STM32单片机入门学习——第39节: [11-4] SPI通信外设
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做!
本文写于:2025.04.16
STM32开发板学习——第39节: [11-4] SPI通信外设
- 前言
- 开发板说明
- 引用
- 解答和科普
- 一、SPI外设
- 问题
- 总结
前言
本次笔记是用来记录我的学习过程,同时把我需要的困难和思考记下来,有助于我的学习,同时也作为一种习惯,可以督促我学习,是一个激励自己的过程,让我们开始32单片机的学习之路。
欢迎大家给我提意见,能给我的嵌入式之旅提供方向和路线,现在作为小白,我就先学习32单片机了,就跟着B站上的江协科技开始学习了.
在这里会记录下江协科技32单片机开发板的配套视频教程所作的实验和学习笔记内容,因为我之前有一个开发板,我大概率会用我的板子模仿着来做.让我们一起加油!
另外为了增强我的学习效果:每次笔记把我不知道或者问题在后面提出来,再下一篇开头作为解答!
开发板说明
本人采用的是慧净的开发板,因为这个板子是我N年前就买的板子,索性就拿来用了。另外我也购买了江科大的学习套间。
原理图如下
1、开发板原理图

2、STM32F103C6和51对比

3、STM32F103C6核心板
视频中的都用这个开发板来实现,如果有资源就利用起来。另外也计划实现江协科技的套件。
下图是实物图

引用
【STM32入门教程-2023版 细致讲解 中文字幕】
还参考了下图中的书籍:
STM32库开发实战指南:基于STM32F103(第2版)

数据手册

解答和科普
一、SPI外设
软件SPI就是我们用代码手动翻转电平,来实现时序,硬件SPI就是使用STM32内部的SPI外设,来实现时序,两种实现发放各有优势。软件实现主打的是方便灵活,硬件实现主打的是高性能,节省软件资源。

硬件自动执行时序,不用手动翻转电平了,节省软件资源。硬件一旦设计出来,不易更改,所以就会导致外设电路的结构和知识点非常多。而且有很多功能,我们基本上很少用到。所以STM32要使用主线加分支的学习方法。先把最常用、最简单的主线知识点给贯通,给它学会了,然后再逐渐细化,在实践中去慢慢探索这些分支,这些学习起来才是比较容易的,所以大家在看手册学习时,有一些感觉非常偏又非常难的知识点,可以先不必探究。先把主线任务学习好,其他的可以之后再研究。
高位先行,I2C和SPI都是高位先行,串口USART时低位先行。
时钟频率: fPCLK / (2, 4, 8, 16, 32, 64, 128, 256),其中PCLK就是外设时钟,APB2的PCLK就是72Mhz,APB1的PCLK是36MHz,比如SPI1是APB2的外设,PLCK=72MHz,那他的SPI时钟频率,最大就是只进行二分频,72M/2=36Mhz。这个频率不是任意指定的,它只能是PCLK执行这些分频之后的数值,最低频率是PCLK的256分频,二是,SPI1和SPI2挂载的总线是不一样的,SPI1(APB2),PCLK=72M; SPI2(APB1),PCLK=36M.
