RAG文献阅读——用于知识密集型自然语言处理任务的检索增强生成
目录
摘要
Abstract
1 引言
2 RAG
2.1 模型
2.1.1 RAG-Sequence
2.1.2 RAG-Token
2.2 检索器:DPR
2.3 生成器:BART
2.4 训练
2.5 解码
2.6 实验
总结
摘要
本周阅读的论文题目是《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》(《用于知识密集型自然语言处理任务的检索增强生成》)。大型预训练语言模型已被证明能够在其参数中存储事实知识,并在对下游 NLP 任务进行微调时取得最先进的成果。然而,它们访问和精确操作知识的能力仍然有限,因此在知识密集型任务上,它们的性能落后于特定架构。此外,为它们的决策提供证据和更新其世界知识仍然是开放的研究问题。到目前为止,具有可微分访问机制的预训练模型仅被用于研究提取下游任务。本文探索了一种通用的检索增强生成(RAG)微调配方——这些模型结合了预训练的参数和非参数记忆进行语言生成。通过引入了 RAG 模型,其中参数记忆是一个预训练的 seq2seq 模型,非参数记忆是维基百科的密集向量索引,通过预训练的神经检索器进行访问。 并通过在数据集上的对比实验证明了非参数记忆可以被替换以更新模型的知识,以适应世界的变化。
Abstract
This week's paper is titled "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." Large pretrained language models have been shown to be able to store factual knowledge in their parameters and achieve state-of-the-art results when fine-tuning downstream NLP tasks. However, their ability to access and manipulate knowledge with precision is still limited, so their performance lags behind specific architectures on knowledge-intensive tasks. In addition, providing evidence for their decision-making and updating their knowledge of the world remains an open research question. Until now, pre-trained models with differentiable access mechanisms have only been used to study extraction downstream tasks. In this paper, we explore a general-purpose retrieval-enhanced generation (RAG) fine-tuning recipe that combines pre-trained parametric and non-parametric memories for language generation. By introducing the RAG model, where parametric memory is a pre-trained seq2seq model and non-parametric memory is a dense vector index of Wikipedia, accessed through a pre-trained neural retriever. Through comparative experiments on datasets, it is proved that non-parametric memory can be replaced to update the knowledge of the model to adapt to the changes in the world.
