]).short()print(tensor1)tensor1 = torch.Tensor([1,2,3]).int()print(tensor1)tensor1 = torch.Tensor([1,2,3]).float()print(tensor1)tensor1 = torch.Tensor([1,2,3]).double()print(tensor1)if __name__ == "__main__":test002()
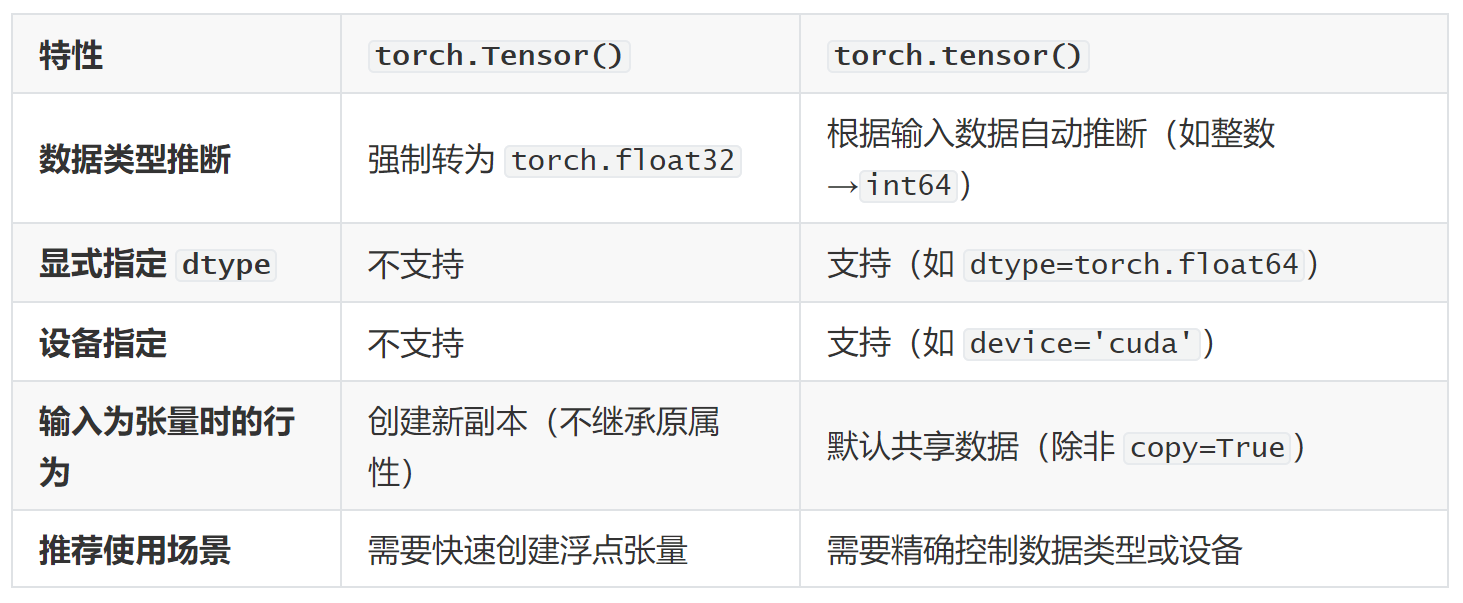
torch.Tensor与torch.tensor区别
创建线性和随机张量
在 PyTorch 中,可以轻松创建线性张量和随机张量。
使用torch.arange 和 torch.linspace 创建线性张量:
示例
import torch
import numpy as np# 不用科学计数法打印
torch.set_printoptions(sci_mode=False)def test004():# 1. 创建线性张量r1 = torch.arange(0, 10, 2)print(r1)# 2. 在指定空间按照元素个数生成张量:等差r2 = torch.linspace(3, 10, 10)print(r2)r2 = torch.linspace(3, 10000000, 10)print(r2)if __name__ == "__main__":test004()随机数种子
随机数种子(Random Seed)是一个用于初始化随机数生成器的数值。随机数生成器是一种算法,用于生成一个看似随机的数列,但如果使用相同的种子进行初始化,生成器将产生相同的数列。
torch.manual_seed(123)
随机张量
在 PyTorch 中,种子影响所有与随机性相关的操作,包括张量的随机初始化、数据的随机打乱、模型的参数初始化等。通过设置随机数种子,可以做到模型训练和实验结果在不同的运行中进行复现。
创建单位矩张量
创建主对角线上为1的单位张量
data = torch.eye(4)# 4:代表是4阶的单位矩阵
Tensor常见属性
张量有device、dtype、shape等常见属性,知道这些属性对我们认识Tensor很有帮助。
Tensor数据转换
1. Tensor与Numpy
Tensor和Numpy都是常见数据格式,惹不起~
1.1 张量转Numpy
此时分内存共享和内存不共享~
1.1.1 浅拷贝
调用numpy()方法可以把Tensor转换为Numpy,此时内存是共享的。
# 1. 张量转numpydata_tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])data_numpy = data_tensor.numpy()print(type(data_tensor), type(data_numpy))# 2. 他们内存是共享的data_numpy[0, 0] = 100print(data_tensor, data_numpy)
1.1.2 深拷贝
使用copy()方法可以避免内存共享:
data_numpy = data_tensor.numpy().copy()print(type(data_tensor), type(data_numpy))此时他们内存是不共享的
2. Tensor与图像
2.1 图片转Tensor
示例
import torch
from PIL import Image
from torchvision import transforms
import osdef test001():dir_path = os.path.dirname(__file__)file_path = os.path.join(dir_path,'img', '1.jpg')file_path = os.path.relpath(file_path)print(file_path)# 1. 读取图片img = Image.open(file_path)# transforms.ToTensor()用于将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,并自动进行数值归一化和维度调整# 将像素值从 [0, 255] 缩放到 [0.0, 1.0](浮点数)# 自动将图像格式从 (H, W, C)(高度、宽度、通道)转换为 PyTorch 标准的 (C, H, W)transform = transforms.ToTensor()img_tensor = transform(img)print(img_tensor)# transforms:对图片处理,比如图片增强,缩放,裁剪等
2.2 Tensor转图片
示例
import torch
from PIL import Image
from torchvision import transformsdef test002():# 1. 随机一个数据表示图片img_tensor = torch.randn(3, 224, 224)# 2. 创建一个transformstransform = transforms.ToPILImage()# 3. 转换为图片img = transform(img_tensor)img.show()# 4. 保存图片img.save("./test.jpg")Tensor常见操作
阿达玛积
阿达玛积是指两个形状相同的矩阵或张量对应位置的元素相乘。它与矩阵乘法不同,矩阵乘法是线性代数中的标准乘法,而阿达玛积是逐元素操作。假设有两个形状相同的矩阵 A和 B,它们的阿达玛积 C=A∘B定义为:
![]()
同型矩阵,相同位置元素相乘
def test001():data1 = torch.tensor([[1, 2, 3], [4, 5, 6]])data2 = torch.tensor([[2, 3, 4], [2, 2, 3]])print(data1 * data2)def test002():data1 = torch.tensor([[1, 2, 3], [4, 5, 6]])data2 = torch.tensor([[2, 3, 4], [2, 2, 3]])print(data1.mul(data2))张量拼接
在 PyTorch 中,cat 和 stack 是两个用于拼接张量的常用操作,但它们的使用方式和结果略有不同:
-
cat:在现有维度上拼接,不会增加新维度。
-
stack:在新维度上堆叠,会增加一个维度。