同济大学轻量化低成本具身导航!COSMO:基于选择性记忆组合的低开销视觉语言导航

- 作者:Siqi Zhang 1 ^{1} 1, Yanyuan Qiao 3 ^{3} 3, Qunbo Wang 2 ^{2} 2, Zike Yan 4 ^{4} 4, Qi Wu 3 ^{3} 3, Zhihua Wei 1 ^{1} 1, Jing Liu 1 ^{1} 1
- 单位: 1 ^{1} 1同济大学计算机科学与技术学院, 2 ^{2} 2中科院自动化研究所, 3 ^{3} 3阿德莱德大学澳大利亚机器学习研究所, 4 ^{4} 4清华大学人工智能产业研究院
- 论文标题:COSMO: Combination of Selective Memorization for Low-cost Vision-and-Language Navigation
- 论文链接:https://arxiv.org/pdf/2503.24065
主要贡献
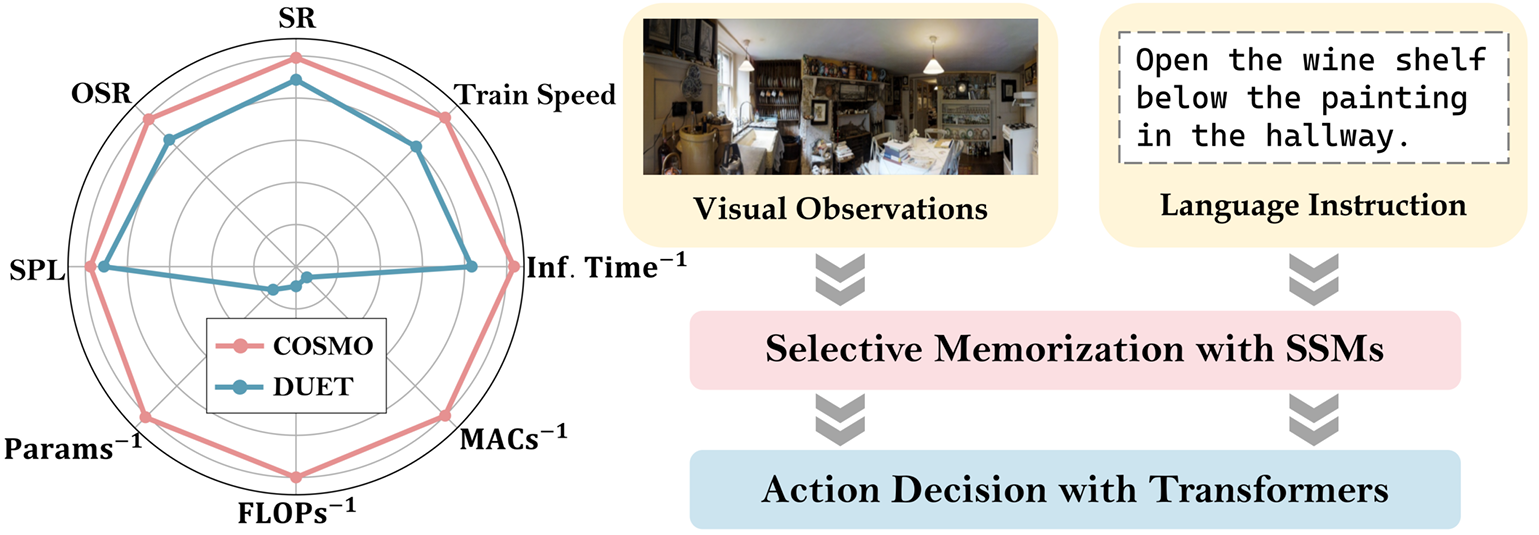
- 论文提出COSMO架构,结合了选择性记忆,旨在实现低成本且高效的视觉语言导航。
- 引入RSS模块Round Selective Scan (RSS),用于在单个扫描中捕获标记间的全面关系,增强空间建模能力。
- 引入CS3模块Cross-modal Selective State Space Module (CS3) ,用于促进跨模态交互,适应视觉语言导航任务的需求。
- COSMO在多个基准数据集上表现出色,同时显著降低了计算成本,参数和FLOPs分别仅为DUET的15.5%和9.3%。
研究背景
研究问题
- 论文主要解决的问题是如何在低成本的情况下实现高效的视觉语言导航(VLN)。
- VLN任务在人工智能研究中具有重要意义,尤其是在家庭助理机器人和动态环境中的自主导航系统中。
研究难点
该问题的研究难点包括:
- 现有的VLN方法通常依赖于Transformer架构,并结合外部知识库或地图信息来提高性能,但这导致了模型变大、计算成本增加;
- 此外,随着指令长度的增加,路径复杂性也随之增加,导致当前方法的导航性能下降。
相关工作
-
视觉语言导航(VLN):
- VLN任务是实现多功能具身导航智能体的关键组成部分,吸引了广泛的研究关注。早期方法采用编码器-解码器框架来记忆先前访问的位置,随后采用基于Transformer的架构显著提升了导航性能。
- 基于地图的方法通过构建拓扑图、顶向下语义图或网格图来显式地记忆导航历史。
- 近期研究还引入了世界模型的概念,用于未来图像预测和心理规划,以增强导航性能。
- 一些方法通过结合更全面的视觉线索(如深度和地图信息)或常识知识来提升导航性能。
- 最近,Nav-iLLM引入了一个能够处理多种具身任务的通用智能体,但模型规模的扩大导致了更高的计算成本。
-
状态空间模型(SSMs):
- SSMs在序列建模中显示出显著的有效性。HiPPO通过使用高阶正交多项式压缩输入来捕捉长期序列依赖性。
- S4通过将结构化状态矩阵分解为低秩和平常项来减少计算和内存需求。
- Mamba通过引入选择机制和输入依赖的SSM层来增强S4的性能。
- 后续研究扩展了Mamba的应用领域,如视觉、多模态、生成和机器人等领域。
- 在视觉领域,Mamba的潜力激发了一系列医学图像分割的工作。在多模态领域,VL-mamba和Cobra利用Mamba进行多模态推理。
-
论文指出,尽管SSMs在长序列和因果数据建模中表现出色,但在处理不同长度的序列和多模态信息时仍面临挑战。
-
COSMO通过引入为VLN任务定制的选择性状态空间模块来解决这些问题。
理论基础
问题定义
