T4P: Test-Time Training of Trajectory Prediction
T4P: Test-Time Training of Trajectory Prediction via Masked Autoencoder and Actor-specific Token Memory
创新点
我们提出了一种用于轨迹预测的测试时训练方法(T4P),利用掩码自动编码器学习深度特征表示,从而在整个网络层稳定地提高预测性能。
我们引入了特定于行动者的令牌记忆,用于学习不同行动者的特征和习惯
我们的方法在 4 个不同的数据集以及不同的时间配置下进行了验证。在准确性和效率方面,我们的方法均达到了最先进的性能。
内容
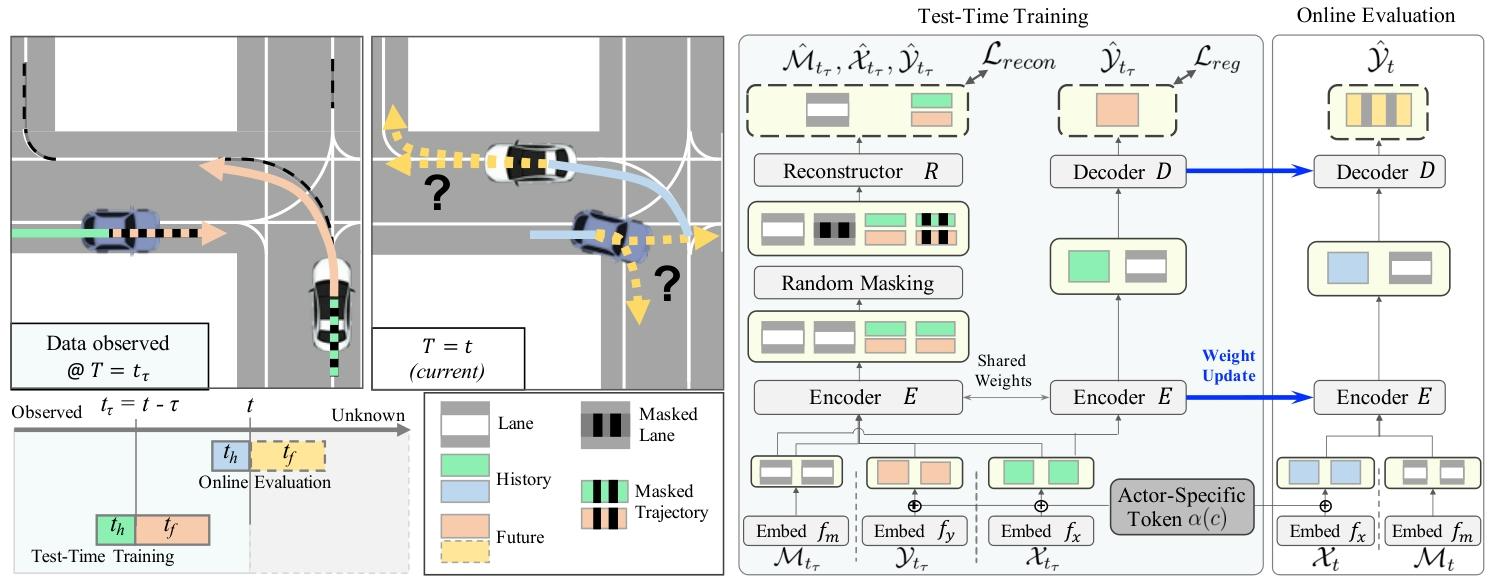
整体框架包括三个阶段:离线训练、测试时训练和在线评估
离线训练在测试前进行,测试时训练和在线评估在测试期间反复且顺序执行
测试

也就是利用过去的信息来训练

相关知识点
ForecastMAE
ForecastMAE: 思路就是利用MAE框架,联合掩码轨迹和道路信息,
掩码
轨迹掩码:对每个智能体(如车辆),随机掩码其历史轨迹或未来轨迹(二选一),迫使模型通过可见部分推断缺失信息。
道路掩码:随机掩码非重叠的车道段,要求模型基于周围车道和智能体轨迹重建被掩码部分
MAE框架:
- 编码器:仅处理可见的轨迹和车道标记(Token),通过标准Transformer块提取特征。
- 解码器:输入掩码标记和编码后的可见标记,重建被掩码的轨迹和车道坐标。
损失函数:
- 轨迹重建:L1损失
- 车道重建:均方误差(MSE)损失
下游任务微调
-
运动预测:丢弃MAE解码器,仅用编码器处理历史轨迹和车道,通过多模态解码器(3层MLP)预测未来轨迹的多个模态(K=6)及置信度。
-
训练目标:Huber损失(轨迹回归) + 交叉熵损失(置信度分类),采用“赢家通吃”策略优化最佳预测。
trajdata
trajdata 是一个强大且灵活的Python库,提供了一个统一的接口来处理和加载多种人类轨迹数据集,包括nuScenes、Lyft Level 5、Waymo Open Motion和INTERACTION等。这个库旨在简化多源数据集的使用,提高研究和开发中对行人轨迹预测任务的数据预处理和加载效率。