磁盘存储下红黑树、B 树与 B + 树的原理、操作及对比
前置知识
磁盘
在计算机系统中,数据存储与检索效率深刻影响着整体性能。磁盘作为大容量数据的主要载体,其独特的 I/O 特性与树状数据结构的结合,催生出 B 树与 B + 树这两种经典方案。了解它们如何适配磁盘存储,是揭开数据库、文件系统高效运作奥秘的关键,让我们从磁盘底层机制讲起。

基本概念:
- 盘片与主轴:多个盘片装在主轴上,主轴带动盘片高速转(如 5400 转 / 分、7200 转 / 分 ),为数据读写提供运动基础。
- 磁道:盘片表面同心圆是磁道,存数据,磁性单元表示 0 和 1 。不同盘片同半径磁道构成柱面,存储分配时用它减少寻道时间。
- 扇区:磁道分弧段即扇区,是存储最小单位,通常 512 字节或 4KB ,读写以扇区为单元。
- 磁头:负责读写,悬浮盘片表面不接触,盘转时在磁道间移动寻道,定位扇区,检测或改变磁性单元状态读写数据,寻道耗时影响读写速度。
工作流程
- 寻道:当计算机发出读取或写入数据的指令时,磁头首先要移动到目标磁道,这个过程称为寻道。寻道时间取决于磁头的移动速度和目标磁道的位置,是影响磁盘随机读写性能的关键因素。
- 旋转定位:磁头到达目标磁道后,需要等待目标扇区旋转到磁头下方,这一过程需要的时间取决于盘片的转速。
- 数据传输:当目标扇区旋转到磁头下方时,磁头就可以进行数据的读取或写入操作了。数据传输的速度与盘片的转速以及磁道的存储密度等因素有关。
内存
内存(Memory)也叫内存储器,是计算机中用于临时存储数据和程序指令的硬件组件,CPU 可直接访问
作用
- 存储运行数据:存储计算机当前正在运行的操作系统、应用程序以及正在处理的数据。比如打开办公软件编辑文档时,软件程序和正在编辑的文档数据会暂存于内存。
- 提升数据访问速度:相比硬盘等外部存储设备,内存访问速度极快。CPU 能直接快速读取和写入内存中的数据,无需像访问硬盘那样经过复杂机械操作,从而加快程序运行速度。
- 支持多任务处理:计算机同时运行多个程序时,内存为每个程序分配空间,操作系统负责管理,确保程序间互不冲突。
特性 - 易失性:断电后内存中数据会立即丢失,所以仅用于临时存储。
- 随机访问:CPU 可随机快速访问内存中任一位置的数据。
数据读写
1. 读数据:先 “翻缓存”,再 “查仓库”
计算机内存中设有多级缓存(如页缓存、文件系统缓存),像一个 “数据中转站”。程序请求数据时:
先检查缓存是否已存储目标数据(称为 “缓存命中”),若命中,直接从缓存读取,速度可达纳秒级。
若缓存未命中,则触发磁盘 I/O:磁头寻道定位扇区,将数据从磁盘读入内存缓存,再返回给程序。这一过程因磁盘机械动作耗时毫秒级,是性能瓶颈。
示例:反复读取同一文件的内容,首次需磁盘读取并填充缓存,后续访问直接从缓存获取,大幅提升速度。
2. 写数据:“暂存草稿”,批量提交
程序产生新数据或修改数据时:
先将数据写入内存缓冲区(如文件系统的写缓存),相当于暂存 “草稿”,避免频繁磁盘写入。
满足特定条件时才批量写入磁盘:
时间触发:缓存数据积累到一定时间(如 Linux 默认 30 秒)。
容量触发:缓存区填满(如达到磁盘块大小的整数倍)。
主动触发:程序调用fsync等函数强制立即写入。
优势:减少磁头寻道次数,将零散写入合并为顺序写入,提升磁盘利用率。但断电可能丢失缓存未提交的数据,需依赖日志等机制保障可靠性。
b树和b+树
为什么要b树
红黑树和 B 树都是用来存数据的树形结构,不过 B 树的出现是为了解决红黑树在一些情况下的不足,特别是在和磁盘打交道的时候。下面用比较通俗的方式来说说为什么需要 B 树:
- 从磁盘读取速度来看(b树的层数少)
- 红黑树:红黑树就像一个有很多层的架子,每个格子里只能放一个东西(数据),找东西的时候得一层一层、一个格子一个格子地找。因为磁盘读数据就像从这个架子上拿东西,每次拿一个格子里的东西都要花不少时间,要是找的东西多,就得频繁地拿,速度就慢了。
- B 树:B 树像是一个每层有很多大抽屉的柜子,每个抽屉能放好多个东西。这样一来,柜子的层数就比红黑树的架子少很多。找东西的时候,一次能从一个抽屉里拿到好多东西,不用像在红黑树里那样频繁地去拿,所以能节省很多时间,也就提高了数据访问的效率。
- 从空间利用角度来说(多叉树)
- 红黑树:红黑树的每个格子小,而磁盘存数据是按一块一块来的,就好像用大盒子装小格子,盒子里有很多空间浪费了。
- B 树:B 树的抽屉大,能把盒子空间填满,这样就不会浪费磁盘空间,能更充分地利用磁盘。
- 从查找特定范围数据来看
- 红黑树:比如要找一群在某个范围内的东西,在红黑树里就得从最上面开始,一个一个地看每个格子里的东西是不是在这个范围内,要找很久。
- B 树:B 树里的东西是按顺序放在抽屉里的,要找特定范围的东西时,能很快知道哪些抽屉可能有,然后再去这些抽屉里找,不用把所有抽屉都看一遍,所以找起来更快。
b树的定义

一颗m阶b树的性质
- 节点的子树数量范围:每个非叶子节点至少有 ⌈ m / 2 ⌉ \lceil m/2 \rceil ⌈m/2⌉ 棵子树,奇数+1
- 节点关键字数量范围:非叶子节点中关键字的数量 n 满足 ⌈ m / 2 ⌉ − 1 ≤ n ≤ m − 1 \lceil m/2 \rceil - 1 \leq n \leq m - 1 ⌈m/2⌉−1≤n≤m−1。
- 叶子节点的位置:所有叶子节点都在同一层,叶子节点不包含任何关键字信息,可视为外部节点或查找失败的节点。
- 节点关键字与子树的关系:节点中的关键字按从小到大顺序排列,n 个关键字分别对应着 ( n + 1 ) (n + 1) (n+1) 棵子树,且子树中的关键字范围遵循特定规则。例如,对于节点中的第 i 个关键字 K i K_i Ki,其左子树中的所有关键字都小于 K i K_i Ki,右子树中的所有关键字都大于 K i K_i Ki。
- 根节点的特殊情况:根节点至少有两棵子树,除非它是叶子节点。若根节点不是叶子节点,其关键字数量至少为 1。
- 树的平衡性:B 树是一种平衡树,即树中任意节点的左右子树高度差不超过 1,保证了树的高度相对较低,从而提高了数据查找、插入和删除的效率。数据存储与磁盘块的适配性:
对比上图 讲一下性质
- 一个概念:你得脱离二叉树的概念,二叉树是一个节点一个key-val值,而b树是一个节点多个key值,比如说vwxyz是一个节点里面的值。
- 图中根节点 I 有 2 棵子树,满足根节点至少 2 棵子树的要求。假设这是 5 阶 B 树m = 5,非叶子节点 CF 有 3 棵子树,LORU 有 5 棵子树 ,对于 5 阶 B 树,,它们子树数量在 3 - 5 范围内,符合性质。
- 节点 CF 中,C < F ,其左子树 AB 中关键字小于 C ,中间子树 DE 中关键字介于 C 和 F 之间,右子树 GH 中关键字大于 F ;节点 LORU 同理,关键字有序排列,子树关键字范围符合规则 。一般都是中间隔开-中间的线!!!
代码实现:
#define DEGREE 3
typedef int KEY_VALUE;
typedef struct _btree_node {
KEY_VALUE *keys;
struct _btree_node **childrens;
int num;
int leaf;
} btree_node;
typedef struct _btree {
btree_node *root;
int t;
} btree;
btree_node *btree_create_node(int t, int leaf) {
btree_node *node = (btree_node*)calloc(1, sizeof(btree_node));
if (node == NULL) assert(0);
node->leaf = leaf;
node->keys = (KEY_VALUE*)calloc(1, (2*t-1)*sizeof(KEY_VALUE));
node->childrens = (btree_node**)calloc(1, (2*t) * sizeof(btree_node*));
node->num = 0;
return node;
}
#define DEGREE 3:定义了 B 树的最小度数为 3,最小度数决定了 B 树节点的键值数量和子节点数量的范围。
typedef int KEY_VALUE:将int类型重命名为KEY_VALUE,便于后续修改键值的数据类型。
btree_node结构体:代表 B 树的节点,包含以下成员:
KEY_VALUE *keys:指向存储键值的数组。
struct _btree_node **childrens:指向存储子节点指针的数组。
int num:记录当前节点中键值的数量。
int leaf:表示该节点是否为叶子节点,1代表是叶子节点,0代表不是
btree_node *root:指向 B 树的根节点。
int t:B 树的最小度数
插入原理
B 树的插入操作主要是要保证插入元素后,B 树依然满足其自身的性质,即每个节点的键值数量在[t - 1, 2t - 1]范围内(根节点除外),并且所有叶子节点在同一层。插入操作的核心步骤如下:
- 查找插入位置:从根节点开始,根据键值的大小,沿着合适的子节点路径向下查找,直到找到对应的叶子节点,因为新的键值总是插入到叶子节点中。
- 插入键值:
-
节点未满:如果找到的叶子节点中键值数量小于2t - 1,直接将新的键值插入到该节点的合适位置(按键值大小排序),插入操作完成。

-
节点已满:如果该叶子节点已经有2t - 1个键值,无法直接插入新键值,此时需要对该节点进行分裂操作。
- 分裂节点:将节点的中间键值(第t个键值)提升到父节点中,把该节点以中间键值为界,分为左右两个节点,每个节点包含t - 1个键值。然后将新键值插入到合适的子节点中。


- 递归处理:如果分裂导致父节点也满了,就需要对父节点继续进行分裂操作,以此类推,直到找到一个未满的节点或者到达根节点。如果根节点也需要分裂,就会创建一个新的根节点,B 树的高度会增加。
- 分裂节点:将节点的中间键值(第t个键值)提升到父节点中,把该节点以中间键值为界,分为左右两个节点,每个节点包含t - 1个键值。然后将新键值插入到合适的子节点中。
-
删除原理
B 树的删除操作相对复杂,因为要确保删除键值后,B 树仍然满足其性质。删除操作的主要步骤如下:
- 查找要删除的键值:从根节点开始,根据键值的大小,沿着合适的子节点路径向下查找,找到要删除的键值所在的节点。
- 删除键值:
- 在叶子节点中删除:
- 节点键值数量大于t - 1:直接从该叶子节点中删除键值,删除操作完成。
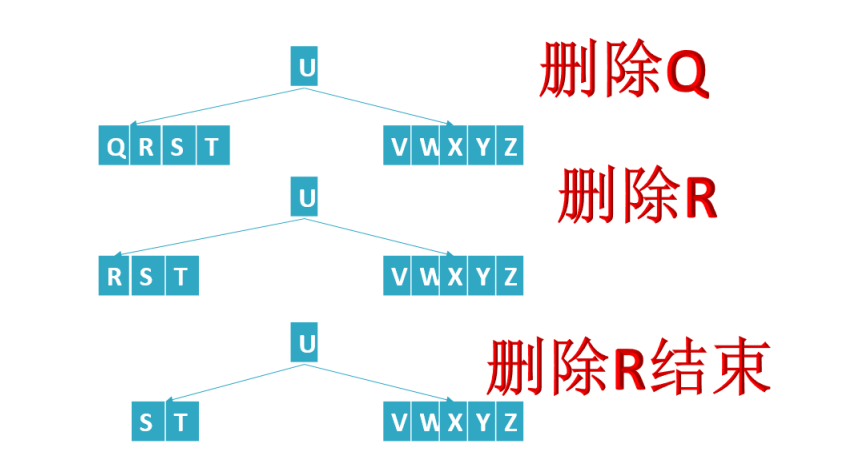
- 节点键值数量等于t - 1:如果直接删除会导致该节点的键值数量小于t - 1,此时需要从兄弟节点借键值或者与兄弟节点合并。
- 借键值:如果兄弟节点的键值数量大于t - 1,可以从兄弟节点借一个键值过来,同时调整父节点的键值。

- 合并节点:如果兄弟节点的键值数量也等于t - 1,则将该节点与兄弟节点合并,同时从父节点中删除一个键值。如果父节点的键值数量因此小于t - 1,需要对父节点继续进行借键值或合并操作,以此类推。

- 借键值:如果兄弟节点的键值数量大于t - 1,可以从兄弟节点借一个键值过来,同时调整父节点的键值。
- 节点键值数量大于t - 1:直接从该叶子节点中删除键值,删除操作完成。
- 在叶子节点中删除:
查找范围原理
查找步骤
- 定位起始位置:从 B 树的根节点开始,根据区间的起始值,沿着合适的子节点路径向下查找,直到找到一个可能包含起始值的叶子节点。在查找过程中,对于每个节点,比较起始值与该节点中的键值,选择合适的子节点继续查找。
- 遍历节点并收集键值:
- 从找到的叶子节点开始,按顺序检查该节点中的键值。如果键值落在指定的区间内,则将其收集起来。
- 如果该节点中的所有键值都检查完了,且还有后续的叶子节点,则移动到下一个叶子节点继续检查。在 B 树中,叶子节点通常是通过指针依次相连的,这样可以方便地进行顺序遍历。
- 终止条件:当遇到一个键值大于区间的结束值时,停止遍历,查找过程结束
b+树
其实只需对照b树来就行了
-
数据存储结构
B 树:键值和数据都存于每个节点。也就是说,每个节点既存有键值,也存有对应的数据记录或者指向数据记录的指针。这意味着在 B 树里,无论查找成功与否,可能在任何节点结束查找过程。
B + 树:只有叶子节点存放数据,非叶子节点仅用于索引。所有数据都按顺序存于叶子节点,叶子节点之间通过指针相连,形成一个有序链表,而非叶子节点仅包含键值和指向子节点的指针。 -
查询方式
B 树:可以在任何节点找到所需数据,一旦找到匹配的键值,查找操作便结束。这表明查找过程可能在树的任意层次结束。
B + 树:所有查询都必须到达叶子节点才能获取数据。这是因为只有叶子节点存有数据,非叶子节点仅用于引导查找方向。另外,借助叶子节点间的指针,B + 树能够更高效地进行范围查询。 -
插入删除操作
B 树:插入和删除操作可能会导致节点的分裂和合并,而且可能需要在多个层次进行调整,以保证树的平衡性。这些操作相对复杂,因为它们可能影响到多个节点的键值和子节点。
B + 树:插入和删除操作主要在叶子节点进行。当叶子节点满了或者不足时,仅需对叶子节点进行分裂或合并操作,非叶子节点的调整相对较少。这使得 B + 树的插入和删除操作更为简单和高效