在标准的离散环境设置中,VLN任务的目标是让智能体根据自然语言指令在导航图中找到目标位置。具体来说:
- 环境被定义为一个无向导航图 G = { V , E } \mathcal{G} = \{\mathcal{V}, \mathcal{E}\} G={V,E},其中 V = { V i } i = 1 K \mathcal{V} = \{V_i\}_{i=1}^K V={Vi}i=1K 表示 K K K 个可导航节点, E \mathcal{E} E 表示连接边。
- 给定一个包含 L L L 个单词的指令 I = { w i } i = 1 L \mathcal{I} = \{w_i\}_{i=1}^L I={wi}i=1L,智能体的任务是根据指令遍历导航图到达目标位置,并在需要时找到指定物体。
- 在每一步 t t t,智能体接收一个全景视图 O t \mathcal{O}_t Ot 和当前节点 V t V_t Vt 的相邻节点 N ( V t ) \mathcal{N}(V_t) N(Vt)。
- 视图 O t \mathcal{O}_t Ot 可以被分割成 N N N 个视图图像 O t = { v i t } i = 1 N \mathcal{O}_t = \{v_i^t\}_{i=1}^N Ot={vit}i=1N,其中 v i v_i vi 表示节点 V t V_t Vt 的第 i i i 个视图图像。
- 动作空间 A t \mathcal{A}_t At 包含导航到 V t + 1 ∈ N ( V t ) V_{t+1} \in \mathcal{N}(V_t) Vt+1∈N(Vt) 或在 V t V_t Vt 处停止。
状态空间模型
