[Lc] 最长公共子序列 | Fenwick Tree(树状数组):处理动态前缀和
目录
LCR 095. 最长公共子序列
题解
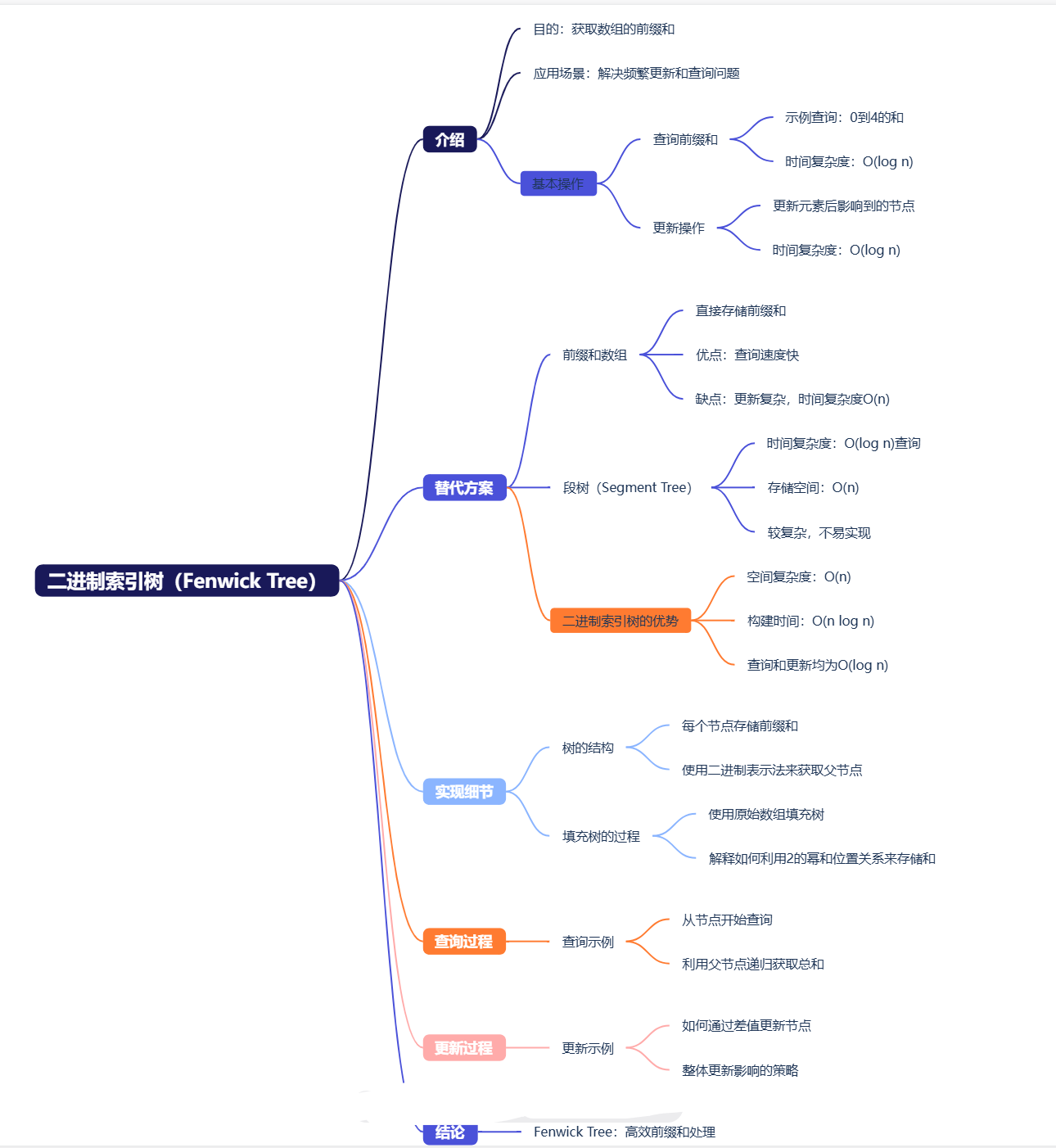
Fenwick Tree(树状数组):处理动态前缀和
一、问题背景:当传统方法遇到瓶颈
二、Fenwick Tree核心设计
2.1 二进制索引的魔法
2.2 关键操作解析
更新操作(O(log n))
查询操作(O(log n))
三、实现细节精要
3.1 初始化优化
3.2 空间压缩技巧
四、性能对比分析
五、进阶应用场景
六、实现注意事项
七、与其他数据结构的配合
延伸阅读
LCR 095. 最长公共子序列
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
- 例如,
"ace"是"abcde"的子序列,但"aec"不是"abcde"的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
示例 1:
输入:text1 = "abcde", text2 = "ace"
输出:3
解释:最长公共子序列是 "ace" ,它的长度为 3 。题解
两个字符串可能存在多个公共子序列,题目要求计算最长公共子序列的长度,因此可以考虑使用动态规划来解决。
二维DP数组
- 用函数 f(i, j) 表示字符串 s1 中下标从 0 开始到 i 的子字符串 s1[0...i] 和字符串 s2 中下标从 0 开始到 j 的子字符串 s2[0...j] 的最长公共子序列的长度。
- 对于 f(i, j),如果 s1[i] == s2[j],那么相当于在 s1[0...i - 1] 和 s2[0...j - 1] 的最长公共子序列的后面添加一个公共字符,也就是 f(i, j) = f(i - 1, j - 1) + 1。
- 如果 s1[i] != s2[j],那么这两个字符不可能出现在 s1[0...i] 和 s2[0...j] 的公共子序列中。
- 此时 s1[0...i] 和 s2[0...j] 的最长公共子序列是s1[0...i - 1] 和 s2[0...j] 的最长公共子序列和s1[0...i] 和 s2[0...j - 1] 的最长公共子序列中的较大值,即 f(i, j) = max(f(i - 1, j), f(i, j - 1))。 (子序列的特性,决定了可以这么写
- 所以转移状态方程为
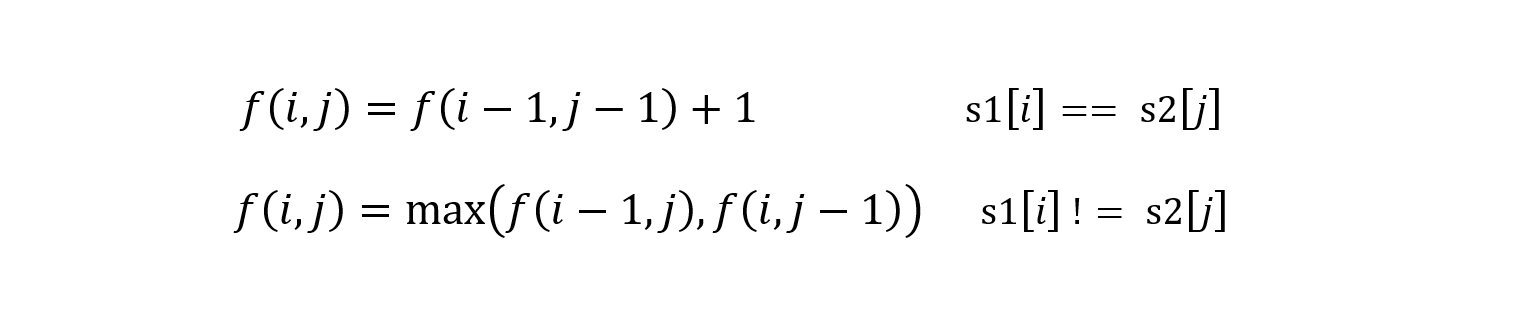
因为状态方程有两个变量,所以需要使用二维矩阵保存。同时上述方程会出现 i 或者 j 出现 -1 的情况,代表出现 -1 下标的字符串的子串目前是空的,那么就不会有公共子序列,所以 f(i, -1) = f(-1, j) = 0。
