多模态大模型[CLIP/Flamingo/Coca/BLIP]
这篇文章主要是对模型架构的简介,适合于有一定深度学习以及cv/nlp基础的人了解一些多模态模型的架构。如有问题,请随时指正,非常感谢!
1. Learning Transferable Visual Models From Natural Language Supervision
[2103.00020] Learning Transferable Visual Models From Natural Language Supervision
【可忽略以下文本直接看 CLIP 论文逐段精读【论文精读】_哔哩哔哩_bilibili 对CLIP的讲解,非常棒!】
思路:将图像和文本都分别进图像编码器和文本编码器后生成图像向量和文本向量,计算两个向量的cosine相似度得分。为了使得配对的图片和文本的得分高,不配对的图片和文本的得分低,使用交叉熵损失。
这种对比学习的损失函数,相比生成任务的损失函数来说,对于图像分类任务更高效,可以使用较少的参数就能得到相近的准确率。
训练过程伪代码:

【 为什么labels的维度是n?为什么要分别在axis=0和axis=1两个不同的维度分别计算,为什么不直接计算n*n整个矩阵的交叉熵损失?应该是为了跨模态对齐的对称性和鲁棒性,使两个模态的嵌入空间能充分交互和相互约束。】
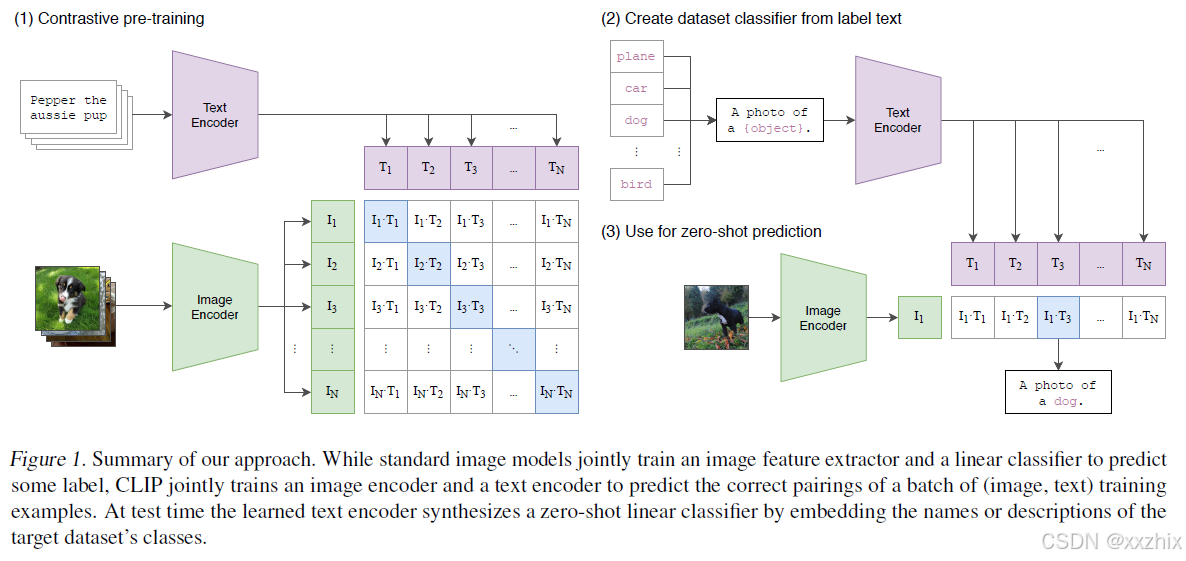
使用clip做zero-shot进行图片分类
CLIP预训练的任务是将图片和文本配对,可以得到较好的图片和文本向量表示。
在迁移做图像分类时,将所有你需要的类别名称作为文本,将要分来的图片作为图像,文本和图片分别进入文本和图片编码模型得到向量表示,计算cosine相似度,使用temperature做scale,通过softmax函数计算概率分布,概率最大的标签文本就作为图片分类。