SSMs是一种用于序列建模的方法,通常被视为线性时不变系统(LTI),通过隐藏状态 h ( t ) h(t) h(t) 将输入 x ( t ) x(t) x(t) 映射到输出响应 y ( t ) y(t) y(t)。
-
连续时间的SSMs通常通过线性常微分方程(ODEs)表示:
h ′ ( t ) = A h ( t ) + B x ( t ) , y ( t ) = C h ′ ( t ) + D x ( t ) h'(t) = A h(t) + B x(t), \quad y(t) = C h'(t) + D x(t) h′(t)=Ah(t)+Bx(t),y(t)=Ch′(t)+Dx(t)
其中 A ∈ R N × N A \in R^{N \times N} A∈RN×N 是演化矩阵, B ∈ R N × 1 B \in R^{N \times 1} B∈RN×1 和 C ∈ R N × 1 C \in R^{N \times 1} C∈RN×1 是与系统输入和输出相关的投影参数, D ∈ R D \in R D∈R 是跳过连接的权重。 -
为了集成到深度模型中,连续时间的SSMs需要进行离散化。通过引入时间尺度参数 Δ ∈ R \Delta \in R Δ∈R,可以将连续参数 A A A 和 B B B 转换为离散参数 A ‾ \overline{A} A 和 B ‾ \overline{B} B:
A ‾ = exp ( Δ A ) \overline{A} = \exp(\Delta A) A=exp(ΔA)
B ‾ = exp ( Δ A ) − 1 ( exp ( Δ A ) − I ) ⋅ Δ B ≈ Δ B \overline{B} = \exp(\Delta A)^{-1} (\exp(\Delta A) - I) \cdot \Delta B \approx \Delta B B=exp(ΔA)−1(exp(ΔA)−I)⋅ΔB≈ΔB
