[特殊字符] 大模型微调实战:通过 LoRA 微调修改模型自我认知 [特殊字符]✨
🎯 本文目标
基于 Qwen1.5-1.8B-Chat 模型进行微调,修改模型自我认证!
🔹 修改前:当用户问"你是谁?"时,模型会回答:
"我是阿里云自主研发的超大规模语言模型,我叫通义千问。"
🔹 修改后:我们希望模型回答:
"我是 Archer,由 意琦行 研发。"
1. 🏋️♀️ 训练相关概念复习
上一篇文章 分享了模型训练的相关概念,这里简单复习一下:
ChatGPT 是如何炼成的?
训练一个大模型一般可以分为三步:
-
预训练(Pre Training,PT):
-
提供海量数据,通过无监督预训练
-
花费大量算力得到一个基座模型
-
例如:Llama 3 在 24K GPU 集群上训练,使用了 15T 的数据
-
-
指令微调(Supervised Fine-Tuning, SFT):
-
在基座模型上微调,让模型适应特定任务
-
使用人类准备的问答对话数据
-
-
强化学习(RLHF):
-
通过人类反馈优化生成质量
-
遵循 3H 原则:Helpful、Honest、Harmless
-
🔧 微调方法
主流微调方法:
-
全量参数更新(FFT):更新所有参数,资源消耗大
-
参数高效微调(PEFT):只更新部分参数,效率高
-

PEFT 主要方法: (论文《Scaling Down to Scale Up》中详细介绍了40+种方法)
当前主流PEFT方法:Prompt Tuning、Prefix Tuning、LoRA、QLoRA
2. ⚙️ 安装 LLaMAFactory
环境准备:
-
Python 3.10.6
-
NVIDIA A40 GPU
git clone -b v0.8.1 https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -e .[torch,metrics]
3. 📦 准备模型和数据集
下载模型:
apt install git-lfs -y git lfs install git lfs clone https://www.modelscope.cn/qwen/Qwen1.5-1.8B-Chat.git
准备数据集:
使用内置的 identity 数据集,用于修改模型自我认知。
替换变量:
sed -i 's/{{name}}/Archer/g; s/{{author}}/意琦行/g' data/identity.json
修改后示例:
{"instruction": "hi","input": "","output": "Hello! I am Archer, an AI assistant developed by 意琦行."
}
4. 🚀 开始微调!
执行微调命令:
modelPath=models/Qwen1.5-1.8B-Chat llamafactory-cli train \--model_name_or_path $modelPath \--stage sft \--do_train \--finetuning_type lora \--template qwen \--dataset identity \--output_dir ./saves/lora/sft \# ...其他参数省略...
📊 训练结果分析:
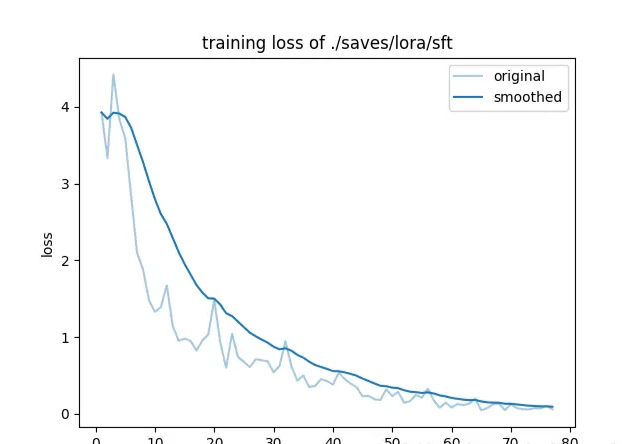
-
Loss曲线:成功收敛
-
评估指标:
predict_bleu-4 = 86.0879 predict_rouge-1 = 91.5523
5. 🧪 测试效果
原始模型:
{"content": "我是来自阿里云的大规模语言模型,我叫通义千问。"
}
微调后模型:
{"content": "您好,我是 Archer,由 意琦行 开发,旨在为用户提供智能化的回答和帮助。"
}
🎉 成功修改了模型的自我认知!
6. 📝 总结
本文通过一个有趣的Demo,展示了如何使用LLaMAFactory进行LoRA微调:
-
准备模型和数据集
-
注册数据集
-
执行微调
-
分析训练结果
-
测试模型效果
💡 小贴士:微调就像教AI说"方言",既要保留通用能力,又要学会特定表达。调参就像烹饪,火候很重要哦!
🤔 思考题:如果你想教AI用莎士比亚风格写作,该怎么准备数据集呢?
📚 相关资源:
-
LLaMA-Factory GitHub
-
Qwen模型库