1 引言
预训练的神经语言模型已被证明可以在没有任何外部记忆访问的情况下从数据中学习大量的深入知识,作为参数化的隐式知识库。虽然这种发展令人兴奋,但这些模型也存在一些缺点:它们无法轻松扩展或修改其记忆,无法直接提供对其预测的见解,并且可能会产生“幻觉”。
然而,结合参数化记忆和非参数化(即基于检索的)记忆的混合模型可以解决这些问题,因为知识可以直接修改和扩展,并且可以检查和解释访问到的知识。在这里,将混合参数和非参数记忆引入“NLP 的主力”,即序列到序列(seq2seq)模型,通过一种通用的微调方法,将非参数记忆赋予预训练的参数化记忆生成模型,即检索增强生成(RAG)。本文中构建的RAG模型中,参数化记忆是一个预训练的seq2seq转换器,非参数记忆是维基百科的密集向量索引,通过预训练的神经检索器访问,如下图所示,将这些组件结合在一个端到端训练的概率模型中:
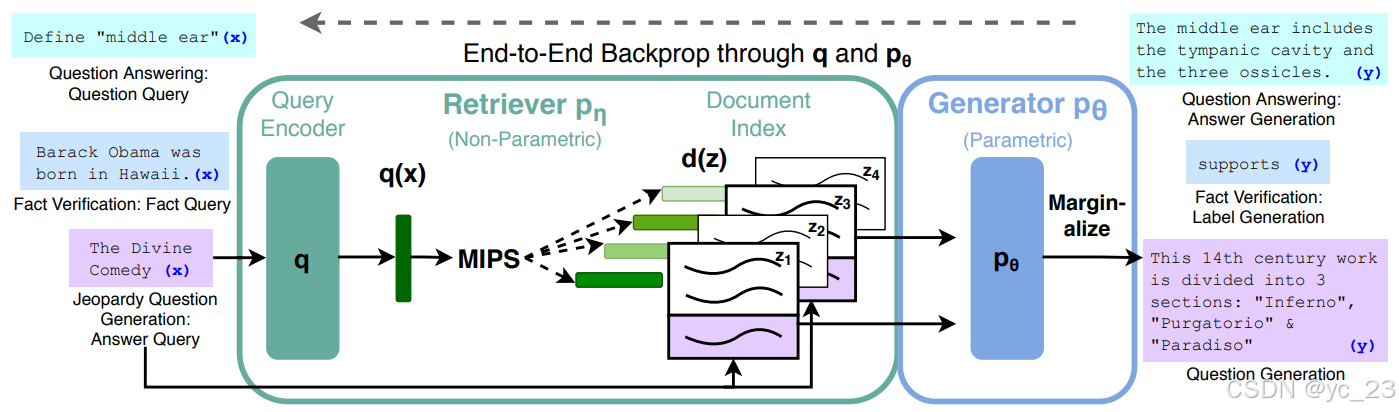
将预训练的密集篇章检索器(即DPR,用于查询编码器+文档索引)与预训练的seq2seq模型(生成器,例如BART)相结合:
- DPR根据输入提供条件化的潜在文档;
- BART根据这些潜在文档和输入一起生成输出;
- 最后进行端到端微调,生成器和检索器共同学习。
对于查询 ,使用最大内积搜索(MIPS)找到top-K文档
。对于最终的预测
,将
视为潜在变量,并对给定不同文档的seq2seq预测进行边缘化。
已有大量先前工作提出了旨在通过非参数记忆来丰富系统的架构,这些架构是从头开始针对特定任务进行训练的,例如记忆网络、堆叠增强网络和记忆层。相比之下,RAG探索了一种新的设定,其中参数和非参数记忆组件都进行了预训练并加载了丰富的知识,并且通过使用预训练的访问机制,无需额外训练即可具备访问知识的能力。
2 RAG
RAG模型使用输入序列 检索文本文档
,并在生成目标序列
时将它们作为额外的上下文。如之前图中所示,RAG模型利用两个组件:
- 检索器
:具有参数
,它根据查询
返回(top-K截断)文本段落分布;
- 生成器
:其参数化由
生成当前标记,该标记基于前
个标记
、原始输入
的上下文。
为了端到端训练检索器和生成器,将检索到的文档视为潜在变量。并提出了两种模型,以不同的方式对潜在文档进行边缘化,以生成生成文本的分布:
- RAG-Sequence:使用相同的文档来预测每个目标标记。
- RAG-Token:可以基于不同的文档预测每个目标标记。
以下,将学习这两种模型,并了解 和
分量以及训练和解码过程。
2.1 模型
2.1.1 RAG-Sequence
RAG-Sequence模型使用相同的检索文档来生成完整的序列,它将检索到的文档视为单个潜在变量,通过top-K近似来边缘化以获得seq2seq概率 。具体来说,使用检索器检索前K个文档,生成器为每个文档生成输出序列概率,然后进行边缘化:
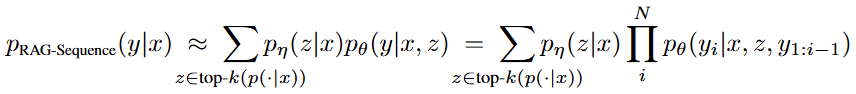
2.1.2 RAG-Token
RAG-Token模型可以为每个目标标记绘制不同的潜在文档,并相应地进行边缘化。这允许生成器在生成答案时从多个文档中选择内容。具体来说,使用检索器检索前K个文档,然后生成器为每个文档生成下一个输出标记的分布,在边缘化之后,重复使用下一个输出标记进行过程:
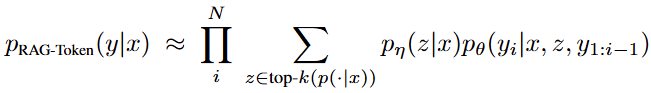
最后,通过将目标类别视为长度为1的目标序列,RAG可以用于序列分类任务,在这种情况下,RAG-Sequence和RAG-Token是等效的。
2.2 检索器:DPR
检索分量 基于DPR,DPR遵循双编码器架构:
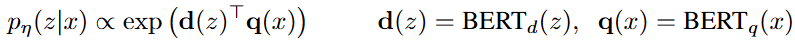
其中:
是由