离散化后,方程可以重写为:
h t = A ˉ h t − 1 + B ˉ x t , y t = C h t + D x t h_t = \bar{A} h_{t-1} + \bar{B} x_t, \quad y_t = C h_t + D x_t ht=Aˉht−1+Bˉxt,yt=Cht+Dxt -
在实践中, x t x_t xt 是一个具有 D D D 维度的特征向量,方程对每个维度独立操作。
Mamba的选择性机制
Mamba通过学习输入依赖的参数来选择数据,超越了传统的SSMs:
- 输入依赖的参数通过线性投影层 S B S_B SB 和 S C S_C SC 来选择数据:
B t = S B ( x t ) , C t = S C ( x t ) , Δ t = τ Δ ( S Δ ( x t ) ) B_t = S_B(x_t), \quad C_t = S_C(x_t), \quad \Delta_t = \tau_{\Delta}(S_{\Delta}(x_t)) Bt=SB(xt),Ct=SC(xt),Δt=τΔ(SΔ(xt))
其中 τ Δ \tau_{\Delta} τΔ 是SoftPlus,ReLU的平滑近似。
方法
基线方法
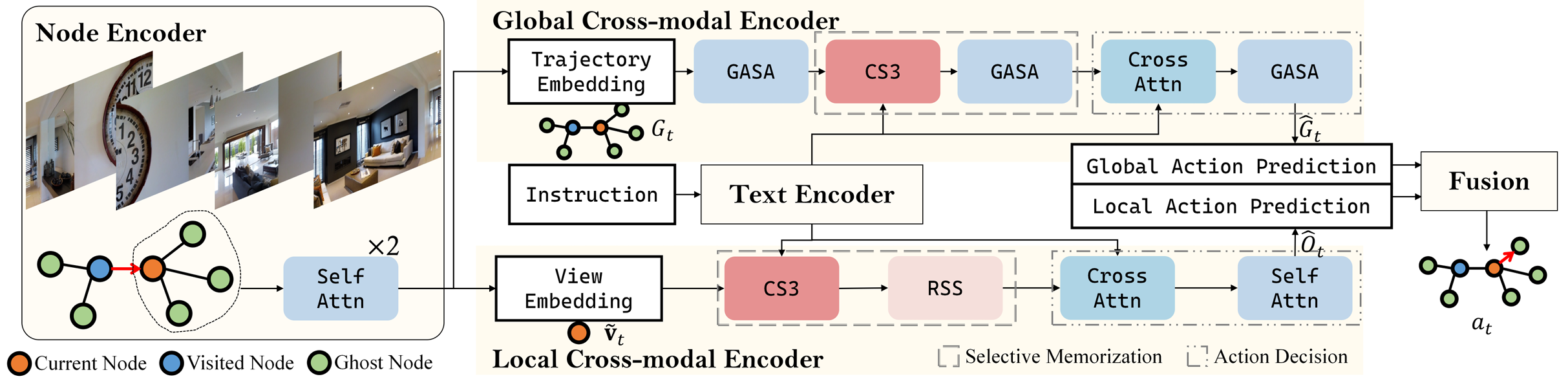
COSMO以DUET为基线模型,采用双流架构,包括文本编码器、全景编码器和跨模态编码器。
文本编码器
- 每个指令中的单词被嵌入,并添加位置嵌入和类型嵌入。
- 所有单词标记被输入到预训练的语言编码器中,以获得单词表示,记为 W = { w ^ 1 , . . . , w ^ L } \mathcal{W} = \{\hat{w}_1, ..., \hat{w}_L\} W={w^1,...,w^L}。
全景编码器
