【从零实现高并发内存池】Page Cache 从理解设计到全面实现
📢博客主页:https://blog.csdn.net/2301_779549673
📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 JohnKi 原创,首发于 CSDN🙉
📢未来很长,值得我们全力奔赴更美好的生活✨


文章目录
- 🏳️🌈一、Page Cache
- 1.1 整体设计
- 1.2 核心功能
- 1.3 具体实现
- 👥总结
🏳️🌈一、Page Cache
1.1 整体设计
page cache 与 central cache结构的相同之处
CentralCache:每个桶(SpanList)维护一个 Span 链表,同一链表中的 Span 切分相同大小的小块。
PageCache:每个页数桶(如 1 页、2 页)维护一个 Span 链表,按页数分类管理空闲内存块。
两者都是哈希桶结构,每个桶都是挂着一个个span,这些span都是用双向链表连接起来的
page cache 与 central cache结构的不同之处

CentralCache 的 SpanList[0] 管理所有 8B 对象对应的 Span。
PageCache 的 SpanList[1] 管理所有 1 页的 Span,SpanList[2] 管理 2 页的 Span。
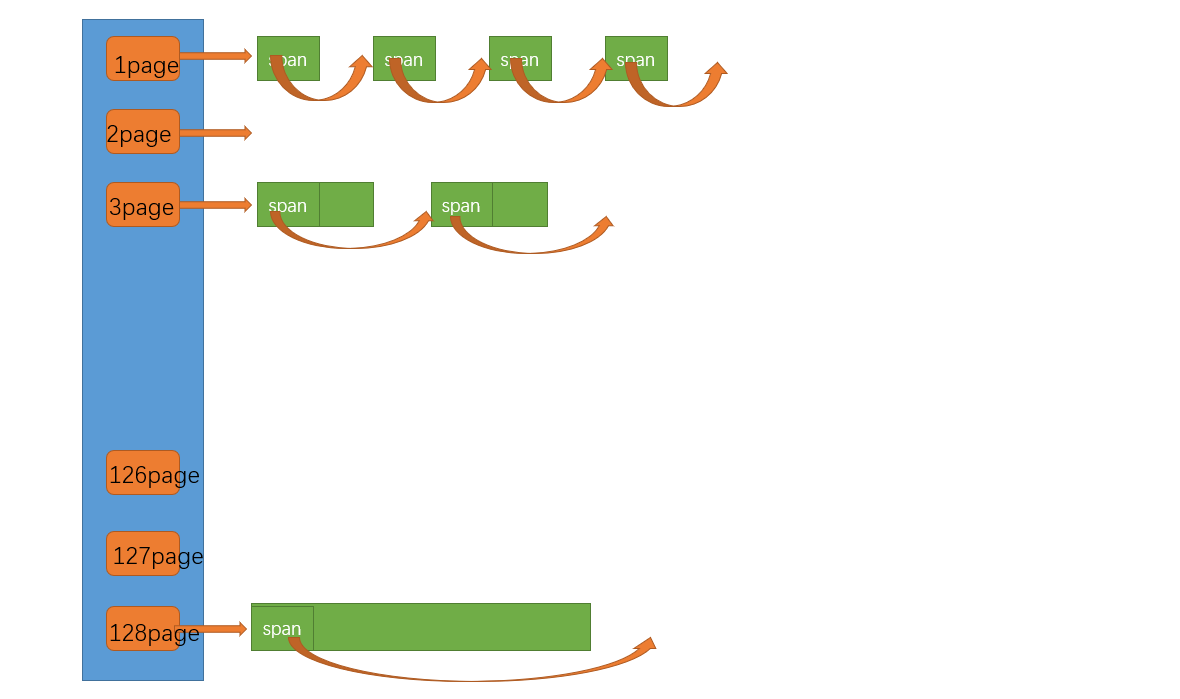
为什么这里最大挂128页的span呢?
因为在内存池设计中,线程通过 ThreadCache 申请单个对象的最大内存为 256KB,这是由代码中的宏定义 MAX_BYTES 明确限制
而 128页 可以被切成 4 个 256KB 的对象,因此是足够的。当然,如果你想在 page cache 中挂更大的 span 也是可以的,根据具体的需求进行设置即可。
page cache的最大值取决于个人,我们这里为了方便计算,就设置 1 - 128 下标的哈希桶,分别对应 1 - 128 页。第0页空出来
static const size_t NPAGES = 129;
// 最大挂128页的span,为了让桶号与页号对应起来,我们可以将第0号桶空出来,因此我们需要将哈希桶的个数设置成129。
Page Cache 的单例模式
在内存池设计中,将 PageCache 和 CentralCache 设置为单例模式(Singleton)是经过深思熟虑的设计决策,其核心意义在于 统一资源管理、减少竞争、保证全局一致性。以下是具体分析:

单例模式对 PageCache 的意义
- 全局唯一的物理内存管理
PageCache 直接对接操作系统(如通过 VirtualAlloc 或 mmap),负责 分配/释放物理内存页。
若允许多个实例存在:- 不同实例可能重复分配同一物理内存页,导致 内存重叠 或 数据损坏。
- 无法正确合并相邻空闲 Span(因多个实例无法感知彼此的内存块状态)。
- 合并碎片的唯一性
PageCache 的 核心职责 是合并相邻空闲 Span,减少外碎片。
必须通过全局唯一的实例维护所有 Span 的物理地址和状态,否则合并逻辑无法正确工作。
// PageCache 通过单例保证全局唯一
class PageCache{public:// 管理物理内存页的全局分配与合并,必须保证所有线程通过同一个实例操作内存映射和空闲链表。static PageCache* GetInstance() {return &_sInst;}// 获取一个 k 页的 spanSpan* NewSpan(size_t k);std::mutex _pageMtx;private:SpanList _spanLists[NPAGES];PageCache(){}PageCache(const PageCache&) = delete;static PageCache _sInst;
};
为什么需要在hpp文件中额外声明 _sInst
在 C++ 中,静态成员变量(Static Member Variable)必须在两个地方声明:
1.在类的定义中声明为 static
2.在类的外部进行定义和初始化。为静态成员分配实际内存空间
1.2 核心功能
在内存池设计中,PageCache 是内存管理的底层中枢,负责 物理内存的全局分配、合并与碎片优化。以下是其核心功能的详细解析:
1. 管理物理内存的全局分配
PageCache 直接对接操作系统,通过 SystemAlloc(如 VirtualAlloc 或 mmap)申请 大块物理内存(默认为 128 页),并将其初始化为 Span 对象。
Span* bigSpan = new Span;
void* ptr = SystemAlloc(NPAGES - 1); // 申请 128 页内存
bigSpan->_PAGEID = (PAGE_ID)ptr >> PAGE_SHIFT;
bigSpan->_n = NPAGES - 1;
2. 按需分割大 Span
当 CentralCache 请求 k 页内存时,PageCache 优先从现有 Span 中切分,减少直接向系统申请的次数。
- 检查 k 页链表是否非空,直接返回。
- 若 k 页链表为空,遍历更大的页链表(k+1 到 NPAGES-1),找到可分割的 Span。
- 切分 Span 为 k 页和 i-k 页(i 为原 Span 页数),剩余部分挂回对应链表。
3. 维护按页数分类的 Span 链表
每个链表存储相同页数的空闲 Span。例如:_spanLists[3] 存储所有 3 页的 Span。
- 插入:切分后的剩余 Span 挂回对应链表。
- 弹出:直接取用链表中的 Span。

1.3 具体实现
1. 获取非空的span
thread cache向central cache申请对象时,central cache需要先从对应的哈希桶中获取到一个非空的Span,然后从这个非空的Span中取出指定大小的对象返回给thread cache。
遍历central cache对应哈希桶中的双链表,如果该双链表中有非空的Span,那么直接将Span返回即可,没有 span 的话,就去 Page Cache 里要
2.那具体是向page cache申请多大的内存块呢?
我们需要根据 thread cache 所申请的空间大小 size,计算出 central cache 一次应该向 page cache 申请几页的内存块
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
我们可以通过 NumMoveSize 先得到 thread cache 要从中心缓存中获取多少个对象,然后算出总的对象占的内存,就得出了所需字节,利用位运算,按每页8K的大小,可以得到所需页数。 不足1页时,按一页计算
static size_t NumMovePage(size_t size) {// 计算出thread cache一次向central cache申请对象的个数上限size_t num = NumMoveSize(size);// num 个size 大小的对象所需的字节数size_t npage = num * size;npage >>= PAGE_SHIFT;if(npage == 0)npage = 1;return npage;}
PAGE_SHIFT代表页大小转换偏移,我们这里以页的大小为8K为例,PAGE_SHIFT的值就是13。
3.先不管 page cache 里是怎么给的内存块,假设我们现在已经得到 page cache 返回的页号如何找到一个span所管理的内存块呢?
首先需要计算出该span的起始地址,我们可以用这个span的起始页号乘以一页的大小即可得到这个span的起始地址,然后用这个span的页数乘以一页的大小就可以得到这个span所管理的内存块的大小,用起始地址加上内存块的大小即可得到这块内存块的结束位置。
// 这里的 span 是一个大块内存,_PAGEID 是页号,_n 是页数// 这里 start 和 end 的类型必须要用 char* 来表示,因为我们要对内存进行字节级别的操作// void* 不能进行算术运算,因为 void 没有大小类型,编译器无法进行步长判断// 也不能用 int* 或者 其他的指针// 因为是字节级的操作,只有 char* +1 也是跳转1个字节,但是 int* 就是跳转4个字节char* start = (char*)(span->_PAGEID << PAGE_SHIFT);size_t bytes = span->_n << PAGE_SHIFT;char* end = start + bytes;
这里还有一点需要注意,start以及end必须用 char* 来表示,原因在于,char* 是一个字节的大小,我们需要利用 span 保存的页的大小,进行算数运算得到结束位置的地址
再之后就是根据这个span里每个节点的大小需求,切开这个内存条,一个个尾插
// 获取一个非空的 span
Span* CentralCache::GetOneSpan(SpanList& list, size_t size) {// 查看当前的 spanlist 中是否有空闲的 spanSpan* it = list.Begin();while (it != list.End()) {if(it ->_freeList != nullptr)return it;// 这里的 _freeList 是指 span 中的自由链表头指针,_freeList != nullptr // 说明这个 span 中有未分配的小块内存it = it->_next;}// 如果没有空闲的 span,则需要申请一个新的 span// 只能找 page cache 要// 虽然此时central cache的这个桶当中是没有内存供其他thread cache申请的,// 但thread cache除了申请内存还会释放内存,// 如果在访问 page cache 前将central cache对应的桶锁解掉,// 那么此时当其他thread cache想要归还内存到central cache的这个桶时就不会被阻塞list._mtx.unlock();PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));PageCache::GetInstance()->_pageMtx.unlock();// 接下来是对刚刚获取的 span 进行切分,// 这会这个 span 还没有挂到桶上,其他线程访问不到,所以不需要加锁// 这里的 span 是一个大块内存,_PAGEID 是页号,_n 是页数// 这里 start 和 end 的类型必须要用 char* 来表示,因为我们要对内存进行字节级别的操作// void* 不能进行算术运算,因为 void 没有大小类型,编译器无法进行步长判断// 也不能用 int* 或者 其他的指针// 因为是字节级的操作,只有 char* +1 也是跳转1个字节,但是 int* 就是跳转4个字节char* start = (char*)(span->_PAGEID << PAGE_SHIFT);size_t bytes = span->_n << PAGE_SHIFT;char* end = start + bytes;// 把大块内存切成自由链表连接起来// 1. 先切一块下来去做头,方便尾插span->_freeList = start;start += size;void* tail = span->_freeList;int i = 1;while (start < end) {++i;NextObj(tail) = start;tail = NextObj(tail);start += size;}// 2. 切好 span 后,需要把 span 挂到桶里面去,得加锁list._mtx.lock();list.PushFront(span);return span;
}
4.从 Page Cache 中获取K页的内存
当我们调用上述的GetOneSpan从central cache的某个哈希桶获取一个非空的span时,如果遍历哈希桶中的双链表后发现双链表中没有span,或该双链表中的span都为空,那么此时central cache就需要向page cache申请若干页的span了,下面我们来分析如何从page cache获取一个k页的span。
因为page cache是直接按照页数进行映射的,因此我们要从page cache获取一个k页的span,就应该 直接先去找page cache的第k号桶, 如果第k号桶中有span,那我们直接头删一个span返回给central cache就行了。所以我们这里需要再给 SpanList类添加对应的Empty和PopFront函数。
class SpanList {public:SpanList() {_head = new Span;_head->_next = _head;_head->_prev = _head;}// 获取开头节点Span* Begin(){return _head->_next;}// 获取哨兵位Span* End(){return _head;}// 判空bool Empty() {return _head->_next == _head;}// 返回头结点Span* PopFront() {Span* front = _head->_next;assert(front != _head);Erase(front);return front;}private:Span* _head;public:std::mutex _mtx; // 桶锁
};
如果
page cache的第k号桶中没有span,我们就应该继续找后面的桶,只要后面任意一个桶中有一个n页的span,我们就可以将其切分成一个k页的span和一个n-k页的span,然后将切出来k页span返回给central cache,再将n-k页的span挂接到page cache的第n-k号桶中。
// 检查一下后面的桶里面有没有 span,如果有可以把他进行切分for (size_t i = k + 1; i < NPAGES; ++i) {// 如果后面的桶里面有 span,这个 span 是肯定大于 k 页的if (!_spanLists[i].Empty()) {// 弹出第 i 个桶的第一个 spanSpan* nSpan = _spanLists[i].PopFront();// 进行切分,切分成一个 k 页的 span 和一个 i-k 页的 spanSpan* kSpan = new Span;kSpan->_PAGEID = nSpan->_PAGEID;kSpan->_n = k;nSpan->_PAGEID += k;nSpan->_n -= k;_spanLists[nSpan->_n].PushFront(nSpan);return kSpan;}}
那如果 k 及其之后都没有span呢,那就只能去堆中申请了
// 走到这个位置就说明后面没有大页的 span 了// 就需要去找堆要一个 128 页的 spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_PAGEID = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;_spanLists[bigSpan->_n].PushFront(bigSpan);return NewSpan(k);
有一个问题:当central cache向page cache申请内存时,central cache对应的哈希桶是处于加锁的状态的,那在访问page cache之前我们应不应该把central cache对应的桶锁解掉呢
其实最好是解锁掉。因为central cache 此时是没有内存的,必须要去 page cache中去申请,所以此时 thread cache 无法从 central cache 中获取任何内存。可是如果 thread cache 有内存需要返回呢,那不就会因为向 page cahce 申请内存而被阻塞吗,进而造成堵塞。
所以我们可以在确认要向 page cache 申请内存的时候将 central cache 的这个span 的锁给解了,然后等切分完之后,需要将其插进 central cache 的哈希桶的时候再锁上,挂完了在解锁。从而有效避免了申请内存这期间的阻塞
// 获取一个非空的 span
Span* CentralCache::GetOneSpan(SpanList& list, size_t size) {// 查看当前的 spanlist 中是否有空闲的 spanSpan* it = list.Begin();while (it != list.End()) {if(it ->_freeList != nullptr)return it;// 这里的 _freeList 是指 span 中的自由链表头指针,_freeList != nullptr 说明这个 span 中有未分配的小块内存it = it->_next;}// 如果没有空闲的 span,则需要申请一个新的 span// 只能找 page cache 要// 虽然此时central cache的这个桶当中是没有内存供其他thread cache申请的,// 但thread cache除了申请内存还会释放内存,// 如果在访问 page cache 前将central cache对应的桶锁解掉,// 那么此时当其他thread cache想要归还内存到central cache的这个桶时就不会被阻塞list._mtx.unlock();PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));PageCache::GetInstance()->_pageMtx.unlock();// 接下来是对刚刚获取的 span 进行切分,// 这会这个 span 还没有挂到桶上,其他线程访问不到,所以不需要加锁// 这里的 span 是一个大块内存,_PAGEID 是页号,_n 是页数// 这里 start 和 end 的类型必须要用 char* 来表示,因为我们要对内存进行字节级别的操作// void* 不能进行算术运算,因为 void 没有大小类型,编译器无法进行步长判断// 也不能用 int* 或者 其他的指针// 因为是字节级的操作,只有 char* +1 也是跳转1个字节,但是 int* 就是跳转4个字节char* start = (char*)(span->_PAGEID << PAGE_SHIFT);size_t bytes = span->_n << PAGE_SHIFT;char* end = start + bytes;// 把大块内存切成自由链表连接起来// 1. 先切一块下来去做头,方便尾插span->_freeList = start;start += size;void* tail = span->_freeList;int i = 1;while (start < end) {++i;NextObj(tail) = start;tail = NextObj(tail);start += size;}// 2. 切好 span 后,需要把 span 挂到桶里面去,得加锁list._mtx.lock();list.PushFront(span);return span;
}👥总结
本篇博文对 【从零实现高并发内存池】Page Cache 从理解设计到全面实现 做了一个较为详细的介绍,不知道对你有没有帮助呢
觉得博主写得还不错的三连支持下吧!会继续努力的~