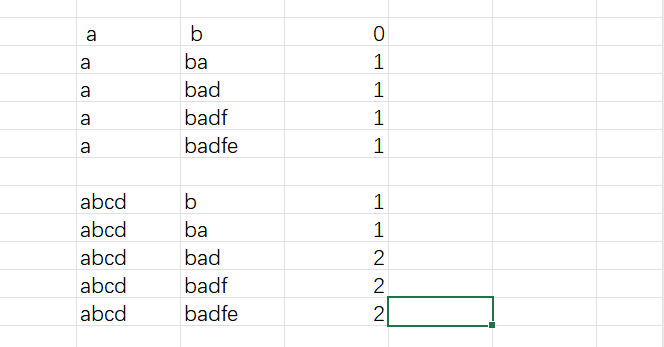
以 "abcde" 和 "badfe" 为例子,二维状态矩阵如下图
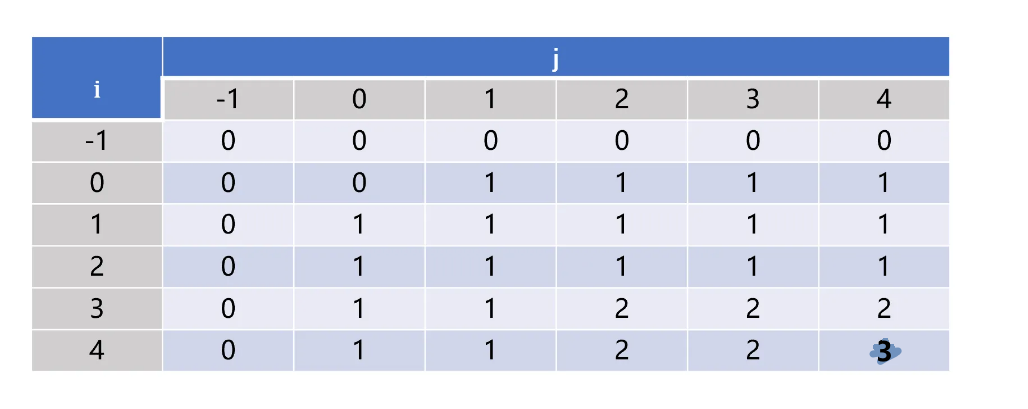
一开始先完成 f(i, -1) = f(-1, j) = 0 初始化,之后二维矩阵按照从左往右逐行向下遍历填充。
- 推荐使用逐行而不是逐列,虽然不影响算法,但是考虑到二维数组本身是按照一维数组存储以及计算机缓存的运行机制,按照逐行遍历的方式效率更高点。
- 完整的代码如下,若 s1 和 s2 的长度分别为 m 和 n,那么时间复杂度为 O(mn),空间复杂度为 O(mn)。
class Solution {
public:int longestCommonSubsequence(string text1, string text2) {int n1 = text1.size();int n2 = text2.size();vector<vector<int>> dp(n1 + 1, vector<int>(n2 + 1));for (int i = 0; i < n1; ++i) {for (int j = 0; j < n2; ++j) {if (text1[i] == text2[j]) {dp[i + 1][j + 1] = dp[i][j] + 1;} else {dp[i + 1][j + 1] = max(dp[i][j + 1], dp[i + 1][j]);}}} return dp[n1][n2];}
};- 当前==,就f(i - 1, j - 1) + 1
- 当前不等,就存遍历过的最大max(f(i - 1, j), f(i, j - 1))
遍历
将 i==0 和 i==3 的情况来查看一下
2179. 统计数组中好三元组数目
给你两个下标从 0 开始且长度为 n 的整数数组 nums1 和 nums2 ,两者都是 [0, 1, ..., n - 1] 的 排列 。
好三元组 指的是 3 个 互不相同 的值,且它们在数组 nums1 和 nums2 中出现顺序保持一致。换句话说,如果我们将 pos1v 记为值 v 在 nums1 中出现的位置,pos2v 为值 v 在 nums2 中的位置,那么一个好三元组定义为 0 <= x, y, z <= n - 1 ,且 pos1x < pos1y < pos1z 和 pos2x < pos2y < pos2z 都成立的 (x, y, z) 。
请你返回好三元组的 总数目 。
示例 1:
输入:nums1 = [2,0,1,3], nums2 = [0,1,2,3]
输出:1
解释:
总共有 4 个三元组 (x,y,z) 满足 pos1x < pos1y < pos1z ,分别是 (2,0,1) ,(2,0,3) ,(2,1,3) 和 (0,1,3) 。
这些三元组中,只有 (0,1,3) 满足 pos2x < pos2y < pos2z 。所以只有 1 个好三元组。示例 2:
输入:nums1 = [4,0,1,3,2], nums2 = [4,1,0,2,3]
输出:4
解释:总共有 4 个好三元组 (4,0,3) ,(4,0,2) ,(4,1,3) 和 (4,1,2) 。下标比较相当于是一种映射规则。现在我在这种映射规则上再施加一种映射规则,让在nums1中满足下标递增这种性质映射为键值递增这种性质。
同样的对nums2施加这种规则,下标递增也应该映射为键值递增。有一点点往这方面想,不看题解根本无法完全想出来。
template<typename T>
class FenwickTree {vector<T> tree;public:// 使用下标 1 到 nFenwickTree(int n) : tree(n + 1) {}// a[i] 增加 val// 1 <= i <= nvoid update(int i, T val) {for (; i < tree.size(); i += i & -i) {tree[i] += val;}}// 求前缀和 a[1] + ... + a[i]// 1 <= i <= nT pre(int i) const {T res = 0;for (; i > 0; i &= i - 1) {res += tree[i];}return res;}
};class Solution {
public:long long goodTriplets(vector<int>& nums1, vector<int>& nums2) {int n = nums1.size();vector<int> p(n);for (int i = 0; i < n; i++) {p[nums1[i]] = i;}long long ans = 0;FenwickTree<int> t(n);for (int i = 0; i < n - 1; i++) {int y = p[nums2[i]];int less = t.pre(y);ans += (long) less * (n - 1 - y - (i - less));t.update(y + 1, 1);}return ans;}
};

Fenwick Tree(树状数组):处理动态前缀和
一、问题背景:当传统方法遇到瓶颈
在数据处理场景中,我们常需要快速计算数组的前缀和(Prefix Sum)。
传统的前缀和数组方法虽然能在O(1)时间完成查询,但面对频繁更新的动态数据时,其O(n)的更新时间复杂度将成为性能瓶颈。