- 在时间步 t t t,智能体接收包含 N N N 个视图的全景观察 O t = { v i } i = 1 N \mathcal{O}_t = \{v_i\}_{i=1}^N Ot={vi}i=1N。
- 使用预训练的视觉Transformer提取每个视图的全局表示。
- 这些特征随后被输入多层Transformer以建模视图之间的空间关系。
跨模态编码器
- 粗尺度编码器构建拓扑图,其中所有视图的均值代表访问过的节点和当前节点,而部分观察的平均值代表幽灵节点。
- 视觉特征(粗尺度上的拓扑图,细尺度上的当前节点)和文本特征被输入多个跨模态Transformer块以生成多模态特征。
动作预测
- 跨模态编码器的输出多模态特征被输入到单独的前馈网络(FFNs)以获取动作预测。
- 这些预测通过一个可学习的标量动态融合,以获得最终的动作。
COSMO
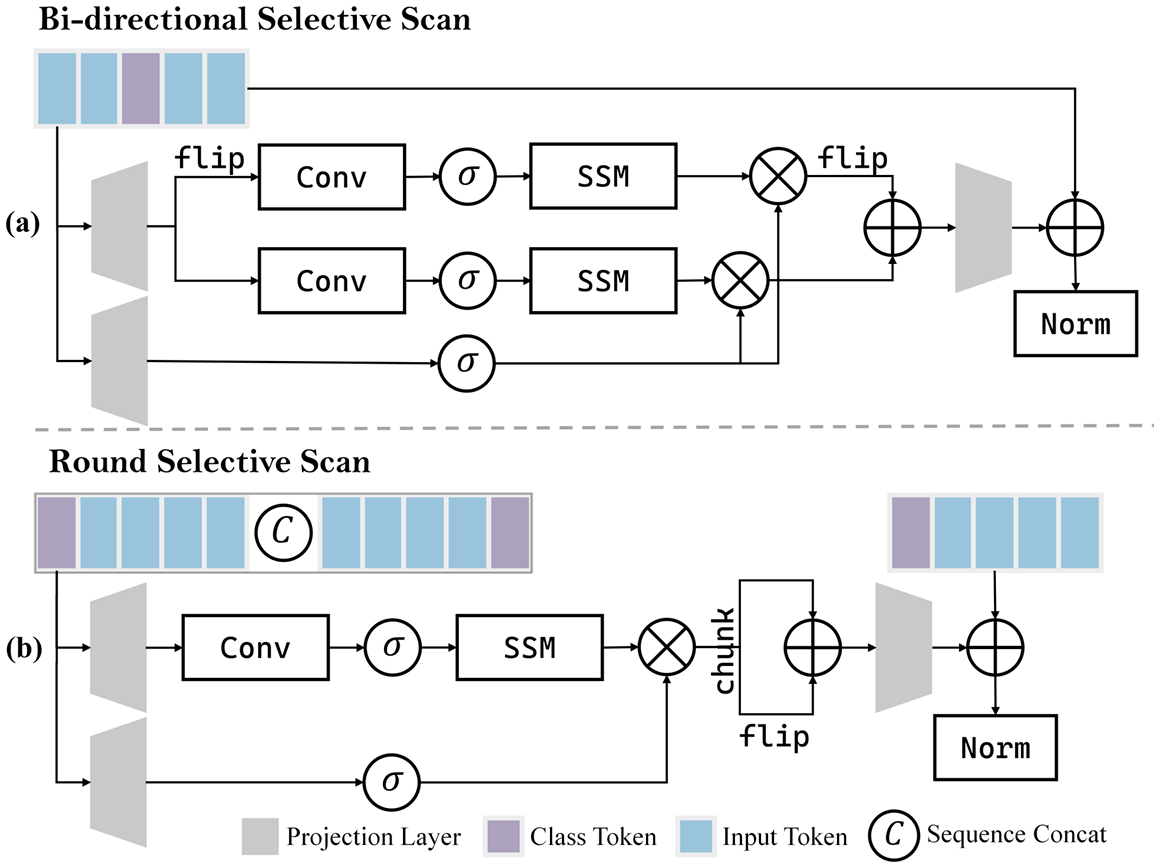
Round Selective Scan (RSS)
- RSS模块用于空间建模,通过在单个扫描轮次内捕获标记间的关系来提高效率。
- 输入序列 x ′ x' x′ 被翻转并与原始序列 x x x 连接,形成新的序列 x = [ x ′ ∣ flip ( x ′ ) ] x = [x' \mid \text{flip}(x')] x=[x′∣flip(x′)]。
- 通过一次扫描过程,RSS模块能够捕获更全面的上下文信息。
- 输出 y y y 在标记维度上均分并反转第二半,以获得RSS结果。
Cross-modal Selective State Space Module (CS3)
- CS3模块用于跨模态交互,将选择性机制适应到双流结构中。
- 输入为两个模态的特征向量 x x x 和 y y y,分别表示视觉和文本特征。
