一个由通义千问以及FFmpeg的AVFrame、buffer引起的bug:前面几帧影响后面帧数据
目录
1 问题描述
2 我最开始的代码----错误代码
3 正确的代码
4 为什么前面帧的结果会叠加到了后面帧上----因为ffmpeg新一帧只更新上一帧变化的部分
5 以后不要用通义千问写代码
1 问题描述
某个项目中,需要做人脸马赛克,然后这个是君正的某款芯片,他没有硬件解码,我就用了ffmpeg解码,然后我让通义千问给我写一个用ffmpeg解码h264视频的代码,然后对人脸区域做马赛克处理,出现的问题就是比如我在打人脸马赛克的时候出现重影、残留,就是比如我前面几帧做的马赛克在后面几帧上竟然还有,

这个看现象就是前面帧的马赛克效果被叠加到后面了。
2 我最开始的代码----错误代码
int SkuDetect::face_mosaic(const char* video_path) {// 初始化 FFmpegav_register_all();// 打开视频文件AVFormatContext* format_context = nullptr;if (avformat_open_input(&format_context, video_path, nullptr, nullptr) != 0) {std::cerr << "Could not open source file " << video_path << "\n";return -1;}if (avformat_find_stream_info(format_context, nullptr) < 0) {std::cerr << "Failed to retrieve input stream information.\n";return -1;}int video_stream_index = -1;for (unsigned i = 0; i < format_context->nb_streams; ++i) {if (format_context->streams[i]->codecpar->codec_type == AVMEDIA_TYPE_VIDEO) {video_stream_index = i;break;}}if (video_stream_index == -1) {std::cerr << "File does not contain any video stream.\n";return -1;}AVCodecParameters* codec_parameters = format_context->streams[video_stream_index]->codecpar;const AVCodec* codec = avcodec_find_decoder(codec_parameters->codec_id);AVCodecContext* codec_context = avcodec_alloc_context3(codec);avcodec_parameters_to_context(codec_context, codec_parameters);if (avcodec_open2(codec_context, codec, nullptr) < 0) {std::cerr << "Failed to open codec.\n";return -1;}printf("Pixel format: %d\n", codec_context->pix_fmt);// 获取视频的原始宽高int orig_w = codec_context->width;int orig_h = codec_context->height;// 加载人脸坐标std::map<int, std::vector<std::array<int, 4>>> face_coords_map = load_face_coordinates(video_path, orig_w, orig_h);//AVFrame* frame = av_frame_alloc();AVPacket packet;int frameCount = 0; // 记录帧数while (av_read_frame(format_context, &packet) >= 0) {AVFrame* frame = av_frame_alloc();if (packet.stream_index == video_stream_index) {if (avcodec_send_packet(codec_context, &packet) != 0) {std::cerr << "Error sending a packet for decoding." << std::endl;continue;}while (avcodec_receive_frame(codec_context, frame) == 0) {// 深拷贝 AVFrame 数据AVFrame* cloned_frame = av_frame_alloc();//用了深拷贝之后也还是有残影,并且深拷贝之后里面的data[0]的地址跟frame值一样的,指向同一块内存地址。cloned_frame = av_frame_clone(frame);// 获取当前帧的人脸坐标auto it = face_coords_map.find(frameCount);if (it != face_coords_map.end()) {const std::vector<std::array<int, 4>>& faces = it->second;printf("faces.size(): %d\n", faces.size());//用了深拷贝,并且memeset,然后前面这里保存依然会有马赛克残影,//save_frame_as_image(frame, frameCount, "result_image", it != face_coords_map.end() ? it->second : std::vector<std::array<int, 4>>());// 遍历所有人脸区域for (const auto& face : faces) {int x = face[0];int y = face[1];int width = face[2];int height = face[3];printf("frameCount:%d, x: %d, y: %d, width: %d, height: %d\n",frameCount, x, y, width, height);printf("frame->data[0]:0x%x, frame->linesize[0]:%d \n", frame->data[0], frame->linesize[0]);// 对 Y 分量进行马赛克apply_uniform_mosaic_y(dst_frame->data[0], dst_frame->linesize[0], x, y, width, height);// 对 U 和 V 分量进行马赛克int x_uv = x_expanded / 2, y_uv = y_expanded / 2;int width_uv = width_expanded / 2, height_uv = height_expanded / 2;apply_uniform_mosaic_uv(frame->data[1], frame->linesize[1], x_uv, y_uv, width_uv, height_uv);apply_uniform_mosaic_uv(frame->data[2], frame->linesize[2], x_uv, y_uv, width_uv, height_uv);}}// 保存处理后的帧为图片//save_frame_as_image(frame, frameCount, "result_image_mosaic", it != face_coords_map.end() ? it->second : std::vector<std::array<int, 4>>());// 保存处理后的帧为图片save_frame_as_image(dst_frame, frameCount, "result_image_mosaic", it != face_coords_map.end() ? it->second : std::vector<std::array<int, 4>>());av_frame_free(&dst_frame); //memset(frame, 0, sizeof(AVFrame));//用了memset之后也还是有残影。