【扩散模型(十三)】Break-A-Scene 可控生成,原理与代码详解(中)Cross Attn Loss 代码篇
系列文章目录
- 【扩散模型(一)】中介绍了 Stable Diffusion 可以被理解为重建分支(reconstruction branch)和条件分支(condition branch)
- 【扩散模型(二)】IP-Adapter 从条件分支的视角,快速理解相关的可控生成研究
- 【扩散模型(三)】IP-Adapter 源码详解1-训练输入 介绍了训练代码中的 image prompt 的输入部分,即 img projection 模块。
- 【扩散模型(四)】IP-Adapter 源码详解2-训练核心(cross-attention)详细介绍 IP-Adapter 训练代码的核心部分,即插入 Unet 中的、针对 Image prompt 的 cross-attention 模块。
- 【扩散模型(五)】IP-Adapter 源码详解3-推理代码 详细介绍 IP-Adapter 推理过程代码。
- 【可控图像生成系列论文(四)】IP-Adapter 具体是如何训练的?1公式篇
- 【扩散模型(六)】IP-Adapter 是如何训练的?2 源码篇(IP-Adapter Plus)
- 【扩散模型(七)】Stable Diffusion 3 diffusers 源码详解2 - DiT 与 MMDiT 相关代码(上)
- 【扩散模型(八)】Stable Diffusion 3 diffusers 源码详解2 - DiT 与 MMDiT 相关代码(下)
- 【扩散模型(九)】IP-Adapter 与 IP-Adapter Plus 的具体区别是什么?
- 【扩散模型(十)】IP-Adapter 源码详解 4 - 训练细节、具体训了哪些层?
- 【扩散模型(十一)】SD1.5 / SDXL / SD3 / Flux 整体区别梳理汇总,扩散与整流(Rectified Flow)的区别
- 【扩散模型(十二)】Break-A-Scene 可控生成,原理与代码详解(上)原理篇
文章目录
- 系列文章目录
- 前言
- 1. Cross-Attn Loss
- 1.1 Cross-Attn Map 怎么来的?
- (1)注册 Attn Processor(用 P2PCrossAttnProcessor 类来重新定义)
- (2)为什么要调用用 P2PCrossAttnProcessor?
- (3)self.controller = AttentionStore()
- 1.2 Mask Map 怎么跟 Cross-Attn Map 对应上的?
- (1)整体对应的流程
- (2)训练过程中的对齐
- (3) 可视化和验证
前言
- 上篇介绍了 Break-A-Scene 的整体技术要点,本文则分析其对应的关键代码。
- 方法采用的 base model 是 stable-diffusion-2-1-base。
- 之前说了这个方法主要是 Textual Inversion + Dream Booth(从训练到的模型参数),再从 Attention loss 的角度来看,还参考了 P2P (Prompt-to-Prompt Image Editing
with Cross Attention Control)的核心思想——SD 的 Attn Map 中存在语义对齐。 - 这里的“语义对齐”是指,per word 是可以通过 Attn 对应到 image 中的 regional spaces。
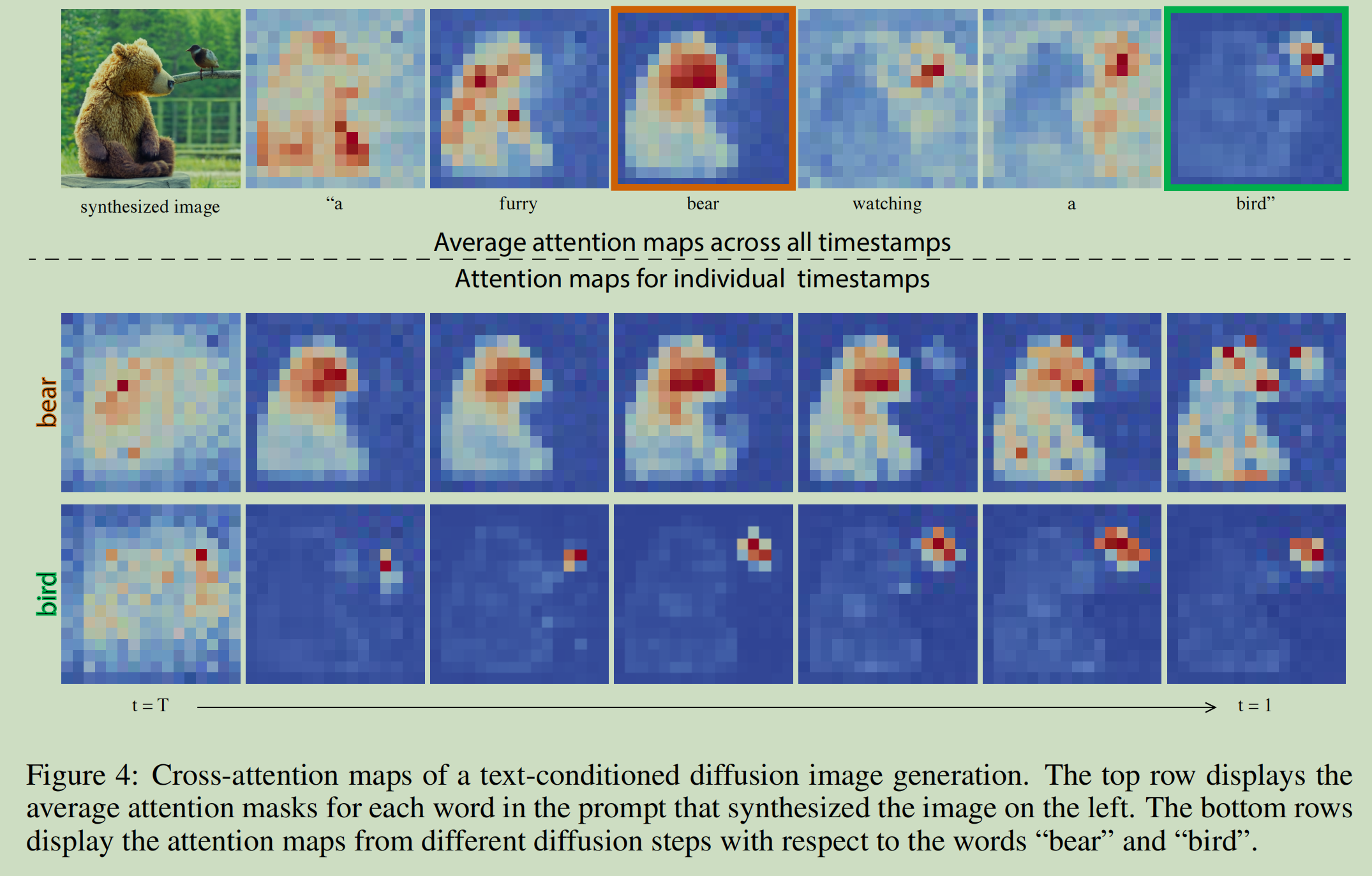
以下代码为 https://github.com/google/break-a-scene 的 train.py
1. Cross-Attn Loss
1.1 Cross-Attn Map 怎么来的?
核心调用链: self.unet -> P2PCrossAttnProcessor(self.controller) -> AttentionStore 以计算注意力分数。
(1)注册 Attn Processor(用 P2PCrossAttnProcessor 类来重新定义)
当执行 self.unet(noisy_latents, timesteps, encoder_hidden_states) 时,代码会调用UNet模型进行前向传播,而 UNet 内部使用了注意力机制。
这里的调用流程是这样的:
- 当调用
self.unet(...)时,开始执行UNet的前向传播 - UNet内部包含多个注意力块(attention blocks)
- 在处理这些注意力块时,会调用
CrossAttention类的forward方法 - 在