- CS3模块通过以下步骤更新状态空间:
- y ′ y' y′ 是 y y y 的翻转和连接版本,以使所有标记能够访问和影响类标记。
- y in y_{\text{in}} yin 是通过卷积和激活函数处理后的 y ′ y' y′。
- B B B 和 Δ \Delta Δ 基于 y y y 构建,以更新状态空间。
- C C C 基于 x x x 构建,以指导从状态空间到输出的转换。
- 通过状态空间更新后, y y y 的类标记输出作为门来选择性地过滤来自 x x x 的相关信息。
混合架构
- 节点编码器在构建拓扑图后,对当前节点及其未访问的邻居节点进行编码。
- 全局跨模态编码器在全局层面上选择下一个动作或停止。
- 局部跨模态编码器在局部层面上关注当前位置并选择相应的视图或决定停止。
实验
实验设置
COSMO模型在三个主流的视觉-语言导航数据集上进行评估:R2R、REVERIE和R2R-CE。
数据集
- R2R:提供分步指令,分为训练、验证和测试集。训练集包含61个房子,验证集和测试集分别包含11和18个房子。
- R2R-CE:将R2R中的路径转移到连续环境中,路径长度平均为9.89米,指令平均包含32个单词。
- REVERIE:提供粗粒度指令,主要描述目的地和目标对象。训练集包含60个房子,验证集和测试集分别包含46和16个房子。
与其他方法的比较
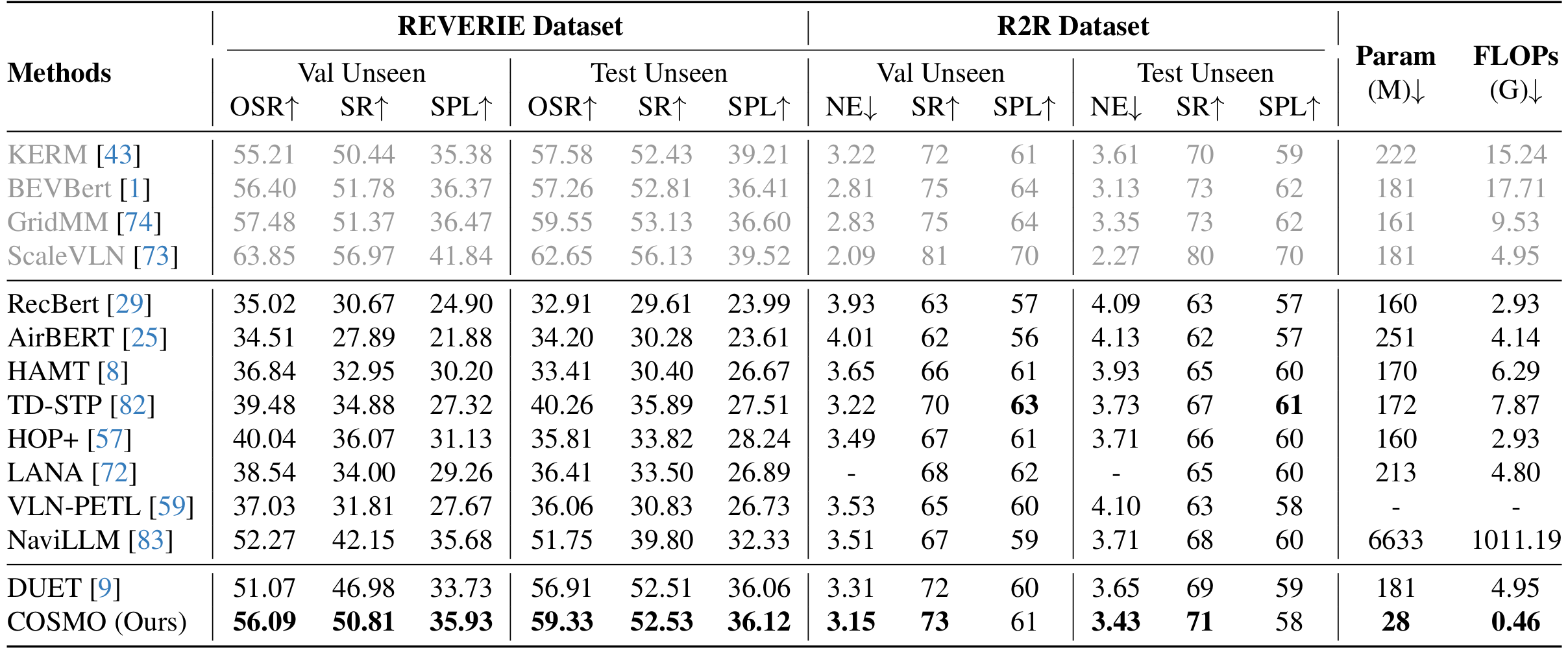
导航性能
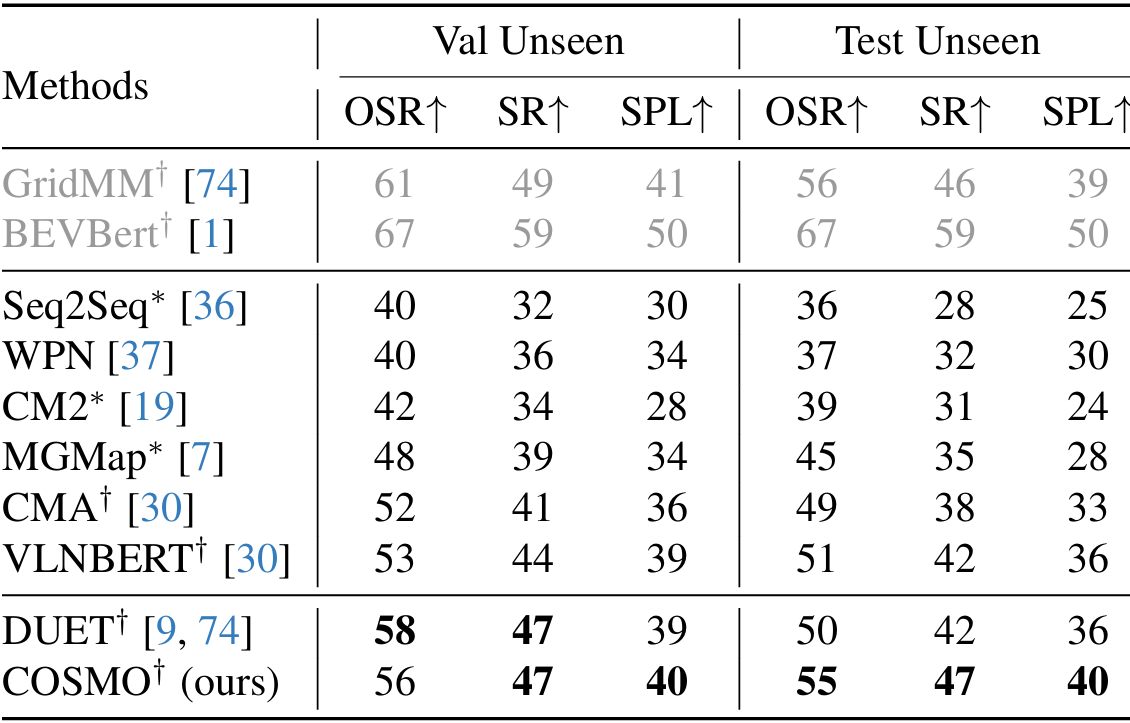
- 在REVERIE数据集上,COSMO在验证未见集上表现出色,成功率达到50.81%,优于NaviLLM和DUET。
- 在R2R数据集上,COSMO在测试集上表现出色,成功率达到71%,接近DUET的性能。
