用 DeepSeek 精准解析,PDF 一键转电子书!
经常需要阅读大量的 PDF 文档,但在移动设备上阅读 PDF 通常体验极差。屏幕小、排版固定,需要不断放大缩小,眼睛容易疲劳,长时间阅读简直是一种折磨。
虽有不少 PDF 转换工具,但对扫描书籍支持不佳,经常丢失文本结构,混入页眉页脚,跨页内容断开,转换后反而更难阅读,让人头疼不已。
最近在 GitHub 上我发现了一个名为 PDF Craft 的开源工具。
它专门针对扫描书籍的 PDF 文件进行智能处理,能够精准提取正文,过滤无关元素。
并且能一键转换为更适合阅读的 Markdown 或 EPUB 格式,彻底解决了阅读困扰。

主要功能
PDF 转 Markdown:使用本地 AI 模型将 PDF 转为 Markdown 格式,无需联网调用 LLM 服务,仅凭本地算力即可完成。遇到图表、公式等内容,会自动截图并插入到 Markdown 文件中。
PDF 转 EPUB:将 PDF 转换为带目录和分章节的 EPUB 电子书,过程中会通过 LLM 读取注释和引用信息,并在 EPUB 中以新的格式呈现。

多重 OCR:通过对同一页面进行多次 OCR 扫描,提高文字识别质量,避免因字迹模糊而丢失内容。
LLM 高级设置:支持断线重连、超时设置、创造力调整等参数配置,可在质量和费用之间寻求平衡。
GPU 加速支持:可配置使用 CUDA 加速处理,大幅提升转换速度。
安装指南
安装 PDF Craft 非常简单,只需几个命令就能搞定。首先需要确保系统中已安装 Python 3.10 或更高版本(推荐 3.10.16)。
pip install pdf-craftpip install onnxruntime==1.21.0
如果想使用 GPU 加速处理,需要先准备好 CUDA 环境,然后安装 onnxruntime-gpu:
pip install onnxruntime-gpu==1.21.0使用指南
PDF 转 Markdown 使用方法:
from pdf_craft import PDFPageExtractor, MarkDownWriterextractor = PDFPageExtractor(device="cpu", # 使用 CUDA 加速时改为 device="cuda"model_dir_path="/path/to/model/dir/path", # AI 模型保存位置)with MarkDownWriter(markdown_path, "images", "utf-8") as md:for block in extractor.extract(pdf="/path/to/pdf/file"):md.write(block)
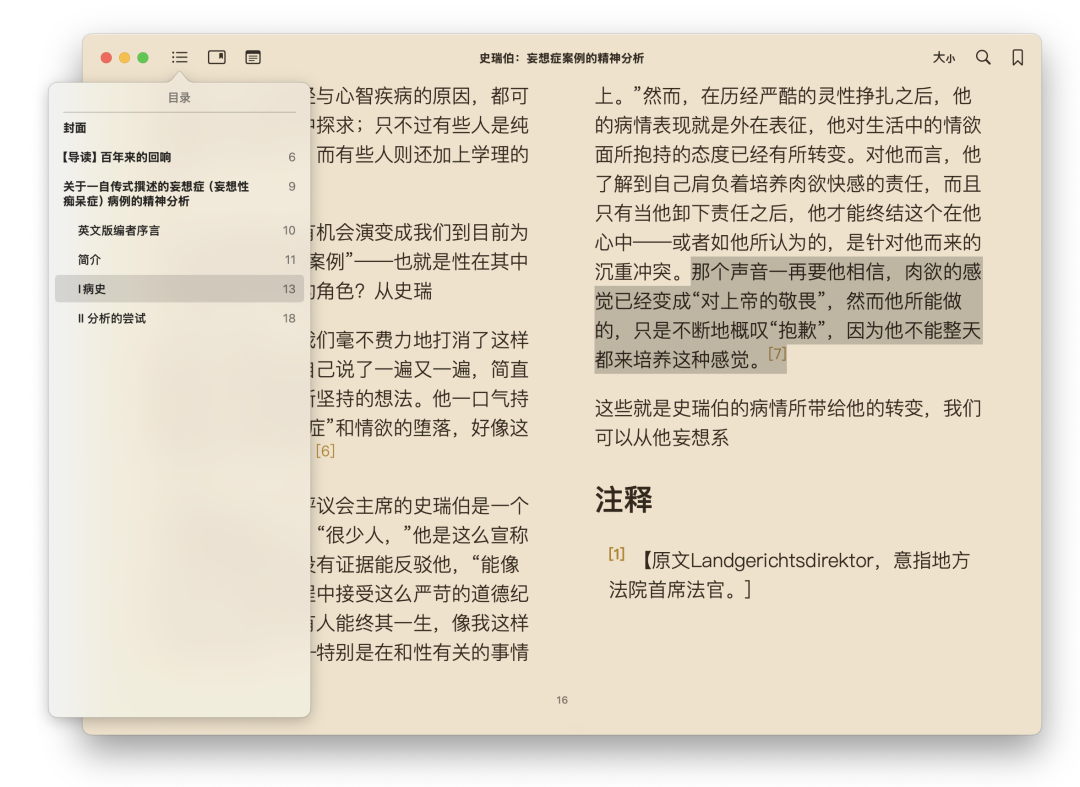
PDF 转 EPUB 使用方法:
from pdf_craft import PDFPageExtractor, LLM, analyse, generate_epub_file# 配置 PDF 页面提取器extractor = PDFPageExtractor(device="cpu",model_dir_path="/path/to/model/dir/path",)# 配置 LLM 服务llm = LLM(key="sk-XXXXX",url="https://api.deepseek.com",model="deepseek-chat",token_encoding="o200k_base",)# 分析 PDF 内容analyse(llm=llm,pdf_page_extractor=extractor,pdf_path="/path/to/pdf/file",analysing_dir_path="/path/to/analysing/dir",output_dir_path="/path/to/output/files",)# 生成 EPUB 文件generate_epub_file(from_dir_path=output_dir_path,epub_file_path="/path/to/output/epub",)

写在最后
通过 PDF Craft,终于可以轻松将扫描 PDF 转换为更适合移动设备阅读的格式。
无论是学习研究时查阅论文,还是日常阅读扫描书籍,都能获得更流畅、更舒适的阅读体验。
这款开源工具极大提高了阅读效率,让 PDF 文档不再成为阅读的障碍!