可精简为半双工/单工通信
支持DMA;快速搬运数据;
兼容I2S协议,数字音频信号。
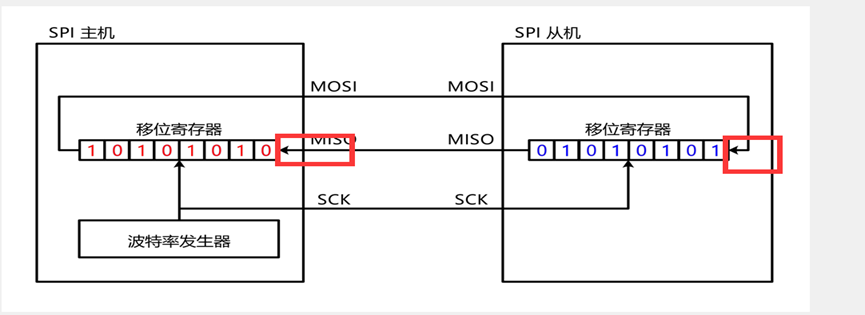
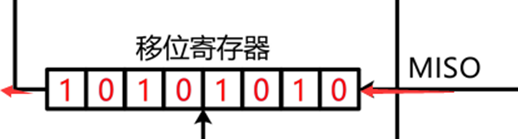
左上角核心部分:移位寄存器,右边的数据低位,一位一位地,从MOSI移出去,然后MISO的数据,一位一位地,移入到左边的数据高位,显然移位寄存器应该是一个右移的状态,所以目前表示的是低位先行的配置,右下角有一个LSBFIRST控制位,这一位可以控制低位先行还是高位先行。

这里MOSI和MISO做了个交叉,这一块主要是用来进行主从模式引脚变换的,这个SPI外设,可以做主机,也可以做从机,做主机是这个交叉就不用,如果STM32作为从机,MOSI,为SI,从机输入,这是就要走交叉这一路,输入到移位寄存器,MISO,为SO,从机输出,这时输出的数据,也走交叉的这一路,输出到MISO.交叉就是,主机和从机的输入输出模式不同,如果要切换主机和从机的话,线路就需要交叉一下。
接下来,上下两个数据缓冲区,就还是我们熟悉的设计,这两个数据缓冲区,实际上就是数据寄存器DR,下面发送缓冲区,就是发送数据寄存器TDR,上面接收缓冲区,就是接收数据寄存器RDR,和串口哪里一样,TDR和RDR占用同一个地址,统一叫做DR,写入DR时,数据从这里,写入到TDR,读取DR时,数据从这里,从RDR读出, 数据寄存器和移位寄存器打配合,可以实现连续的数据流,第一个数据写入到TDR,当移位寄存器没有数据移位时,TDR的数据会立刻传入移位寄存器,开始移位,这个转入时刻,会置状态寄存器TXE为1,表示发送寄存器空,当我们检查TXE置1后,紧跟着,下一个数据,就可以提前写入到TDR里候着了,一但上一个数据发完,下一个数据就可以立刻跟进。然后移位寄存器这里,一但有数据过来了,它就会自动产生时钟,将数据移出去,在移出的过程中MISO的数据也会移入,一旦数据移出完成,数据移入是不是也完成了,这时,移入的数据,就会整体地,从移位寄存器转入到接收缓冲区RDR,这个时刻,会置状态寄存器的RXNE为1,表示接收寄存器非空,当我们检查RXNE置1后,就要尽快把数据从RDR读出来,在下一个数据到来之前,读出RDR,就可以实现连续接收。这就是移位寄存器配合数据寄存器实现连续数据流的过程。简而言之,就是发送数据先写入TDR,再转到移位寄存器发送,发送的同时,接收数据,接收到的数据,转到RDR,我们再从RDR读取数据,移位寄存器配合数据寄存器可以实现无延迟的连续传输。

和之前串口、I2C都差不多的意思,当然这三者也是有一些区别的:
比如这里SPI是全双工,发送和接收同步进行,所以它的数据寄存器,发送和接收是分离的,而移位寄存器,发送和接收可以共用
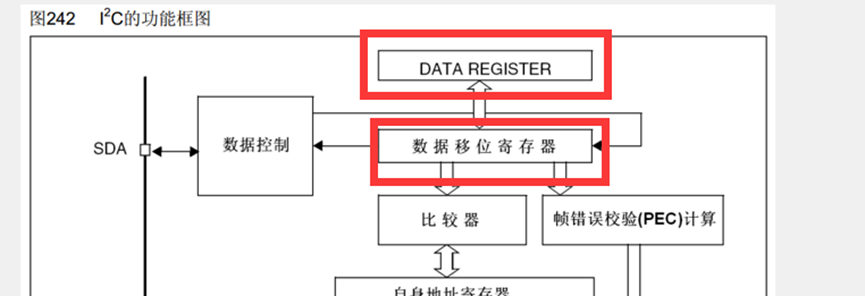
I2C是半双工,发送和接收不会同时进行,所以它的数据寄存器和移位寄存器,发送和接收都是可以共用的,
串口是全双工,并且发送和接收可以异步进行,所以这就要求,它的数据寄存器,发送和接收是分离的,移位寄存器,发送和接收也得是分离的。
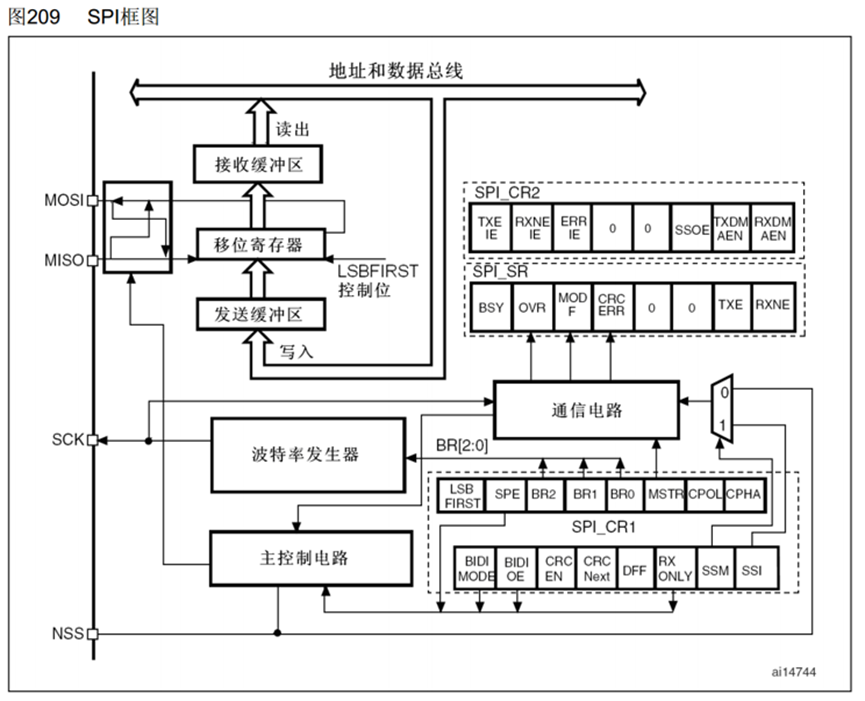
右下角内容就是一些控制逻辑,首先是波特率发生器,这个就是用来产生SCK时钟的,它的内部,主要就是一个分频器,输入时钟是PCLK,72M或36M,经过分频器之后,输出到SCK引脚,当然这里生成的时钟肯定是和移位寄存器同步的了,每产生一个周期的时钟移入移出一个Bit,然后右边,CR1寄存器的三个位BR0、BR1、BR2,用来控制分频系数。

LSBFIRST:决定高位先行还是低位先行;
SPE,是SPI使能,就是SPI_Cmd函数配置的位;
BR配置波特率,就是SCK时钟频率;
MSTR,配置主从模式,1是主模式,0是从模式;
CPOL和CPHA,用来选择SPI的4种模式;
SR状态寄存器,最后两个,TXE,发送寄存器空,RXNE,接收寄存器非空;
NSS引脚,从机有效,并不会用到,实现多主机模型,SS引脚,我们直接使用一个GPIO模拟就行,因为SS引脚很简单,就置一个高低电平就行了。
我们需要把这3个设备的NSS全都建接在起,首先。这个NSS。可以配置为输出或者输入,当配置为输出时,可以输出电平告诉别的设备,我现在要变为主机,你们其他设备都绘我变成从机。不要过来捣乱,当配置输入时,可以接收别设备的信号,当有设备是主机,拉低NSS后,我就无论如何也变不成主机了,这就是他的作用。当这个SSOE=1时,NSS作为输出引脚,并在当前设备变为主设备时,给NSS输出低电平,这个输出的低电平,就是告诉其他设备,我现在是主机了。当主机结束后,SSOE要清0,NSS变为输入;这时输入信号就会跑到右边这里,SSM位决定选择那一路,当选择上面一路时,是硬件NSS模式,也就是说,这时外边如果输入了低电平,那当前的设备就进不了主模式,因为NSS低电平,肯定是外部已经有设备进入主模式了;当数据选择器选择下面一路时,是软件管理NSS输入,NSS是1还是0,由这一位SSI决定。