- 在R2R-CE数据集上,COSMO在测试集上超越了DUET和GridMM,显示出更好的泛化能力。
计算成本
- COSMO在计算成本上具有显著优势,仅需要DUET 9.3%的计算量和15.5%的参数。
- 通过减少计算复杂性和参数数量,COSMO在保持高性能的同时降低了计算成本。
消融研究
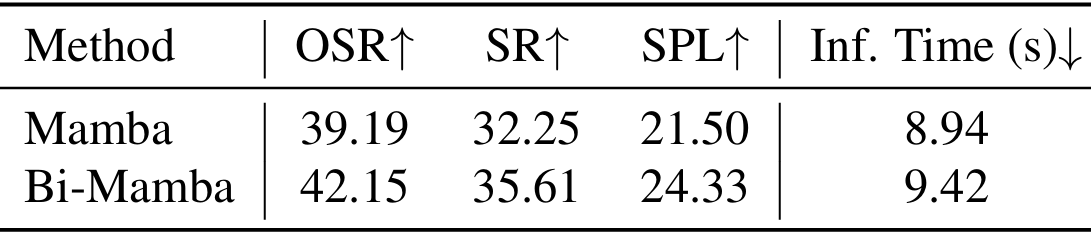
双流结构的必要性
- 直接应用Mamba到VLN任务会导致性能下降,表明双流结构的重要性。
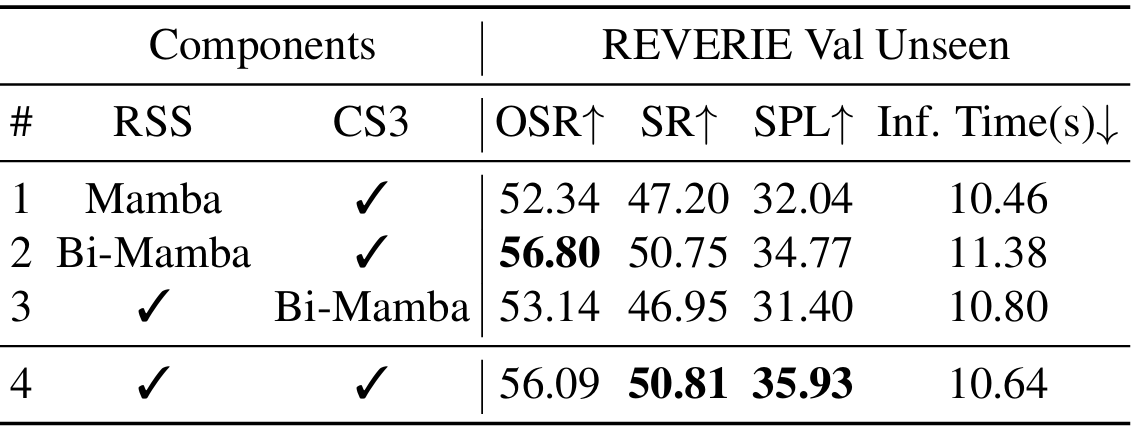
RSS模块的优势
- 替换RSS模块会导致成功率和路径长度标准化成功率(SPL)的下降,验证了RSS模块的有效性。
CS3模块的优势
- 替换CS3模块会导致成功率和SPL的显著下降,表明CS3在跨模态交互中的优越性。
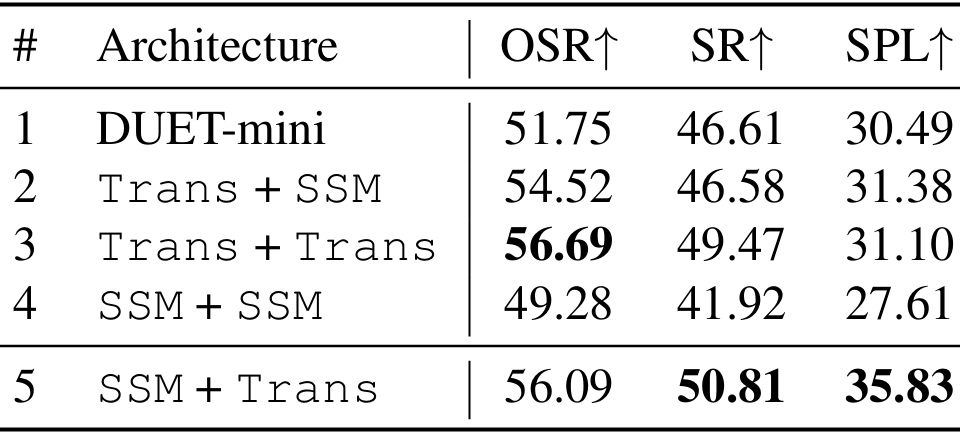
模型架构的必要性
- 通过比较不同的模型架构,验证了SSMs在Transformer之前的必要性。
定量和定性分析
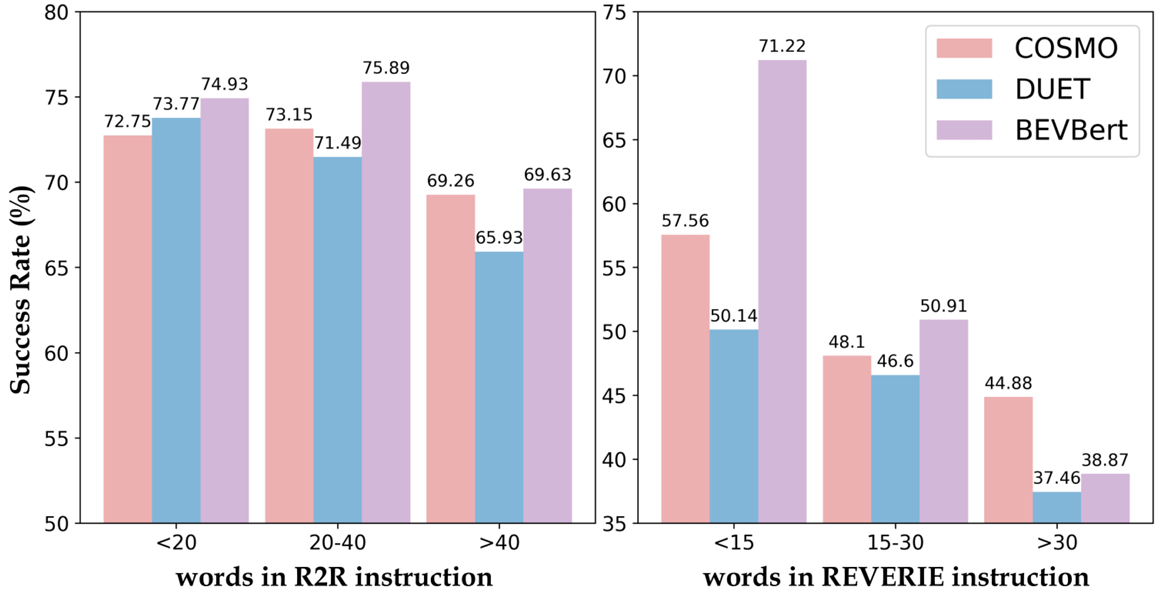
定量分析
- 通过比较不同长度指令的成功率,验证了COSMO在长指令上的优越性。
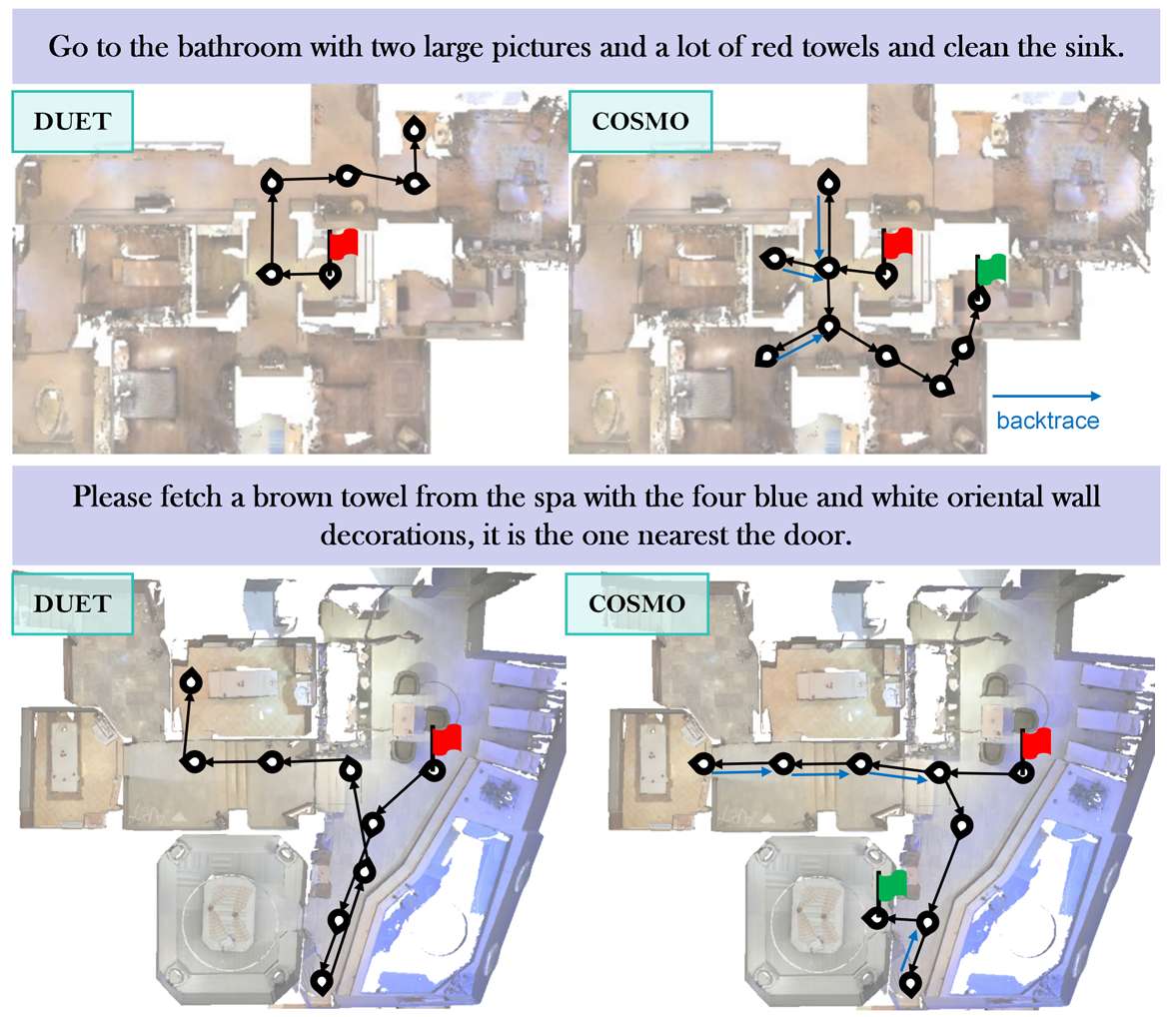
定性分析
- 通过可视化预测路径,展示了COSMO在处理复杂环境时的优势。
总结
- 本文提出的COSMO通过结合两种定制的VLN选择性状态空间模块(RSS和CS3),实现了低成本的VLN。
- 实验结果表明,COSMO在处理长指令时表现出显著的导航性能提升,同时显著降低了计算成本。
- COSMO展示了在保持竞争力的导航性能的同时,显著减少计算成本的能力。
