深度学习总结(10)
TensorFlow
训练神经网络主要围绕以下概念进行。
首先是低阶张量操作。这是所有现代机器学习的底层架构,可以转化为TensorFlow API。
张量,包括存储神经网络状态的特殊张量(变量)。
张量运算,比如加法、relu、matmul。
反向传播,一种计算数学表达式梯度的方法(在TensorFlow中通过GradientTape对象来实现)。
然后是高阶深度学习概念。这可以转化为Keras API。
层,多层可以构成模型。
损失函数,它定义了用于学习的反馈信号。
优化器,它决定学习过程如何进行。
评估模型性能的指标,比如精度。训练循环,执行小批量梯度随机下降。
常数张量和变量
要使用TensorFlow,需要用到张量。创建张量需要给定初始值。可以创建全1张量或全0张量,也可以从随机分布中取值来创建张量。
代码清单 全1张量或全0张量
import tensorflow as tf
#等同于np.ones(shape=(2, 1))
x = tf.ones(shape=(2, 1))
print(x)
#等同于np.zeros(shape=(2, 1))
x = tf.zeros(shape=(2, 1))
print(x)
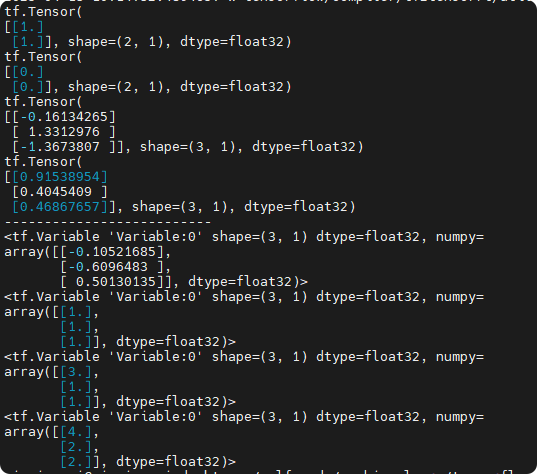
tf.Tensor(
[[1.]
[1.]], shape=(2, 1), dtype=float32)
tf.Tensor(
[[0.]
[0.]], shape=(2, 1), dtype=float32)
代码清单 随机张量
#从均值为0、标准差为1的正态分布中抽取的随机张量,等同于np.random.normal(size=(3, 1), loc=0., scale=1.)
x = tf.random.normal(shape=(3, 1), mean=0., stddev=1.)
print(x)
# ←----从0和1之间的均匀分布中抽取的随机张量,等同于np.random.uniform(size=(3, 1), low=0., high=1.)
x = tf.random.uniform(shape=(3, 1), minval=0., maxval=1.)
print(x)
tf.Tensor(
[[0.14704846]
[1.0228435 ]
[1.5658393 ]], shape=(3, 1), dtype=float32)
tf.Tensor(
[[0.73094225]
[0.16863608]
[0.27103436]], shape=(3, 1), dtype=float32)
TensorFlow张量是不可赋值的,它是常量。在NumPy中,你可以执行以下操作。
import numpy as np
x = np.ones(shape=(2, 2))
x[0, 0] = 0.
如果在TensorFlow中执行同样的操作),那么程序会报错。
代码清单 TensorFlow张量是不可赋值的
#←----程序会报错,因为张量是不可赋值的
x = tf.ones(shape=(2, 2))
x[0, 0] = 0.
要训练模型,我们需要更新其状态,而模型状态是一组张量。如果张量不可赋值,这时就需要用到变量(variable)。tf.Variable是一个类,其作用是管理TensorFlow中的可变状态。要创建一个变量,你需要为其提供初始值。通过打印变量(variable),我们可以看到它和之前的tensorflow里面的张量是不同的。
代码清单 创建一个TensorFlow变量
v = tf.Variable(initial_value=tf.random.normal(shape=(3, 1)))
print(v)
<tf.Variable 'Variable:0' shape=(3, 1) dtype=float32, numpy=
array([[ 1.0559866 ],
[ 0.28642738],
[-1.1775647 ]], dtype=float32)>
变量的状态可以通过其assign方法进行修改。
代码清单 为TensorFlow变量赋值
v.assign(tf.ones((3, 1)))
这种方法也适用于变量的子集。
代码清单 为TensorFlow变量的子集赋值
v[0, 0].assign(3.)