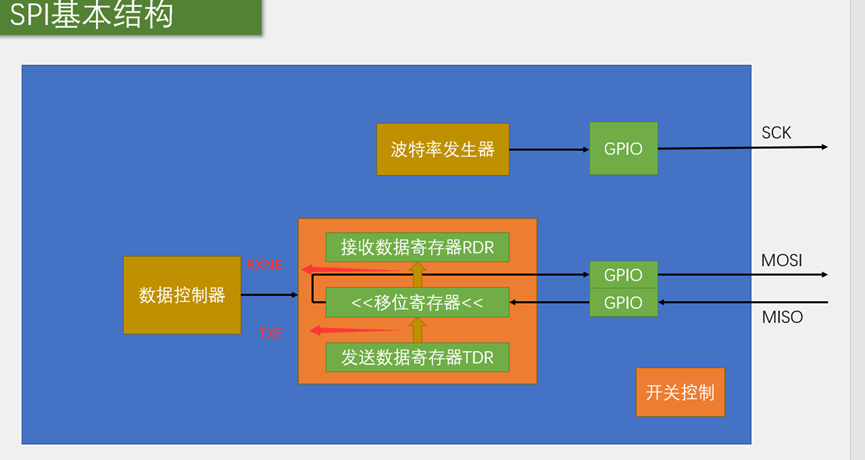
SS用GPIO模拟更方便。
读写DR产生时序的流程:
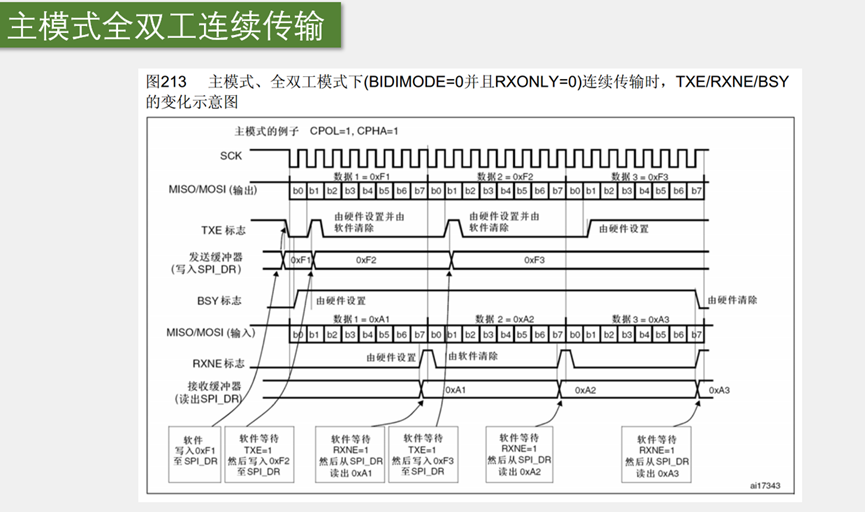
借助缓冲区,数据前仆后继,实现连续数据流的过程。首先,SS置低电平开始时序,在刚开始时,TXE为1,表示TDR空,可以写入数据开始传输,下面指示的第一步是软件写0x F1至SPI_DR,写入之后,TDR变为0xF1,同时TXE变为0,表示TDR已经有数据了,那此时,TDR是等候区,移位寄存器才是真正的发送区,移位寄存器刚开始肯定没有数据,所以在等候区TDR里的F1,就会立刻转入移位寄存器,开始发送, 转入瞬间,置TXE标志为1,表示发送寄存器空,然后移位寄存器有数据了,波形就自动开始生成。在移位产生波形的时候,等候区TDR是空的,为了移位完成时,下一个数据能不间断地跟随,这里我们就要提早把下一个数据写入到TDR里等着,所以第二步是,软件等待至TXE=1,然后写入第二个数据到TDR.F1数据波形结束后,F2转入移位寄存器开始发送,这是TXE=1,我们尽快把下一个数据F3放到TDR等着,如果只想发送三个字节, 写入之后,我们就不需要写入了 ,等到TXE=1,之后一直是1,在最后TXE=1之后,还需呀等待一段时间,F3的波形才能发送完整,等数据完全发送之后,BUSY标志由硬件清除,这次表示,波形发送完成了;
接收的流程:在第一个发送完成时,第一个字节的接收也完成了,接收到的数据1,是A1,这时移位寄存器的数据,整体转入RDR, RDR随后存储的就是A1,转入的同时,RXNE标志位也置1,表示收到数据了,操作时软件等待RXNE=1,=1表示收到数据了,然后从RDR,读出数据1,这就是第一个接收到的数据,接收之后,软件清除RXNE标志位, 然后,当下一个数据2收到之后,RXNE重新置1,我们检测到RXNE=1时,就继续读出RDR,这是第2个数据A2,最后一个字节的时序完全产生之后,数据3才能收到,数据3到最后才能读出来。然后注意一个字节波形收到后,移位寄存器的数据自动转入RDR,会覆盖原有的数据,所以我们读取RDR要及时,否则下一个数据会覆盖。这个是对时序要求高。这个效率高。发送数据1,发送数据2,接收数据1,发送数据3,接收数据2.