// 释放克隆帧av_frame_unref(cloned_frame);av_frame_free(&cloned_frame);frameCount++; // 增加帧数}}// 重置 AVFrameav_frame_unref(frame);av_packet_unref(&packet);av_frame_free(&frame);}// 清理资源//avcodec_free_context(&codec_context);avformat_close_input(&format_context);std::cout << "Processing completed." << std::endl;return 0;
}
上面的代码是让通义千问给写的,刚开始不对,他还让加上了clone函数做深拷贝,但其实深拷贝不是这样的,
3 正确的代码
AVFrame* apply_mosaic_with_copy(const AVFrame* src_frame, int x, int y, int width, int height, int block_size) {if (!src_frame || !src_frame->data[0]) {return nullptr;}// 创建新帧AVFrame* dst_frame = av_frame_alloc();if (!dst_frame) {return nullptr;}// 复制帧属性dst_frame->format = src_frame->format;dst_frame->width = src_frame->width;dst_frame->height = src_frame->height;// 分配缓冲区if (av_frame_get_buffer(dst_frame, 32) < 0) {av_frame_free(&dst_frame);return nullptr;}// 复制原始数据if (av_frame_copy(dst_frame, src_frame) < 0) {av_frame_free(&dst_frame);return nullptr;}// 设置其他属性if (av_frame_copy_props(dst_frame, src_frame) < 0) {av_frame_free(&dst_frame);return nullptr;}// 应用马赛克(使用修改后的版本)if (apply_mosaic_to_avframe(dst_frame, x, y, width, height, block_size) < 0) {av_frame_free(&dst_frame);return nullptr;}return dst_frame;
}正确的深拷贝的代码应该是这样的,不只是alloc一个frame,还需要av_frame_get_buffer,重点就在这里的buffer。
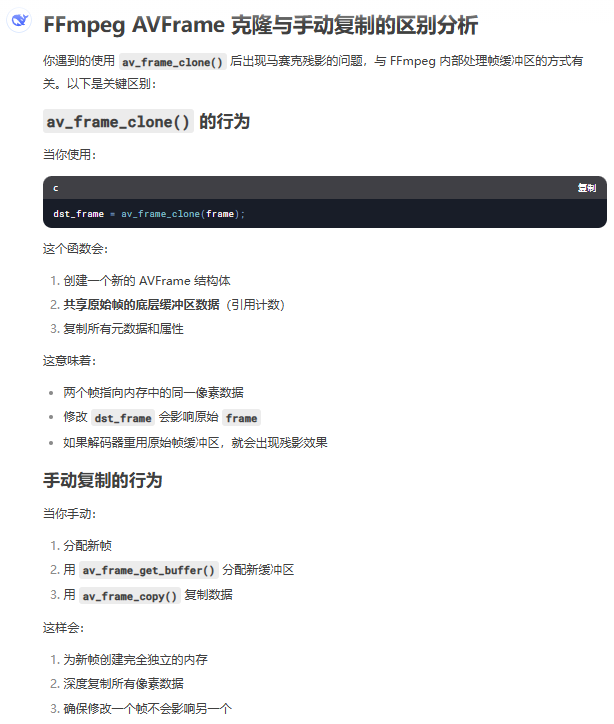
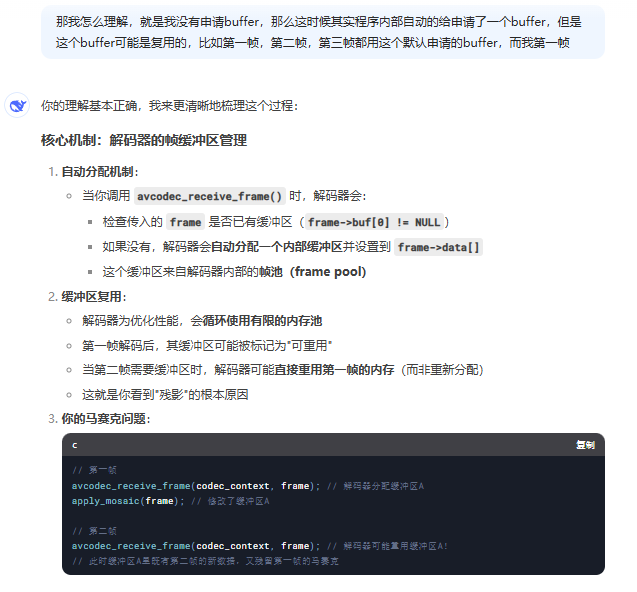
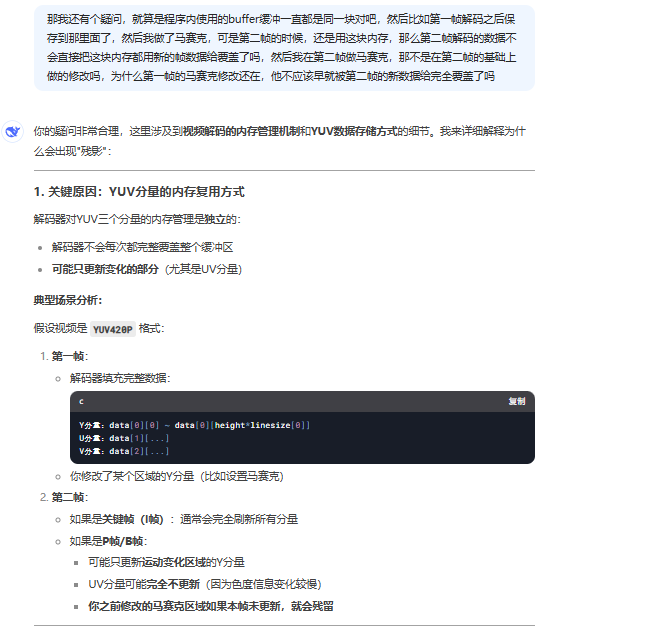
4 为什么前面帧的结果会叠加到了后面帧上----因为ffmpeg新一帧只更新上一帧变化的部分
看完下面几个问题和答案之后就明白为什么了,下面几个问题是用deepseek问的,不是通义千问,通义千问的答案明显不行



5 以后不要用通义千问写代码
通义千问不适合写代码,不行,以前的h264转yuv视频的时候,也是通义千问给写的代码错了,将.mp4视频文件转成.yuv视频文件C++代码备份_mp4视频保存为yuv格式-CSDN博客
这个以前的代码就是通义千问给写错了,而且错误很隐蔽,转出来的yuv是对的,只是稍微有点色差,当初这个bug也耽误了不少时间。