2.Flamingo: a Visual Language Model for Few-Shot Learning
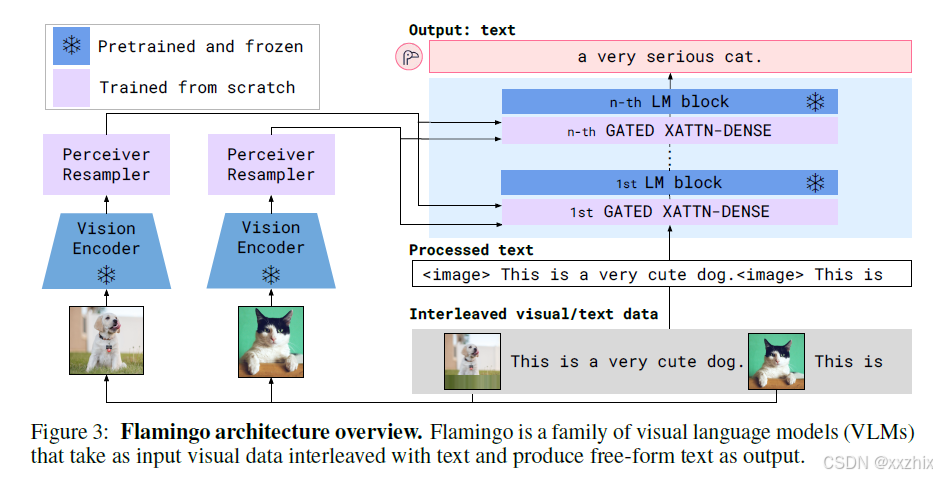
Flamingo接收文本和图片相间隔作为输入,示例: "[图片1] 文本 [图片2] 文本 [图片3] 文本" ,输出文本。在上图示例中,第一张狗图片和文本是few-shot,不是zero-shot的,论文是针对few shot的场景。
上图中Perceiver Resampler以Vision Encoder输出的特征作为输入,输出固定个数的visual token。
Vision Encoder: 将像素转换成特征。Vision encoder使用的模型是Normalizer-Free ResNet,预训练目标是image-text的对比学习,将最终阶段的2D 网格特征拉平成1D的序列特征。对于视频输入,按每1 FPS抽样并独立编码得到3D网格特征,然后拉平成1D的序列特征。无论图像还是视频,拉平后的1D序列特征作为输入喂给Perceiver Resampler。
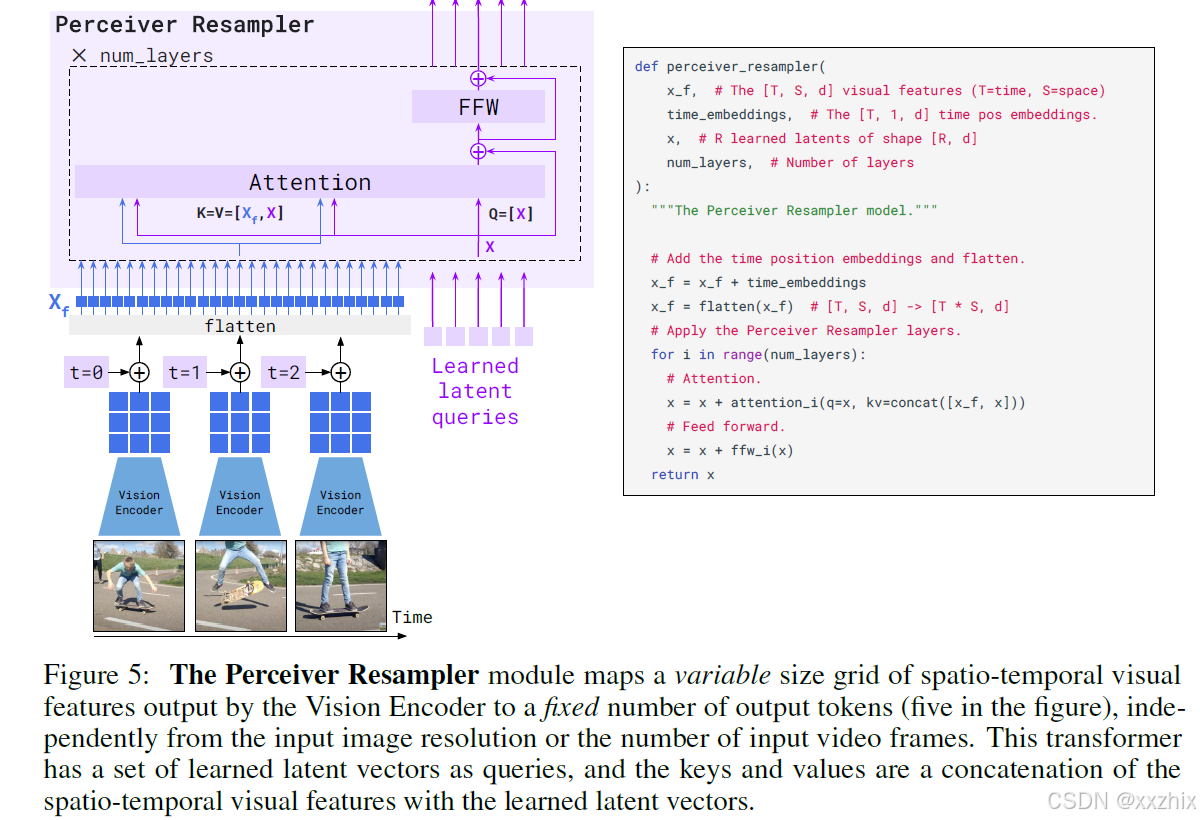
Perceiver Resampler: 将任意大小的大特征映射到少数visual tokens。这个部分连接Vision Encoder和LLM, 学习预定义个数的latent input queries输入Transformer,和visual feature做cross attention计算, visual features作为k,v。学习后的latent query作为输出的固定个数的visual token,也就是当作图像的特征表示。
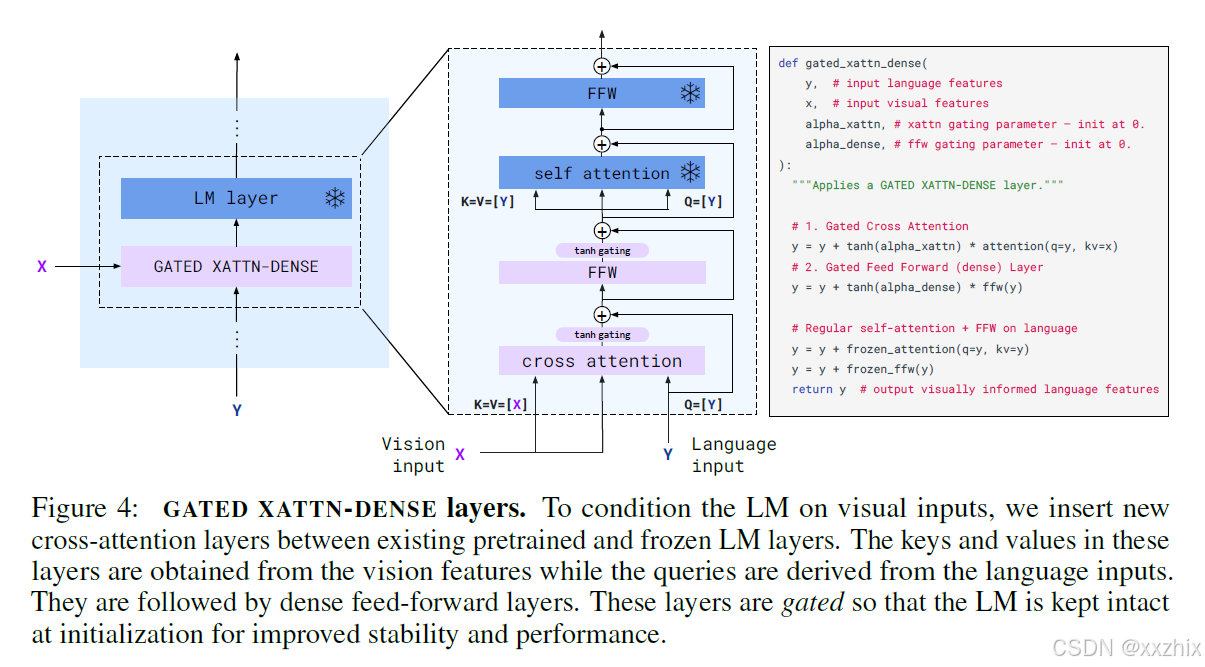
GATED XATTN-DENSE: 将gated cross-attention dense blocks插入预训练的参数冻结的语言模型层中间,这个预训练的语言模型结构是transformer decoder结构。cross attention做计算的key和value是Perceiver Resampler的输出,即图像特征,queries是文本特征。gated cross-attention dense层的参数从头开始训练,得到的输出是含视觉信息的。
为了训练稳定性和最终模型表现,在初始化的时候,将新加入的层的输出乘以,
初始化设置为0。这样,在训练最开始,预训练的语言模型得到的输入是和没有添加层的输入一样的。
训练目标是语言模型融入视觉信息后进行next token predition。假设Flamingo模型计算了给定图像/视频和文本交叉作为输入,得到输出文本
的概率似然。
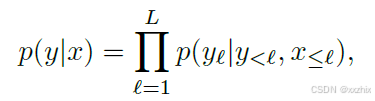
其中,是文本中第
个token,
表示的是第
个之前的token,
表示第
个token之前的所有图像/视频。
3. CoCa: Contrastive Captioners are Image-Text Foundation Models
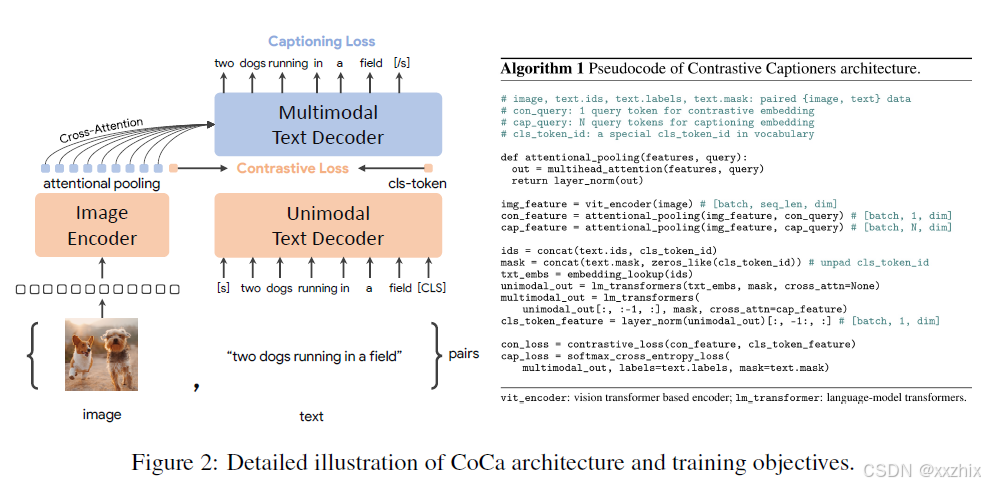
Coca是一个编码器和解码器结构,Image Encoder编码图像特征,文本解码器和标准的transformer decoder不同,Coca在前一半数量的layers忽略cross-attention来编码文本特征,在剩下的layers中,将图像特征进行cross attention做text decoder。包含Contrastive loss和Captioning Loss两部分,目标函数为:![]() 其中,
其中,![]() ,
,是标准化后的图像和文本表示。caption的自回归损失为
![]() 。
。
在上图的伪代码中,con_feature和cap_feature是将img_feature生成了不同数量的新的向量表示。论文中提到是因为实验表明一个向量对visual recognition任务足够,而多个visual token对多模态理解任务有利。所以con_feature的设为1, cap_feature的设为256。
4. BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
预训练框架
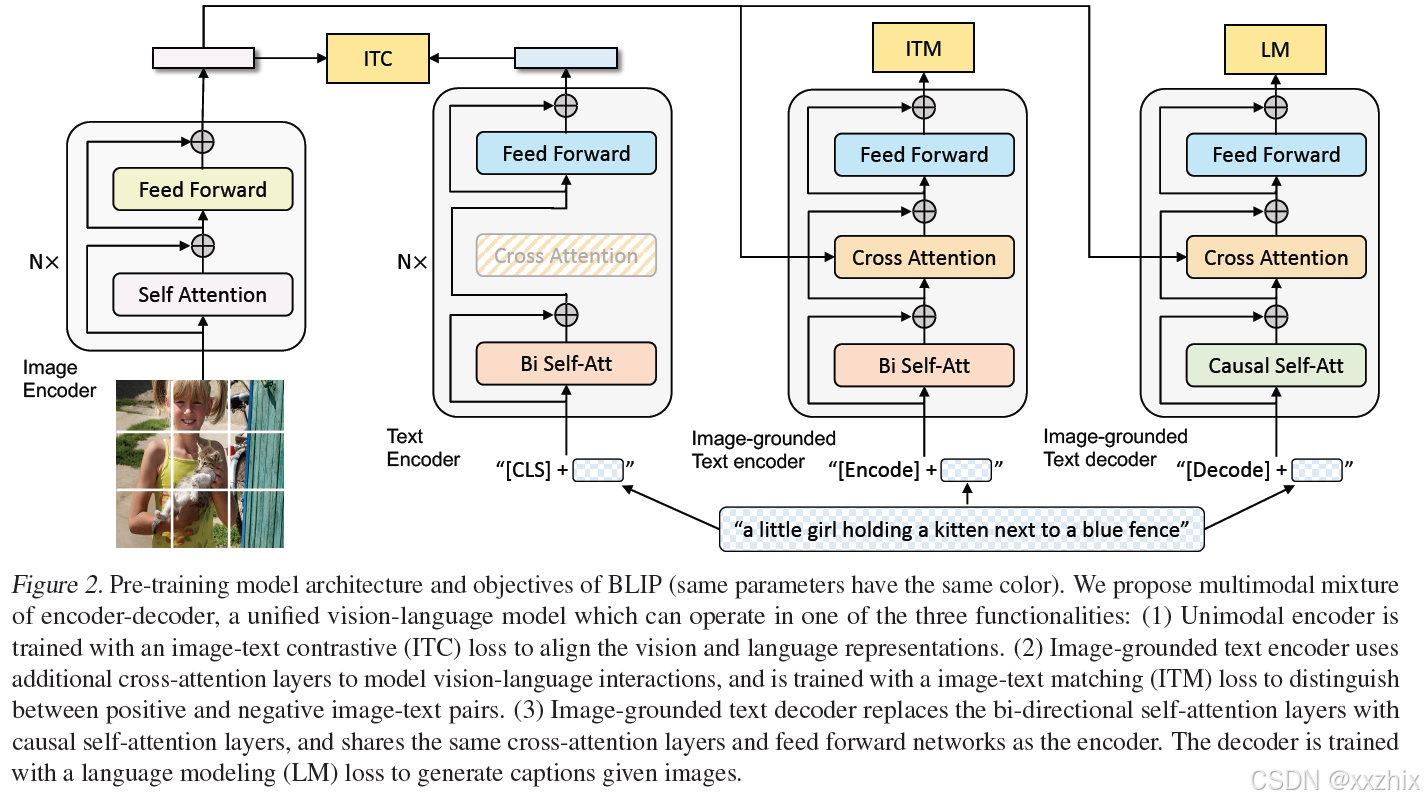
Image Encoder是使用visual transformer,将输入图片切分成patches,编码成embeddings,添加一个[CLS] token来对应整个图片特征的embedding。使用ViT作为提取图片特征的模型。
为使预训练模型同时具有理解和生成能力,提出多模态多任务的编码和解码模型,有3个功能块:
1.Unimodal encoder。对文本和图像分别编码。
2.Image-grounded text encoder。通过在编码文本的transformer模型的self-attention和ffn层之间插入cross-attention层【这里的self-attention层是双向的自注意力】,从而在文本编码过程中加入图片信息。在文本中添加 [Encode] token对应融入了image信息的text embedding。
【为什么要使用bi-directional的self-attention?这里的文本编码器用的bert,bert是双向的。】
3.Image-grounded text decoder。将2中的双向自注意力替换成含mask的casual self-attention layer。而embedding层,cross-attention层和FFN层是和2一致的,参数共享的。这样可以提升训练效率。[Decode] token作为序列的开头来预测下一个token,另一个token作为结束信号。
预训练目标(多任务):
1. Image-Text Contrastive Loss(ITC) 是希望经过单模态的图像编码器和文本编码器后,配对的image-text得到的向量表示相较于不配对的image-text更相近。其中,单模态编码器使用的是momentum encoder。使用的是对比学习损失函数。
【momentum encoder是什么?momentum contrast在《Momentum contrast for unsupervised visual representation learning》的论文中提到,主要思路是使用加权更新模型参数,具体可以看MoCo 论文逐段精读【论文精读】_哔哩哔哩_bilibili,对MoCo讲得非常棒!】
【ITC损失参考的是论文Align befor Fuse】
对比学习损失函数为:![]()
其中,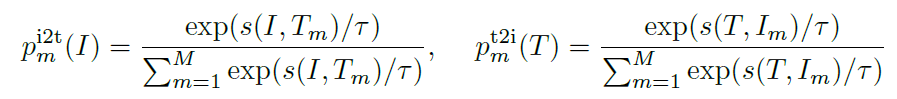
![]() ,
,![]()
分别是linear层,对embedding降维到固定维,譬如256维。
分别是image和text经momentum encoder后的整体特征embedding。
分别是momentum encoder后经归一化的embedding表示。
2.Image-Text Matching Loss(ITM)是希望学习细粒度对齐的image-text的多模态表示。ITM是一个二分类任务,模型使用ITM head(一个线性层)来预测image-text是否配对。
【hard negative mining strategy: 参考论文 Align before Fuse,hard negative sample是编码后标准化的image embedding和text embedding的相乘后的cosine得分较高但不配对的样本,从image和text维度分别抽样。即和当前image内容相近但实际不匹配的text,以及和当前text内容相近但实际不匹配的image】
3.Language Modeling Loss(LM)是希望生成一段文本描述给定的图片,仍然是next token prediction任务,使用自回归的方式优化交叉熵损失来最大化文本的概率。
BLIP的学习框架,包含预训练任务和数据的更新。
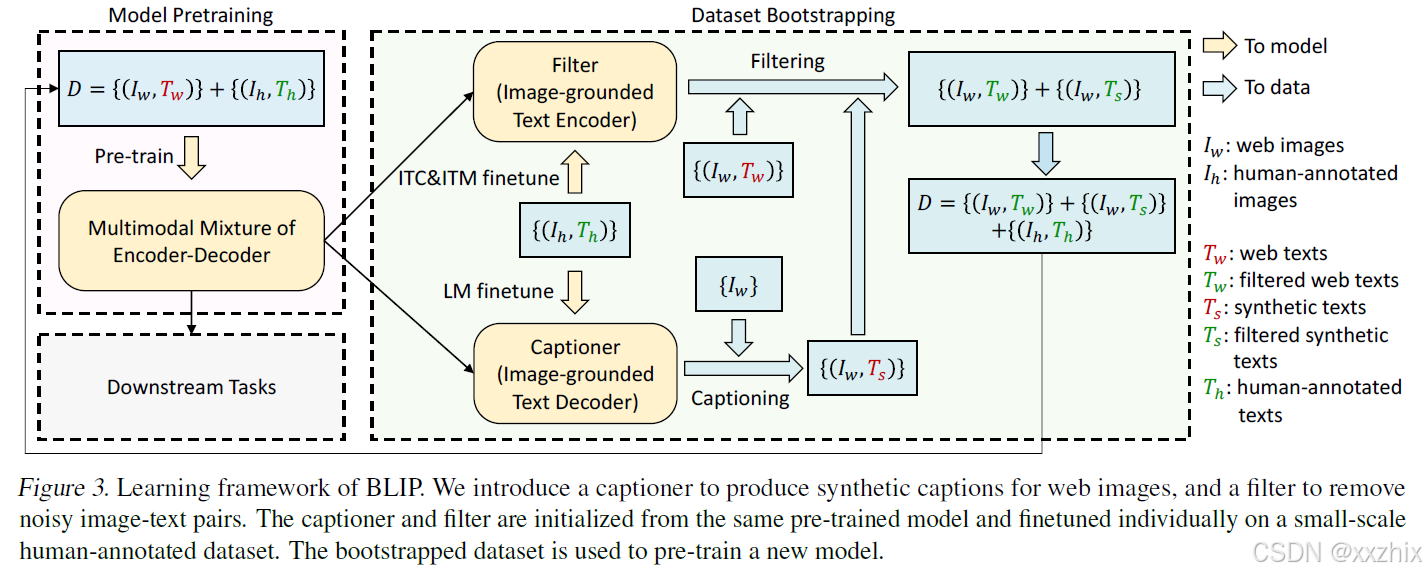
CapFilt,一种提高文本预料质量的方法,具体结构如上图,包含两部分:captioner和filter。captioner基于给定网络图片生成图片描述,filter去除不匹配的image-text对。captioner和filter都使用上面介绍的多模态的编码和解码模型预训练结果做初始化,然后使用新的数据集微调。
Captioner是一个以图片为基础的文本解码,给定图片, captioner生成说明文本
。
Filter根据ITC和ITM损失微调,判断image-text对是否匹配,包括网络图片对应的网络文本和Captioner生成文本
,ITM head认为不匹配则去除。保留下来的image-text 对,与人工标注的image-text对合并生成,生成新的数据集,重新预训练一个新的模型。
5.BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
整体框架:
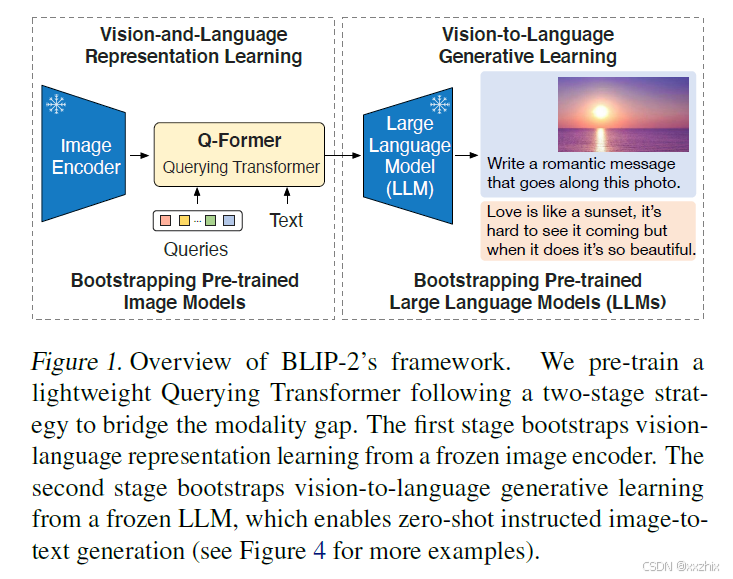
预训练分两个阶段,第一个阶段是从参数被冻结的image encoder模型学习视觉信息的表示。第二个阶段时从参数冻结的LLM学习从视觉到文本的生成。
优点:1.有效使用frozen image encoder和frozen LLM,提出Q-Former结构来连接。2.能加入prompt做image-to-text generation任务。3.Q-Fromer参数量小,image encoder和LLM参数冻结,使得训练效率高。而且能利用更好的单模态模型来得到更好的效果。
第一阶段:训练Q-Former,多任务,不同任务采用不同的mask策略。
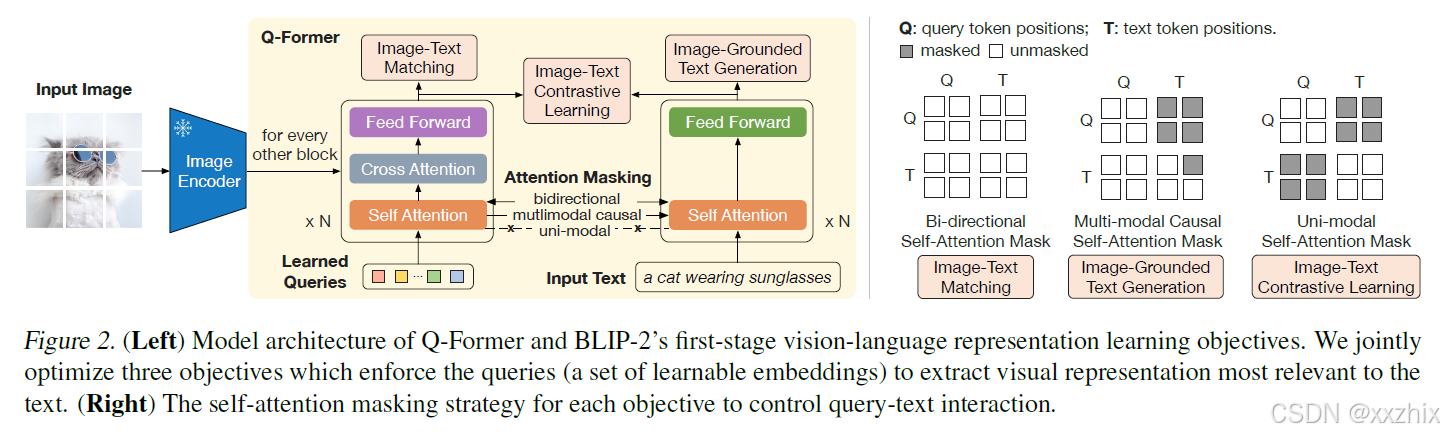
1.Image-Text Contrastive Learning(ITC)对齐图像表示和文本表示。从左边的image transformer输出query representation , 从右边的text transformer得到文本表示
,
是添加的 [CLS] token对应的表示整个文本信息的向量表示。由于有多个queries,首先计算
和每一个query对应的
的相似度,然后选择最高的相似度作为image-text的相似度。
mask策略:query和text在self-attention阶段,query只能跟query计算,text被masked,query无法和text计算;text同理。
2.Image-Grounded Text Generation(ITG)以给定image为条件,生成文本。
mask策略:text可以跟本身及之前的text,以及query做计算。query只能跟query做计算。
原因:生成text需要加入视觉信息,query含视觉信息。生成text做next token prediction的时候只能看到当前及之前的内容。
3.Image-Text Matching(ITM)对齐细粒度的图像表示和文本表示,二分类任务判断image-text是否匹配。
mask策略:query可以和query及text做计算,text可以和query及text做计算。
query output representation 包含了多模态的信息,将每一个query对应的
作为输入进入分类层得到logit值,然后计算平均值作为匹配得分。
第二阶段:图像到文本生成
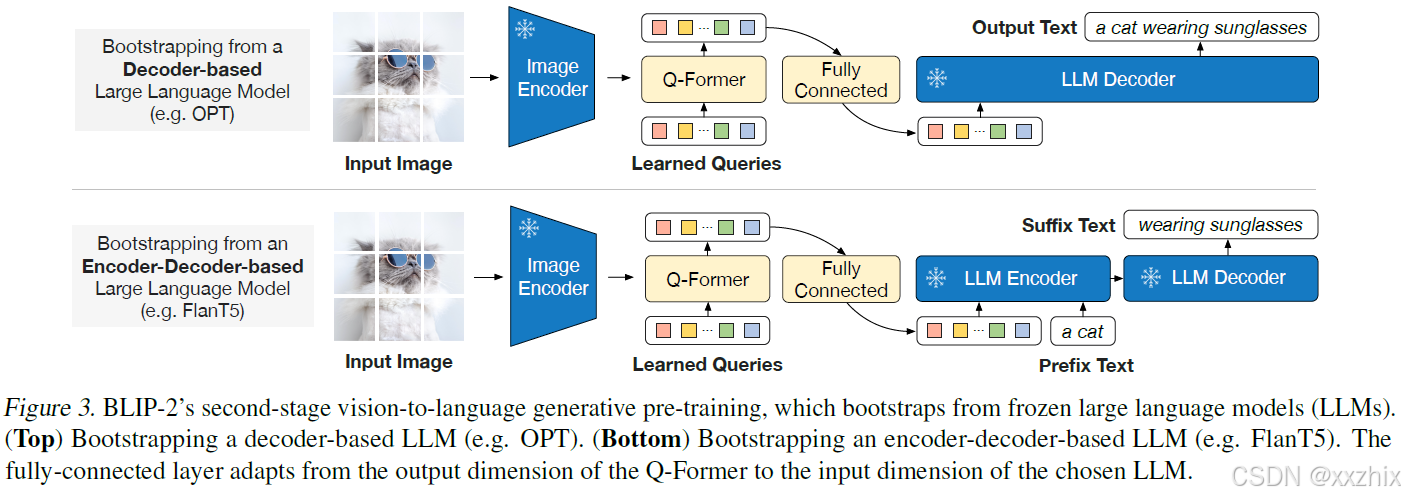
Q-Former输出的query embedding 经过线性全连接层映射到和LLM的text embedding相同的维度,然后映射后的query embedding添加到text embedding前面进入LLM Decoder进行文本生成,其作用向相当于soft visual prompts,以Q-Former提取的视觉表示作为视觉prompts。
试验了decoder-based和encoder-decoder-based两种类型。encoder-decoder是将text拆分成两部分,前面一部分和query embedding拼接在一起作为LLM encoder的输入。
碎碎念总结:
1. 跨模态的对齐一般使用单模态编码后的向量的对比学习目标函数。视觉特征可能转换成少量的visual token来跟文本特征做对比。
2.模态交互一般是cross-attention结构。