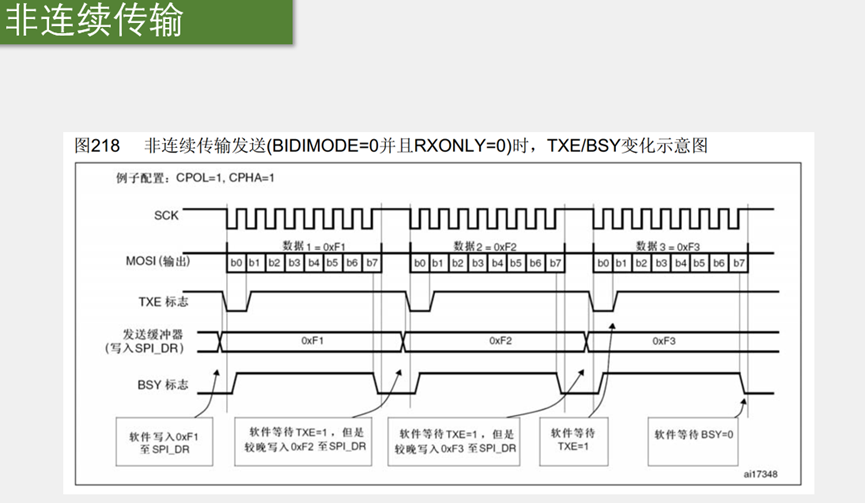
有什么区别:首先,这个配置还是SPI的模式3,SCK默认高电平,如果检测到TXE=1了,TDR为空,就软件写入0xF1至SPI_DR,这时TDR的值变为F1,TXE变为0,目前移位寄存器也是空,所以这个F1会立刻转入移位寄存器开始发送,波形产生,并且TXE置回1,表示你可以发送下一个数据在TDR里等着了,但是,现在区别就来了,在连续模式里,一但TXE=1,就会把下一个数据写入到TDR等着,这样是为了连续传输,数据衔接更紧密,但是这样的话,流程就比较混乱,程序写起来比较复杂,所以在非连续传输里,TXE=1,我们不着急把下一个数据写进去,而是一直等待,等第一个字节时序结束,是不是也意为着接收第一个字节也完成了,这是接收的RXNE会置1,我们等待RXNE置1后,先把第一个接收到的数据读出来,之后再写入下一个字节数据,也就是 这里的软件等待TXE=1,但是较晚写入0xF2至SPI_DR,较晚写入TDR后,数据2开始发送,我们还是不着急写数据3,而是把接收数据2,然后再写入数据3.