想象一个股票交易系统需要实时追踪每分钟的成交额统计,这种场景正是Fenwick Tree大显身手的战场。
二、Fenwick Tree核心设计
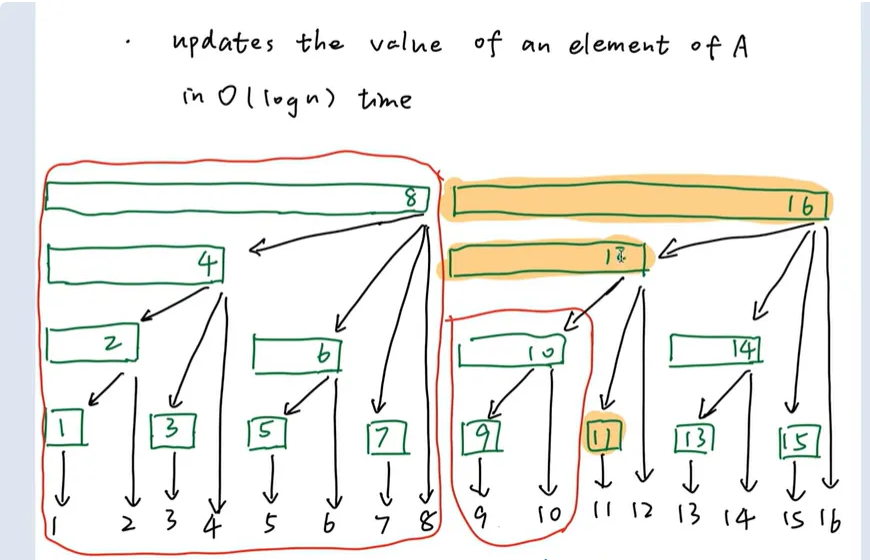
2.1 二进制索引的魔法
该数据结构的核心创新在于将数组索引的二进制表示转化为层次结构。每个索引对应的二进制最低有效位(LSB)决定了其管理的数据范围:
- 索引i的LSB位置k(从1开始计数)
- 该节点负责管理区间[i - 2^{k-1} + 1, i]的数据
2.2 关键操作解析
更新操作(O(log n))
def update(i, delta):while i <= n:tree[i] += deltai += i & -i # 找到下一个父节点查询操作(O(log n))
def query(i):res = 0while i > 0:res += tree[i]i -= i & -i # 剥离最低有效位return res三、实现细节精要
3.1 初始化优化
# 最优初始化方式(时间复杂度O(n))
def build(arr):n = len(arr)tree = [0]*(n+1)for i in range(1, n+1):tree[i] += arr[i-1]j = i + (i & -i)if j <= n:tree[j] += tree[i]return tree3.2 空间压缩技巧
通过将原始数组映射到树状数组的奇数索引位置,可以节省约50%的内存空间。这种优化在嵌入式系统或处理海量数据时尤为重要。
四、性能对比分析
| 操作类型 | 前缀和数组 | Fenwick Tree |
| 初始化 | O(n) | O(n) |
| 单点更新 | O(n) | O(log n) |
| 范围查询 | O(1) | O(log n) |
| 空间复杂度 | O(n) | O(n) |
适用场景选择指南:
- 静态数据:优先选择前缀和数组
- 动态数据:必选Fenwick Tree
- 混合操作:根据更新/查询频率比例决策
五、进阶应用场景
- 逆序对统计:结合离散化技术,可在O(n log n)时间内完成
- 多维扩展:二维Fenwick Tree支持矩阵区域求和
- 频率统计:实现高效的可变范围频率查询
- 实时推荐系统:动态维护用户行为热度排名
六、实现注意事项
- 索引通常从1开始(避免处理0的特殊情况)
- 更新操作是增量式的(delta为变化量而非绝对值)
- 合理选择数据存储类型(防止整数溢出)
- 注意缓存友好性(顺序访问优于随机访问)
七、与其他数据结构的配合
- 与线段树结合实现区间更新/区间查询
- 联合哈希表处理稀疏数据
- 配合持久化技术实现历史版本查询
延伸阅读
- 原理解析视频
- 《算法导论》第15章高级数据结构
- ACM竞赛中的经典应用案例集