CrossAttention的forward方法中,会计算注意力分数,即调用get_attention_scores方法 - 由于训练脚本中重新定义了注意力处理器(P2PCrossAttnProcessor),所以会执行这个自定义处理器中的逻辑
具体原因是在脚本的register_attention_control方法中(约1437行),替换了UNet中的注意力处理器:
def register_attention_control(self, controller):attn_procs = {}cross_att_count = 0for name in self.unet.attn_processors.keys():# ... (省略部分代码)cross_att_count += 1attn_procs[name] = P2PCrossAttnProcessor(controller=controller, place_in_unet=place_in_unet)self.unet.set_attn_processor(attn_procs)controller.num_att_layers = cross_att_count
这段代码将UNet中的注意力处理器替换为自定义的P2PCrossAttnProcessor,用于监控和控制注意力分数。当UNet在前向传播过程中计算注意力时,就会调用这个自定义的处理器。
(2)为什么要调用用 P2PCrossAttnProcessor?
P2PCrossAttnProcessor 和标准的 CrossAttnProcessor 的主要区别是在注意力计算过程中引入了额外的控制机制。让我详细解释这两者的差异:
- 标准的 CrossAttnProcessor
标准的 CrossAttnProcessor 是 diffusers 库中的默认注意力处理器,它的主要功能是执行标准的自注意力或交叉注意力计算。它的工作流程为:
- 将输入转换为查询(query)、键(key)和值(value)
- 计算注意力分数
- 应用注意力分数到值向量上
- 输出结果
这是扩散模型中的标准操作,没有任何额外的控制或监控机制。
- P2PCrossAttnProcessor(Break-a-Scene 中的自定义处理器)
P2PCrossAttnProcessor 在 Break-a-Scene 项目中是一个自定义的注意力处理器,它继承了标准处理器的功能,但添加了一个关键的功能:
# one line change
self.controller(attention_probs, is_cross, self.place_in_unet)
这一行是两者最关键的区别。在计算完注意力分数后,P2PCrossAttnProcessor 将这些分数传递给了一个 controller 对象,让它能够:
- 监控注意力分数:记录模型在不同位置和不同时间步的注意力分布
- 存储注意力信息:将注意力信息存储在
controller.attention_store中 - 可能修改注意力分数:虽然在这个实现中没有直接修改,但这种架构允许在未来扩展来直接干预注意力分数
(3)self.controller = AttentionStore()
注意力分数(attention scores)经过softmax归一化后就形成了注意力概率分布(attention probabilities),这个概率分布通常被称为注意力图(attention map)。
具体来说:
-
注意力分数(Attention Scores):是查询(Q)和键(K)的点积,通常还会乘以一个缩放因子(1/√d_k),计算公式为
(Q·K^T)/√d_k。这些是原始的、未归一化的分数。 -
注意力概率/注意力图(Attention Probabilities/Map):是将注意力分数通过softmax函数归一化后的结果,确保所有值都是0到1之间,且总和为1。计算公式为
softmax((Q·K^T)/√d_k)。这个概率分布表示每个位置的相对重要性。
在Break-a-Scene中,attention_probs 变量就是经过softmax后的注意力概率,也就是注意力图:
attention_probs = attn.get_attention_scores(query, key, attention_mask)
这个 attention_probs 被传递给控制器并存储起来:
self.controller(attention_probs, is_cross, self.place_in_unet)
当在代码中可视化或分析这些注意力信息时,它们通常被称为"attention maps",因为它们可以重塑为2D图像,显示不同空间位置的注意力分布。这些注意力图对于理解模型如何将文本token(如"creature")关联到图像的特定区域非常有价值。
