Meltdown原理介绍:用户空间读取内核内存
摘要
计算机系统的安全性从根本上依赖内存隔离,如,内核地址范围被标记为不可访问并受到保护,以防用户非法访问。本文介绍了Meltdown。 利用现代处理器上乱序执行,来读取内核任意的内存位置,包括个人数据和密码。乱序执行是必不可少的用来提升性能的手段,并在现代处理器中大量使用。该攻击无关操作系统,且不依赖任何软件漏洞。 Meltdown破坏了地址空间隔离以及半虚拟化环境所提供的所有安全保证,在此基础上建立的所有安全机制都将无用。在受影响的系统上,Meltdown使攻击者无需任何许可或特权即可读取云中其他进程或虚拟机的内存,从而影响数百万个客户以及几乎每个个人计算机用户。我们表明,KASLR的KAISER防御机制可以阻止Meltdown攻击。并呼吁,必须立即部署KAISER,以防止大规模利用Meltdown攻击,造成严重信息泄漏。
1.简介
当今操作系统的安全功能主要基于内存隔离,确保用户程序无法访问彼此的内存或内核内存。 正因有这种隔离机制,它允许在个人设备上同时运行多个应用程序,或在云中的一台计算机上执行多个用户的进程。
Meltdown是一种新颖的攻击,它通过为任何用户进程提供一种简单的攻击方法来获取其执行计算机的整个内核内存(包括映射在内核区域中的所有物理内存),从而完全打破内存隔离。 Meltdown不利用任何软件漏洞,即,它可在所有主流操作系统上使用。Meltdown利用了大多数现代处理器(例如自2010年以来的现代Intel微体系结构)可用的侧信道信息。
侧信道攻击通常需要有关目标应用程序非常详尽的知识,并且经过专门调整以泄漏机密信息。Meltdown攻击,攻击者在易受攻击的处理器上运行代码,可以获得整个内核地址空间的转储,包括任何映射的物理内存。
乱序执行是当今处理器的一项重要性能提升方式,目的是减少繁忙执行单元的延迟。例如:内存提取单元等待数据从内存中获取。 现代处理器不会等待执行,而是乱序执行操作,即,继续执行空闲执行单元的后续操作。
从安全角度来看,无序CPU允许无特权的进程将数据从特权(内核或物理)地址加载到临时CPU寄存器中。 此外,CPU会基于该寄存器值执行下一步的运算,例如,基于寄存器值访问阵列。 如果后续证明不应执行该指令,则简单地丢弃从内存查找的结果(例如,修改的寄存器状态),处理器就确保了正确的程序执行。 因此,在体系结构级别(例如,处理器应如何执行计算的抽象定义)不会出现安全性问题。
但是,乱序执行的内存查找会影响缓存,而缓存又可以通过缓存侧信道进行检测。 结果,攻击者可以通过按乱序执行流读取特权内存来转储整个内核内存,并通过微体系结构隐蔽通道(例如Flush + Reload)获知数据 。 因此,在微体系结构级别存在可利用的安全问题。
Meltdown破坏了CPU内存隔离提供的所有安全保证。评估了对现代台式机和笔记本电脑以及云服务器的攻击。 Meltdown允许无特权的进程读取映射到内核地址空间中的数据,包括Linux,Android和OS X上的整个物理内存,以及Windows上的很大一部分物理内存。虽然性能在很大程度上取决于特定的机器,例如处理器速度,TLB和缓存大小以及DRAM速度,但我们可以以3.2KB/ s到503KB / s的速度转储任意内核和物理内存,大量系统受到影响。
最初为防止KASLR的侧信道攻击,而开发的KAISER也在无意中防止了Meltdown攻击。 我们呼吁,立即在所有操作系统上部署KAISER是至关重要的。 幸运的是在报道中,三个主要操作系统(Windows,Linux和OS X)实现了KAISER的变体,且最近推出了补丁。
Meltdown在以下几个方面与Spectre攻击不同,特别是Spectre需要针对受害者进程的软件环境进行量身定制,但能更广泛地应用于CPU。此外,KAISER并没有缓解spectre攻击。
这篇文章的贡献如下:
- 描述了乱序执行作为一种新的,功能极其强大的基于软件的侧信道;
- 展示了如何将乱序执行与微体系结构隐蔽通道相结合,将数据传输到外部。
- 提出了一种将乱序执行与异常处理程序或TSX相结合的端到端攻击,没有任何权限或特权在笔记本电脑,台式机,移动电话和公共云计算机上读取任意物理内存。
本文的其余部分结构如下:在第2节中,描述乱序执行引入的基本问题。 在第3节中,提供了一个示例说明,说明了侧信道Meltdown漏洞。 在第4节中,描述了Meltdown的构建前提。 将在第5节中介绍完整的攻击过程。在第6节中进行总结。
2. 相关工作
在本节中,简单介绍乱序执行,地址转换和缓存攻击的背景知识。
2.1 乱序执行
乱序执行是一种优化技术,最大限度地利用CPU内核中所有执行单元。 CPU不会严格按照程序序列顺序处理指令,而是在所有必需资源可用时,就执行它们。 即,当前操作的执行单元被占用时,其他执行单元可以继续执行后续指令。 因此,指令可以并行运行,只要它们的结果互不影响。
此外,支持乱序执行的CPU允许以推测方式运行操作,在CPU确定指令是否被需要或被提交之前,处理器的乱序逻辑就处理指令。 在本文中,我们以更严格的含义来指代推测执行,它指的是分支之后的指令序列,并使用术语乱序执行(out-of-order execution)来指代,以任何方式使得处理器在提交先前指令结果之前就操作执行。
1967年,Tomasulo 开发了一种算法,该算法支持动态调度指令来实现乱序执行。
Intel架构,其流水线由前端(Frontend),执行引擎(Execution Engine)和内存子系统(Memory Subsystem)组成。前端从内存中获取x86指令,并将其解码为微操作(mOP),然后将其连续发送到执行引擎。乱序执行是在执行引擎中实现的,如图1所示。重排序缓冲区(Reorder Buffer)负责寄存器分配,寄存器重命名和退出。此外,其他优化,像移动消除或对零位成语的识别,均由重排序缓冲区直接处理。将mOP转发到统一预留站(Scheduler),该站将连接到执行单元的出口端口上的操作队列中。每个执行单元可以执行不同的任务,例如ALU操作,AES操作,地址生成单元(AGU)或内存加载和存储。 AGU以及加载和存储执行单元直接连接到内存子系统以处理其请求。
CPU具有分支预测单元(Branch Predictor),获得将要执行的下一条指令的合理猜测。 分支预测器尝试在条件计算出来之前确定分支。 可以提前执行位于该分支上且没有任何依赖性的指令,如果预测正确,则可以立即使用其结果。 如果预测不正确,则通过清除重排序缓冲区并重新初始化统一预留站,重排序缓冲区允许回滚到正常状态。
有多种预测分支的方法:静态分支预测,仅根据指令本身预测结果。 动态分支预测,在运行时收集统计信息以预测结果。 一级分支预测使用1位或2位计数器记录分支的最后结果。 现代处理器通常使用最近n个结果的历史的两级自适应预测器,从而可以预测规则重复的模式。 最近,出现使用神经网络进行分支预测的想法,并将其集成到CPU体系结构中。
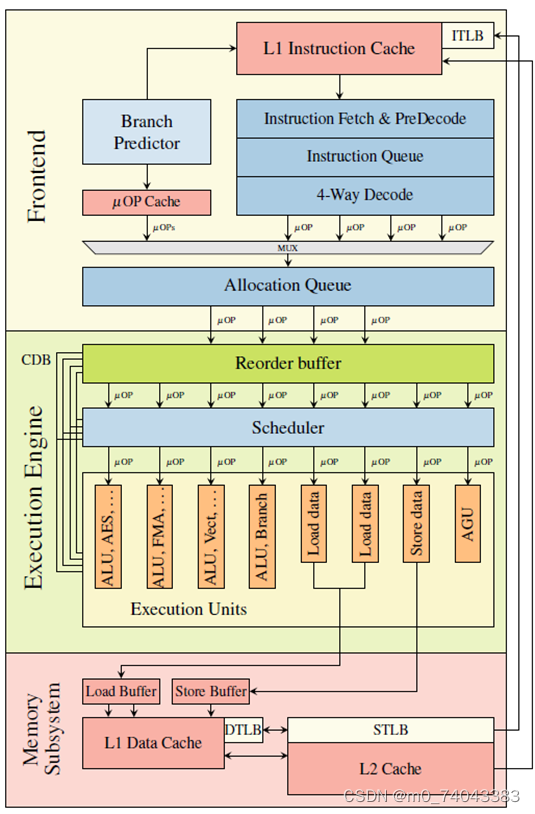
图1 Intel Skylake微体系结构单核的简化图示。 指令被解码为微指令(mOP),并由各个执行单元在执行引擎中乱序执行。
2.2 地址空间
为了进程隔离,CPU支持虚拟地址空间,虚拟地址会被转换为物理地址。虚拟地址空间被分为一组页面,这些页面可以通过多级页面转换表映射到物理内存。转换表定义了虚拟地址到物理地址的映射,还定义了用于执行特权检查的保护属性,例如可读,可写,可执行和用户可访问。当前进程使用的