文档编码器生成的文档的密集表示;
是由同样基于
- 计算top-k
,即具有最高先验概率
使用来自DPR的预训练双编码器来初始化检索器并构建文档索引,该检索器被训练来检索包含TriviaQA问题和Natural Questions答案的文档,把文档索引称为非参数记忆。
2.3 生成器:BART
生成器组件 可以使用任何编码器-解码器建模:
- 本文中使用BART-large,一种预训练的seq2seq Transformer,具有400M参数;
- 为了在从BART生成时将输入
- BART使用去噪目标和各种不同的去噪函数进行预训练;
- 将BART发生器参数
2.4 训练
联合训练检索器和生成器组件,没有任何关于应检索哪些文档的直接监督。给定一个输入/输出对 的微调训练语料库,使用Adam的随机梯度下降最小化每个目标的负边际对数似然
。
更新文档编码器BERT在训练中是昂贵的,因为它需要定期更新文档索引,并且这一步也不是必要的。所以在保持文档编码器(和索引)固定的情况下,只微调查询编码器和BART生成器。
2.5 解码
在测试时,RAG-Sequence和RAG-Token需要不同的方法来近似 :
- 对于RAG-Token模型:
- 可以将其视为标准的自回归seq2seq生成器,在该模型中,使用转移概率来计算后验概率:
;
- 为了进行解码,可以将
插入标准束解码器中。
- 可以将其视为标准的自回归seq2seq生成器,在该模型中,使用转移概率来计算后验概率:
- 对于RAG-Sequence模型,后验概率
不能被打破成传统的基于token的概率形式,因此无法使用单束搜索来解决它,相反,为每个文档
为每个假设打分,这产生了一组假设
,其中一些可能没有出现在所有文档的束中,所以产生以下两种解码方式:
- 彻底解码:为了评估一个假设
的概率,为未出现在束中的每个文档
- 快速解码:对于更长的输出序列,
可能变得很大,需要运行许多前向传递,为了更有效地进行解码,可以做进一步的近似,即假设
,其中
的束搜索中生成,这避免了在生成候选集Y之后运行额外的前向传递的需要。
- 彻底解码:为了评估一个假设
2.6 实验
本文在广泛的以知识密集型任务中实验RAG:
- 实验分为开放域问答、抽象式问答、猜谜问题生成和事实核查;
- 对于所有实验,使用单个维基百科数据集作为我们的非参数知识源;
- 每个维基百科文章被分割成不重叠的 100 词块,总共形成 2.1 亿个文档;
- 使用文档编码器为每个文档计算嵌入,并使用FAISS构建一个单一生成的MIPS索引,使用层次可导航小世界近似进行快速检索;
- 在训练过程中,为每个查询检索前k个文档;
- 考虑
进行训练,并使用开发数据设置测试时的k值。
总结
本文提出了具有参数和非参数记忆访问的混合生成模型RAG。相对于纯参数的BART,RAG的生成更符合事实和具体,并且RAG在不要求任何重新训练的情况下就能通过热插拔检索索引以更新模型。本文中还比较了两种 RAG 公式,一种是在整个生成的序列中对相同的检索段落进行条件化,另一种则可以每个标记使用不同的段落。RAG开辟了关于参数和非参数记忆如何相互作用以及如何最有效地结合它们的新研究方向,显示出在应用于各种 NLP 任务中的潜力。
RAG更深入地基于真实的事实知识,使得它在更注重事实的世代中“幻觉”更少,并提供了更多的控制和可解释性。RAG 可以在各种场景中使用,对社会产生直接的好处,例如通过赋予它医学索引并就这一主题提出开放领域的问题,或者通过帮助人们更有效地完成工作。
但是同时RAG也存在着一些潜在的缺点:维基百科或任何潜在的外部知识源可能永远无法完全客观和完全无偏见。由于 RAG 可以用作语言模型,所以它可能被用来生成新闻或社交媒体上的滥用、虚假或误导性内容、冒充他人或自动化生产垃圾邮件/网络钓鱼内容 。
所以,在未来的工作中,进行多源知识融合,以避免依赖单一知识源(如维基百科),整合多语言、多视角的权威数据源(如学术论文、政府公开数据、可信媒体库),降低单一来源的偏见;对生成内容的控制与限制。强化伦理约束,确保生成内容符合道德规范等方式来进行研究。