1.2 Mask Map 怎么跟 Cross-Attn Map 对应上的?
在Break-a-Scene中,掩码图(Mask Maps)与交叉注意力图(Cross-Attention Maps)的对应关系是该方法的核心。下面是对应过程的详细介绍:
(1)整体对应的流程
-
数据准备阶段
首先,每个训练样本包含(/path/break-a-scene/examples中):- 一张图像(
img.jpg) - 多个对象的掩码(
mask0.png,mask1.png等) - 每个掩码对应一个token(如"creature", “bowl”, “stone”)
- 一张图像(
-
下采样和尺寸匹配
在训练过程中,原始掩码需要与注意力图的尺寸匹配。这通过下采样完成:
# 从原始尺寸(通常是512x512)下采样到注意力图的尺寸(16x16) GT_masks = F.interpolate(input=batch["instance_masks"][batch_idx], size=(16, 16))注意力图的尺寸通常是16×16,因为在UNet的中间层,特征图大小通常被下采样到这个尺寸。
-
Token到掩码的关联
每个placeholder token对应一个对象掩码:
for mask_id in range(len(GT_masks)):# 获取当前placeholder token的IDcurr_placeholder_token_id = self.placeholder_token_ids[batch["token_ids"][batch_idx][mask_id]]# 在输入的token序列中找到这个token的位置asset_idx = ((batch["input_ids"][curr_cond_batch_idx] == curr_placeholder_token_id).nonzero().item())# 提取这个token对应的注意力图asset_attn_mask = agg_attn[..., asset_idx]asset_attn_mask = asset_attn_mask / asset_attn_mask.max()# 计算这个注意力图与对应的ground truth掩码之间的MSE损失attn_loss += F.mse_loss(GT_masks[mask_id, 0].float(), asset_attn_mask.float(), reduction="mean")这个过程做了以下几件事:
- 找到当前掩码对应的token ID
- 在输入序列中定位这个token的位置
- 提取这个token位置对应的注意力图(即这个token对所有空间位置的注意力权重)
- 将这个注意力图与ground truth掩码进行比较,计算损失
-
聚合注意力
为了提高准确性,Break-a-Scene会聚合UNet中不同层的注意力图:
def aggregate_attention(self, res: int, from_where: List[str], is_cross: bool, select: int):out = []attention_maps = self.get_average_attention()num_pixels = res**2for location in from_where:for item in attention_maps[f"{location}_{'cross' if is_cross else 'self'}"]:if item.shape[1] == num_pixels:cross_maps = item.reshape(self.args.train_batch_size, -1, res, res, item.shape[-1])[select]out.append(cross_maps)out = torch.cat(out, dim=0)out = out.sum(0) / out.shape[0]return out这会收集并平均UNet中多个位置(up, mid, down)的交叉注意力图,提供更全面的注意力表示。
(2)训练过程中的对齐
在训练过程中,通过最小化注意力图与ground truth掩码之间的MSE损失,模型学会将特定token的注意力集中在对应的对象区域:
attn_loss = self.args.lambda_attention * (attn_loss / self.args.train_batch_size)
logs["attn_loss"] = attn_loss.detach().item()
loss += attn_loss
随着训练的进行,交叉注意力图会逐渐对齐到掩码上,这意味着:
- token “creature” 的注意力会集中在生物的区域
- token “bowl” 的注意力会集中在碗的区域
- token “stone” 的注意力会集中在石头的区域
(3) 可视化和验证
为了监控这种对齐,Break-a-Scene会定期保存注意力可视化结果:
self.save_cross_attention_vis(last_sentence,attention_maps=agg_attn.detach().cpu(),path=os.path.join(img_logs_path, f"{global_step:05}_step_attn.jpg")
)
这些可视化显示了每个token对应的注意力热图,帮助研究人员了解模型是否正确地学习了token与空间区域的关联。
通过这种方式,Break-a-Scene建立了text-to-image模型中token与图像区域之间的明确对应关系,从而实现了对图像不同区域的精确控制。