assign_add()和assign_sub()分别等同于+=和-=的效果。
代码清单 使用assign_add()
v.assign_add(tf.ones((3, 1)))
张量运算:用TensorFlow进行数学运算
TensorFlow提供了许多张量运算来表达数学公式。
a = tf.ones((2, 2))
#求平方
b = tf.square(a)
# 求平方根
c = tf.sqrt(a)
# 两个张量(逐元素)相加
d = b + c
# ←----计算两个张量的点积
e = tf.matmul(a, b)
# 两个张量(逐元素)相乘
e *= d
GradientTape API
通过tensorflow,只需要创建一个GradientTape作用域,对一个或多个输入张量做一些计算,然后就可以检索计算结果相对于输入的梯度,
代码清单 使用GradientTape
input_var = tf.Variable(initial_value=3.)
with tf.GradientTape() as tape:
result = tf.square(input_var)
gradient = tape.gradient(result, input_var)
要检索模型损失相对于权重的梯度,最常用的方法是gradients = tape.gradient(loss,weights)。。至此,你只遇到过tape.gradient()的输入张量是TensorFlow变量的情况。实际上,它的输入可以是任意张量。但在默认情况下只会监视可训练变量(trainable variable)。如果要监视常数张量,那么必须对其调用tape.watch(),手动将其标记为被监视的张量。
代码清单 对常数张量输入使用GradientTape
input_const = tf.constant(3.)
with tf.GradientTape() as tape:
tape.watch(input_const)
result = tf.square(input_const)
gradient = tape.gradient(result, input_const)
之所以必须这么做,是因为如果预先存储计算梯度所需的全部信息,那么计算成本非常大。为避免浪费资源,梯度带需要知道监视什么。它默认监视可训练变量,因为计算损失相对于可训练变量列表的梯度,是梯度带最常见的用途。梯度带是一个非常强大的工具,它甚至能够计算二阶梯度(梯度的梯度)。举例来说,物体位置相对于时间的梯度是这个物体的速度,二阶梯度则是它的加速度。如果测量一个垂直下落的苹果的位置随时间的变化,并且发现它满足position(time) =4.9 * time ** 2,那么它的加速度是多少?我们可以用两个嵌套的梯度带找出答案。
time = tf.Variable(0.)
with tf.GradientTape() as outer_tape:
with tf.GradientTape() as inner_tape:
position = 4.9 * time ** 2
speed = inner_tape.gradient(position, time)
#内梯度带计算出一个梯度,我们用外梯度带计算这个梯度的梯度。答案自然是4.9 * 2 = 9.8
acceleration = outer_tape.gradient(speed, time)
本文全部可执行代码贴出:
import tensorflow as tf
#等同于np.ones(shape=(2, 1))
x = tf.ones(shape=(2, 1))
print(x)
#等同于np.zeros(shape=(2, 1))
x = tf.zeros(shape=(2, 1))
print(x)
#从均值为0、标准差为1的正态分布中抽取的随机张量,等同于np.random.normal(size=(3, 1), loc=0., scale=1.)
x = tf.random.normal(shape=(3, 1), mean=0., stddev=1.)
print(x)
# ←----从0和1之间的均匀分布中抽取的随机张量,等同于np.random.uniform(size=(3, 1), low=0., high=1.)
x = tf.random.uniform(shape=(3, 1), minval=0., maxval=1.)
print(x)
print("--------------------------")
v = tf.Variable(initial_value=tf.random.normal(shape=(3, 1)))
print(v)
v.assign(tf.ones((3, 1)))
print(v)
v[0, 0].assign(3.)
print(v)
v.assign_add(tf.ones((3, 1)))
print(v)
a = tf.ones((2, 2))
#求平方
b = tf.square(a)
# 求平方根
c = tf.sqrt(a)
# 两个张量(逐元素)相加
d = b + c
# ←----计算两个张量的点积
e = tf.matmul(a, b)
# 两个张量(逐元素)相乘
e *= d
input_var = tf.Variable(initial_value=3.)
with tf.GradientTape() as tape:
result = tf.square(input_var)
gradient = tape.gradient(result, input_var)
input_const = tf.constant(3.)
with tf.GradientTape() as tape:
tape.watch(input_const)
result = tf.square(input_const)
gradient = tape.gradient(result, input_const)
time = tf.Variable(0.)
with tf.GradientTape() as outer_tape:
with tf.GradientTape() as inner_tape:
position = 4.9 * time ** 2
speed = inner_tape.gradient(position, time)
#内梯度带计算出一个梯度,我们用外梯度带计算这个梯度的梯度。答案自然是4.9 * 2 = 9.8
acceleration = outer_tape.gradient(speed, time)
运行结果: