【PyTorch项目实战】反卷积(Deconvolution)
文章目录
- 一、卷积(Convolution)
- 二、反卷积(Deconvolution) —— 又称去卷积
- 1. 反卷积(Richardson-Lucy,RL) —— —— 通过不断迭代更新图像估计值
- 2. 转置卷积(Transpose Convolution):torch.nn.ConvTranspose2d()
- (1)基础版本
- (2)增强版本:网络深度 + 残差网络 + 正则化
- 3. 分数步幅卷积(Fractionally Strided Convolution):torch.nn.ConvTranspose2d()
卷积(Convolution):是一种通过滑动窗口(卷积核)遍历整个图像,对每个像素进行加权求和的操作。
- 应用:
滤波器:如高斯滤波减少图像中的噪声、锐化滤波增强图像中的高频信息。边缘检测:如Sobel、Canny突出图像中的边缘。反卷积(Deconvolution):是卷积的逆运算,旨在通过迭代优化方法从模糊图像中恢复原始图像,减少模糊和失真。
- 常见算法:
Richardson-Lucy 反卷积:基于最大似然估计(MLE),通过迭代更新图像估计值来优化恢复效果。Wiener 反卷积:在频域中应用 Wiener 滤波,利用噪声功率谱进行去模糊。盲反卷积(Blind Deconvolution):同时估计模糊核(PSF)和原始图像,适用于未知模糊情况。
彻底搞懂CNN中的卷积和反卷积
GIF制作:卷积动画 + 转置卷积动画 + 膨胀卷积动画
一、卷积(Convolution)
卷积(Convolution)是一种数学操作,通常用于信号处理、图像处理和深度学习中,用于处理二维或多维数据。
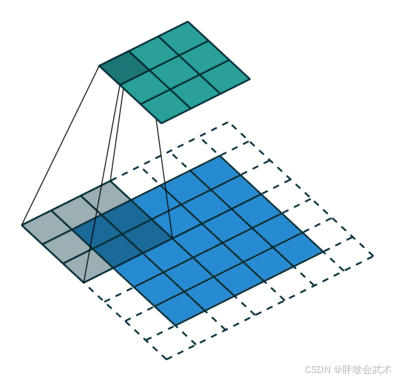
# 输入图像(input):下-蓝色区域(5, 5)
# 卷积核(kernel):下-移动阴影区域(3, 3)
# 填充(padding):下-白色区域(1)
# 步长(stride):下-卷积核每次滑动的长度(1)
# 卷积核的卷积结果:上-移动阴影区域(1, 1)
# 输出图像(output):上-绿色区域(3, 3)
基于核函数的卷积操作(例如:高斯滤波)
二、反卷积(Deconvolution) —— 又称去卷积
反卷积(Deconvolution)、转置卷积(Transpose Convolution) 和 分数步幅卷积(Fractionally Strided Convolution) 是不同的概念。虽然它们有一定的相似性,但其应用、原理和实现方式是不同的。
- 1.
反卷积(Deconvolution)
- 概念:
是卷积的逆操作。采用最小化误差的方式迭代进行,最小化模糊图像与恢复图像之间的差异(例如 Richardson-Lucy)。- 应用:
- 去模糊:用于去除图像中的模糊,例如相机抖动引起的模糊。
- 盲反卷积:同时恢复图像和模糊核(PSF),用于图像恢复。
- 2.
转置卷积(Transpose Convolution)
- 概念:
并非严格意义上的反卷积。通过零填充(在每两个元素之间插入零)扩展输入图像的空间尺寸,然后再应用卷积操作,实现图像的上采样。- 应用:
- 图像生成:常用于生成对抗网络(GANs)中,将低分辨率的特征图恢复为高分辨率图像。
- 超分辨率:用于将低分辨率图像提升到更高的分辨率。
- 3.
分数步幅卷积(Fractionally Strided Convolution)
- 概念:
是一种介于标准卷积和转置卷积之间的操作。使用较小步幅(例如 1/2 或 1/4)进行卷积操作,实现图像的上采样。- 应用:
- 生成对抗网络(GANs):分数步幅卷积常用于生成对抗网络(GANs)中,用于图像的上采样。
1. 反卷积(Richardson-Lucy,RL) —— —— 通过不断迭代更新图像估计值
Richardson-Lucy (RL) 反卷积算法 —— 通过不断迭代更新图像估计值
2. 转置卷积(Transpose Convolution):torch.nn.ConvTranspose2d()
####################################################################
假设输入图像为 4x4,卷积核为 3x3,步长为 1,没有填充。
输入图像(4x4)
[ 1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16 ]
卷积核(3x3)
[ 0 0 0
0 3 0
0 0 0 ]
####################################################################
1. 普通卷积
输出图像(2x2)
[ 18 21
30 33]
2. 转置卷积(或反卷积)是卷积操作的“逆”过程,目的是将较小的特征图恢复成较大的特征图。
(1)上采样:通过插入零将输入图像变为 6x6。插入的零是在图像的每两个相邻元素之间插入一个零。
(2)该上采样后的图像与卷积核进行普通卷积操作,得到的输出图像尺寸将是 5x5。
插值图像(7x7)
[ 1 0 2 0 3 0 4
0 0 0 0 0 0 0
5 0 6 0 7 0 8
0 0 0 0 0 0 0
9 0 10 0 11 0 12
0 0 0 0 0 0 0
13 0 14 0 15 0 16 ]
输出图像(5x5)
[ 0 0 0 0 0
0 18 0 21 0
0 0 0 0 0
0 30 0 33 0
0 0 0 0 0 ]
(1)基础版本
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import cv2
import numpy as np
def load_image(image_path):
"""加载并预处理图像(灰度或彩色)"""
img = cv2.imread(image_path) # 读取图像
img = img[0:200, 0:200]
if img.shape[2] == 3:
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图
# img = cv2.resize(img, (64, 64)) # 调整图像大小为 64x64
img = np.expand_dims(img, axis=0) # 添加批次维度
img = np.expand_dims(img, axis=0) # 添加通道维度(如果是灰度图)
img = torch.tensor(img, dtype=torch.float32) # 转换为 tensor
img /= 255.0 # 归一化至 [0, 1]
return img
if __name__ == '__main__':
# (1)加载图像
input_image = load_image('image.jpg')
print("Input size: ", input_image.shape) # torch.Size([1, 1, 245, 612])
# (2)创建并执行转置卷积层
conv_transpose = nn.ConvTranspose2d(
in_channels=1, # 输入通道数,1代表灰度图,3代表RGB图
out_channels=1, # 输出通道数
kernel_size=3, # 卷积核大小
stride=2, # 步幅
padding=0, # 填充
output_padding=0 # 输出填充
)
output_image = conv_transpose(input_image)
print("Output size: ", output_image.shape) # torch.Size([1, 1, 491, 1225])
"""####################################################################################
Output Size = Stride × (Input Size − 1) + Kernel Size − 2 × Padding + Output Padding
= 2 × (245 − 1) + 3 − 2 × 0 + 0 = 491
= 2 × (612 − 1) + 3 − 2 × 0 + 0 = 1225
####################################################################################"""
# (3)可视化图像
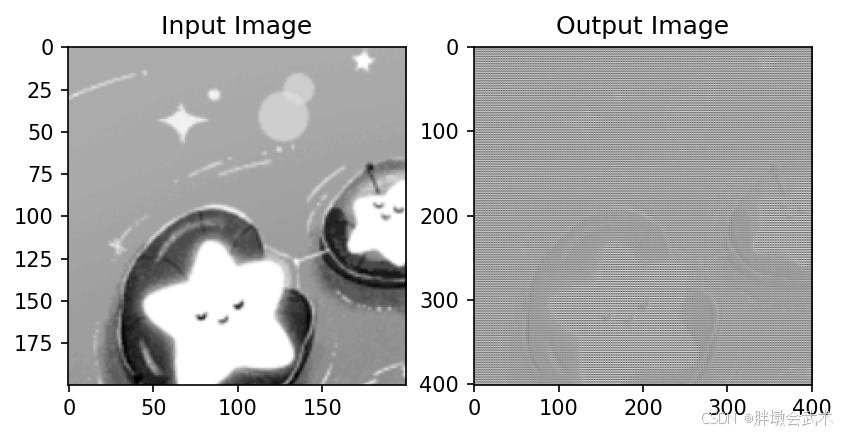
plt.subplot(1, 2, 1), plt.imshow(input_image[0, 0].detach().numpy(), cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Input Image')
plt.subplot(1, 2, 2), plt.imshow(output_image[0, 0].detach().numpy(), cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Output Image')
plt.show()
"""####################################################################################
函数作用:二维转置卷积操作。将低维特征图上采样,生成高维特征图。
函数说明:
class torch.nn.ConvTranspose2d(
in_channels: int,
out_channels: int,
kernel_size: Union[int, tuple[int, int]],
stride: Union[int, tuple[int, int]] = 1,
padding: Union[int, tuple[int, int]] = 0,
output_padding: Union[int, tuple[int, int]] = 0,
groups: int = 1,
bias: bool = True,
dilation: Union[int, tuple[int, int]] = 1,
padding_mode: str = 'zeros',
device: Any = None,
dtype: Any = None
) -> None
输入参数:
in_channels: 输入张量的通道数。例如,输入图像是 RGB 图像,则通道数为 3;如果输入是灰度图,则为 1。
out_channels: 输出张量的通道数,即卷积操作后的输出深度。通常根据需要的特征数来设置。
kernel_size: 卷积核的大小。可以是一个整数(表示高度和宽度相同的卷积核),也可以是一个元组,指定高和宽的不同大小。例如 (3, 3) 或 3。
stride: 步幅,用于控制上采样的倍数。步幅越大,输出的尺寸会越大。可以是一个整数或一个元组 (height, width),分别控制高度和宽度方向的步幅。
padding: 输入的填充大小。可以是一个整数或一个元组 (height, width)。填充是为了保证卷积核能够覆盖图像的边界区域,避免丢失图像边缘的信息。
output_padding: 输出填充,用于调节输出尺寸的参数。通常在应用转置卷积时,可以使用 output_padding 来确保输出尺寸与期望的尺寸匹配。
groups: 分组卷积的分组数。用于深度可分离卷积等特定情况,通常保持为 1。分组卷积允许每个输入通道和输出通道分别进行卷积,从而减少参数数量。
bias: 是否使用偏置项。如果为 True,则每个输出通道会添加一个可学习的偏置。
dilation: 卷积核的膨胀大小,通常用于增加卷积的感受野。通过膨胀卷积核,可以增加卷积核元素之间的间距,从而扩展感受区域,增加对远距离像素的感知能力。
padding_mode: 填充模式,控制填充的方式。常见的填充方式包括:"zeros"(默认值)、"reflect"、"replicate" 和 "circular"。
device: 指定计算张量所使用的设备,如 'cpu' 或 'cuda'(GPU)。如果为 None,则默认使用当前默认设备。
dtype: 指定张量的数据类型,如 torch.float32 或 torch.float64。如果为 None,则默认使用当前默认数据类型。
####################################################################################"""
(2)增强版本:网络深度 + 残差网络 + 正则化
为了增强反卷积的效果,你可以:
- 增加网络的深度,使用更复杂的网络结构。
- 加入正则化项,如 TV 正则化、Wiener 滤波,避免噪声放大。
- 采用批量归一化和残差网络,提高网络的稳定性和效果。
- 合理设置卷积核和步幅,确保特征不丢失且计算效率合理。
import torch
import torch.nn as nn
import torch.nn.functional as F
from skimage.restoration import denoise_tv_chambolle
import matplotlib.pyplot as plt
import numpy as np
import cv2
def set_seed(seed=0):
"""设置随机种子,确保可复现"""
torch.manual_seed(seed) # 设置PyTorch在CPU上的随机种子,确保所有随机操作(如权重初始化、数据加载等)可复现
# 设置CUDA的随机种子(用于GPU计算)
torch.cuda.manual_seed(seed) # 为当前设备设置种子
torch.cuda.manual_seed_all(seed) # 为所有GPU设备设置种子(如果使用多个GPU)
import random
random.seed(seed) # 设置Python标准库中的random模块的随机种子
import numpy as np
np.random.seed(seed) # 设置NumPy的随机数生成器种子
torch.backends.cudnn.deterministic = True # 让PyTorch的卷积操作变得确定性(即每次运行时结果相同)
torch.backends.cudnn.benchmark = False # 禁用CuDNN的自动优化,CuDNN会根据输入数据的形状和其他条件选择最优的计算算法(这通常会提高性能)。
# TV 正则化
def tv_regularization(image, weight=0.1):
"""应用 TV 正则化来去除噪声并保留边缘细节"""
return denoise_tv_chambolle(image, weight=weight)
# 残差块
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
self.relu = nn.ReLU()
def forward(self, x):
residual = x
x = self.relu(self.conv1(x))
x = self.conv2(x)
x += residual # 加入残差
return self.relu(x)
# 增强生成网络
class EnhancedGenerator(nn.Module):
def __init__(self, in_channels=3, out_channels=3):
super(EnhancedGenerator, self).__init__()
# 卷积层
self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1)
# 残差块
self.resblock1 = ResidualBlock(256)
self.resblock2 = ResidualBlock(256)
# 转置卷积层(上采样)
self.deconv1 = nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1)
self.deconv2 = nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1)
self.deconv3 = nn.ConvTranspose2d(64, out_channels, kernel_size=4, stride=2, padding=1)
# 批量归一化
self.bn1 = nn.BatchNorm2d(64)
self.bn2 = nn.BatchNorm2d(128)
self.bn3 = nn.BatchNorm2d(256)
def forward(self, x):
# 卷积过程
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
# 残差块
x = self.resblock1(x)
x = self.resblock2(x)
# 转置卷积过程
x = F.relu(self.deconv1(x))
x = F.relu(self.deconv2(x))
x = self.deconv3(x)
# 应用 TV 正则化
x = tv_regularization(x.squeeze().cpu().detach().numpy(), weight=0.1)
x = torch.tensor(x, dtype=torch.float32).unsqueeze(0).unsqueeze(0) # 转换为 Tensor
return x
def load_image(image_path):
"""加载并预处理图像(灰度或彩色)"""
img = cv2.imread(image_path) # 读取图像
print(f"Loaded image shape: {img.shape}") # Loaded image shape: (245, 612, 3)
img = img[0:200, 0:200] # 截取图像区域
if img.shape[2] == 3:
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图
# img = cv2.resize(img, (200, 200)) # 调整图像大小为 200x200
# img = np.transpose(img, (2, 0, 1)) # 将通道维度放在第一个维度
img = np.expand_dims(img, axis=0) # 添加批次维度
img = np.expand_dims(img, axis=0) # 添加通道维度(如果是灰度图)
img = torch.tensor(img, dtype=torch.float32) / 255.0 # 转换为 tensor 并归一化至 [0, 1]
return img
if __name__ == '__main__':
set_seed(5) # 设置固定种子
"""
由于卷积层的权重是随机初始化的,因此每次训练开始时,权重会有所不同。这种随机性会影响到模型的训练结果。
在默认情况下,PyTorch 会自动使用一些初始化方法来为转置卷积层的权重赋予随机值(权重+偏置),具体取决于卷积核的类型。
"""
# 加载图像
input_image = load_image('image.jpg')
print("Input size: ", input_image.shape) # Input size: torch.Size([1, 3, 200, 200])
# 创建模型
model = EnhancedGenerator(in_channels=1, out_channels=1)
# 前向传播
output_image = model(input_image) * 255
print("Output size: ", output_image.shape) # Output size: torch.Size([1, 3, 1600, 1600])
# 显示结果
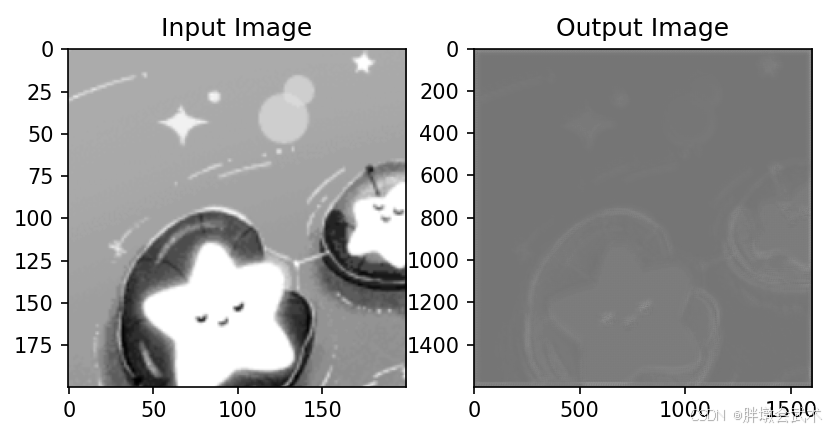
plt.subplot(1, 2, 1), plt.imshow(input_image[0, 0].detach().numpy(), cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Input Image')
plt.subplot(1, 2, 2), plt.imshow(output_image[0, 0].detach().numpy(), cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Output Image')
plt.show()
3. 分数步幅卷积(Fractionally Strided Convolution):torch.nn.ConvTranspose2d()
- 提出问题:在 PyTorch 中 ConvTranspose2d 只支持整数步幅(stride),而不支持浮动的步幅值,如 0.5。
- 解决方案:分数步幅卷积通过 " 将卷积核中的每个元素之间插入零 " 来模拟步幅小于 1 的效果。
在这种卷积过程中,会有零填充或者 " 空隙 " 出现在卷积操作中,使得输出尺寸变得更大。这个过程与普通的转置卷积(ConvTranspose2d)有些相似,因为它本质上是在做 上采样,但不使用传统的插值方法。

import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import cv2
import numpy as np
def set_seed(seed=0):
"""设置随机种子,确保可复现"""
torch.manual_seed(seed) # 设置PyTorch在CPU上的随机种子,确保所有随机操作(如权重初始化、数据加载等)可复现
# 设置CUDA的随机种子(用于GPU计算)
torch.cuda.manual_seed(seed) # 为当前设备设置种子
torch.cuda.manual_seed_all(seed) # 为所有GPU设备设置种子(如果使用多个GPU)
import random
random.seed(seed) # 设置Python标准库中的random模块的随机种子
import numpy as np
np.random.seed(seed) # 设置NumPy的随机数生成器种子
torch.backends.cudnn.deterministic = True # 让PyTorch的卷积操作变得确定性(即每次运行时结果相同)
torch.backends.cudnn.benchmark = False # 禁用CuDNN的自动优化,CuDNN会根据输入数据的形状和其他条件选择最优的计算算法(这通常会提高性能)。
def load_image(image_path):
"""加载并预处理图像(灰度或彩色)"""
img = cv2.imread(image_path) # 读取图像
img = img[0:200, 0:200]
if img.shape[2] == 3:
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图
# img = cv2.resize(img, (64, 64)) # 调整图像大小为 64x64
img = np.expand_dims(img, axis=0) # 添加批次维度
img = np.expand_dims(img, axis=0) # 添加通道维度(如果是灰度图)
img = torch.tensor(img, dtype=torch.float32) # 转换为 tensor
img /= 255.0 # 归一化至 [0, 1]
return img
class FractionalStrideConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=2):
super(FractionalStrideConv2d, self).__init__()
self.kernel_size = kernel_size
self.stride = stride
# 使用卷积操作,步幅为 1
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=kernel_size//2)
def forward(self, x):
batch_size, channels, height, width = x.size()
# 计算新的高度和宽度,确保 stride 是整数
new_height = height * self.stride
new_width = width * self.stride
# 插入零到高和宽维度
x = x.view(batch_size, channels, height, 1, width, 1) # 在每两个像素之间插入一个零
# 扩展张量以插入零,确保传入的是整数
x = x.expand(batch_size, channels, height, int(self.stride), width, int(self.stride)) # 扩展尺寸
x = x.contiguous().view(batch_size, channels, new_height, new_width) # 重塑
# 使用卷积
x = self.conv(x)
return x
if __name__ == '__main__':
set_seed(5) # 设置固定种子
"""
由于卷积层的权重是随机初始化的,因此每次训练开始时,权重会有所不同。这种随机性会影响到模型的训练结果。
在默认情况下,PyTorch 会自动使用一些初始化方法来为转置卷积层的权重赋予随机值(权重+偏置),具体取决于卷积核的类型。
"""
# (1)加载图像
input_image = load_image('image.jpg')
print("Input size: ", input_image.shape) # torch.Size([1, 1, 245, 612])
# input_image = torch.randn(1, 3, 64, 64) # 假设输入是 64x64 的 3 通道图像
model = FractionalStrideConv2d(in_channels=1, out_channels=64, kernel_size=3, stride=2)
output_image = model(input_image)
print(output_image.shape) # 输出图像的尺寸
model = FractionalStrideConv2d(in_channels=1, out_channels=64, kernel_size=3, stride=3)
output_image2 = model(input_image)
# 显示图像
plt.figure(figsize=(8, 8))
plt.subplot(1, 3, 1), plt.imshow(input_image[0, 0].detach().numpy(), cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Input Image')
plt.subplot(1, 3, 2), plt.imshow(output_image[0, 0].detach().numpy(),cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Output Image(stride=2)')
plt.subplot(1, 3, 3), plt.imshow(output_image2[0, 0].detach().numpy(),cmap='gray' if input_image.shape[1] == 1 else None), plt.title('Output Image(stride=3)')
plt.show()
plt.show()