第一步,等待TXE为1,第二步,写入发送的数据至TDR,第三步,等待RXNE为1,第四步,读取RDR接收的数据,之后交换第二个字节,重复这4步,这样就可以把这4步封装为一个函数。和之前软件SPI基本是一样的。 只需稍作修改,就可以把软件SPI改成硬件SPI.这就是非连续输出,缺点就是没有及时把下一个数据写入TDR候着,所以等到第一个字节时序完成后,第二个字节还没送过来,那这个数据传输,就会在这里等着,所以这里时钟和数据的时序,在字节与字节之间,会产生间隙,拖慢了整体数据传输的速度。在SCK频率高的时候,间隙拖后腿的现象就比较严重了。
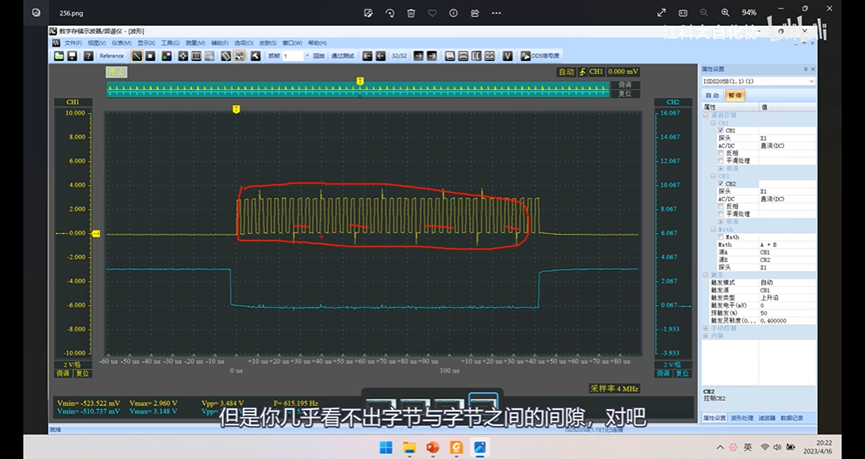
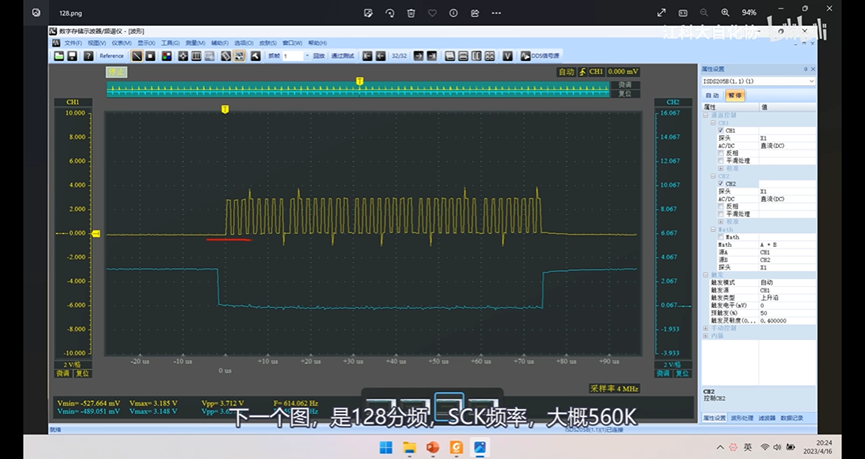
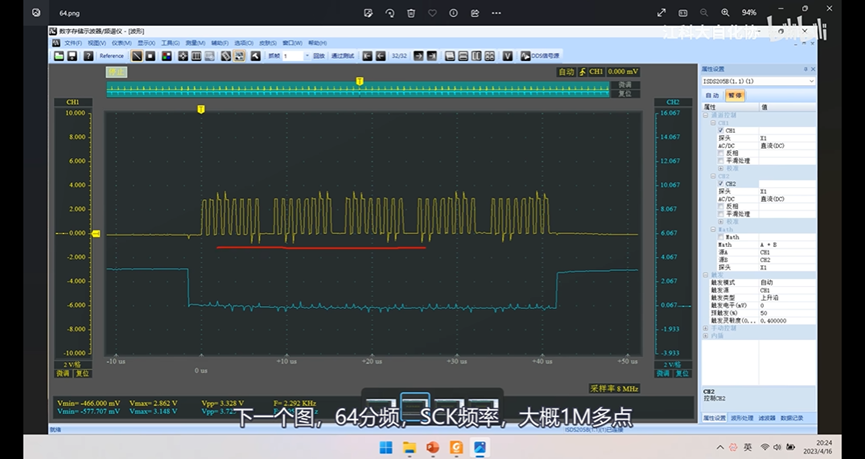
DMA,或者连续传输模式。
问题
1、有的复杂不清晰。
总结
本节课主要是学习了STM32的SPI外设,介绍了SPI的硬件资源,如何工作的,SPI的的工作流程,各个部分如何工作,SPI的基本构成,如何进行配置的流程。