阿里发布实时数字人项目OmniTalker,实时驱动技术再突破~
简介
OmniTalker 是一个由 阿里巴巴集团 Tongyi Lab(通义实验室) 开发的研究项目,专注于实时文本驱动的说话头像生成技术。该项目旨在通过文本输入生成同步的语音和视频内容,同时保留参考视频中的音视频风格。以下是关于 OmniTalker 项目背景的详细介绍,基于公开信息和其学术研究导向:
发起背景
-
时间:OmniTalker 的研究成果于 2025 年 4 月在 arXiv 上发布(论文编号 arXiv:2504.02433),由 Zhongjian Wang(王中建)、Peng Zhang(张鹏)、Jinwei Qi(齐金伟)等人共同撰写。
-
团队:项目由阿里巴巴集团的通义实验室主导,这是一个专注于 AI 技术创新的内部研究部门,涉及多模态生成、语音合成和视觉计算等领域。
-
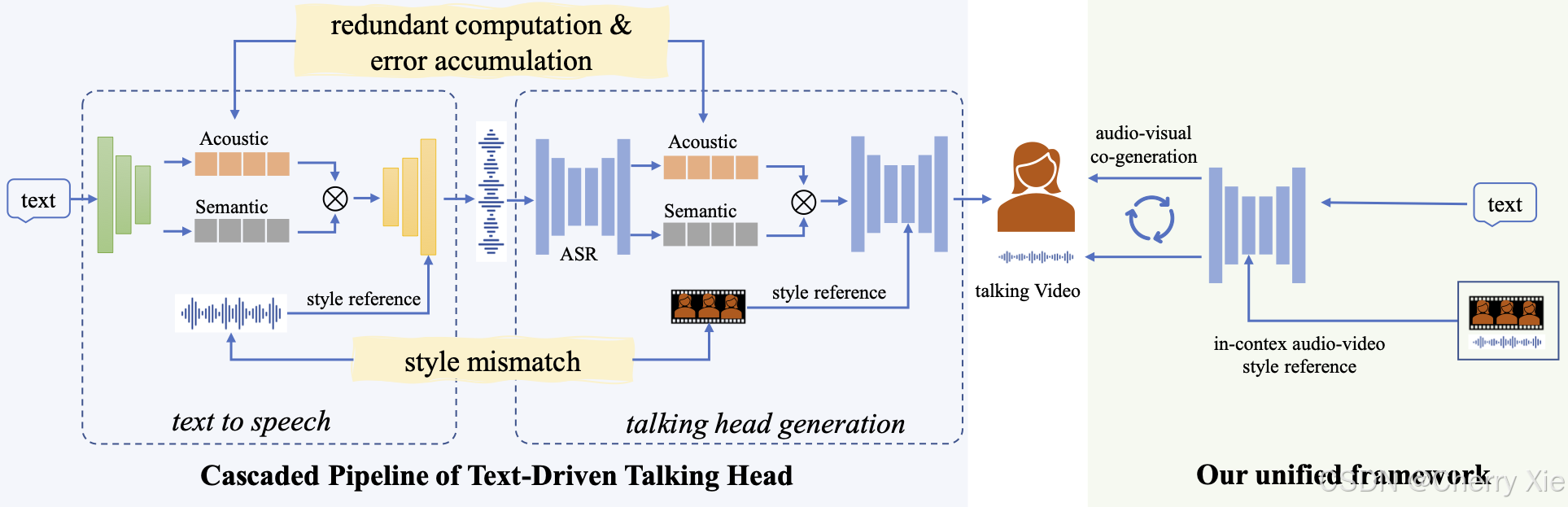
动机:随着大语言模型(LLM)和生成式 AI 的发展,人机交互从纯文本向多模态(语音+视频)演进的需求日益增加。传统的文本驱动说话头像生成依赖级联管道(TTS + 音频驱动视频),存在延迟高、音视频不同步、风格不一致等问题。OmniTalker 旨在解决这些痛点,推动更自然、实时的交互体验。
技术背景
-
研究现状:在 OmniTalker 之前,说话头像生成(Talking Head Generation, THG)主要依赖音频驱动方法(如 SadTalker、Wav2Lip),从文本到视频的端到端生成研究较少。现有方法通常将文本转语音(TTS)和音频驱动视频生成分开,导致系统复杂性和风格失配。
-
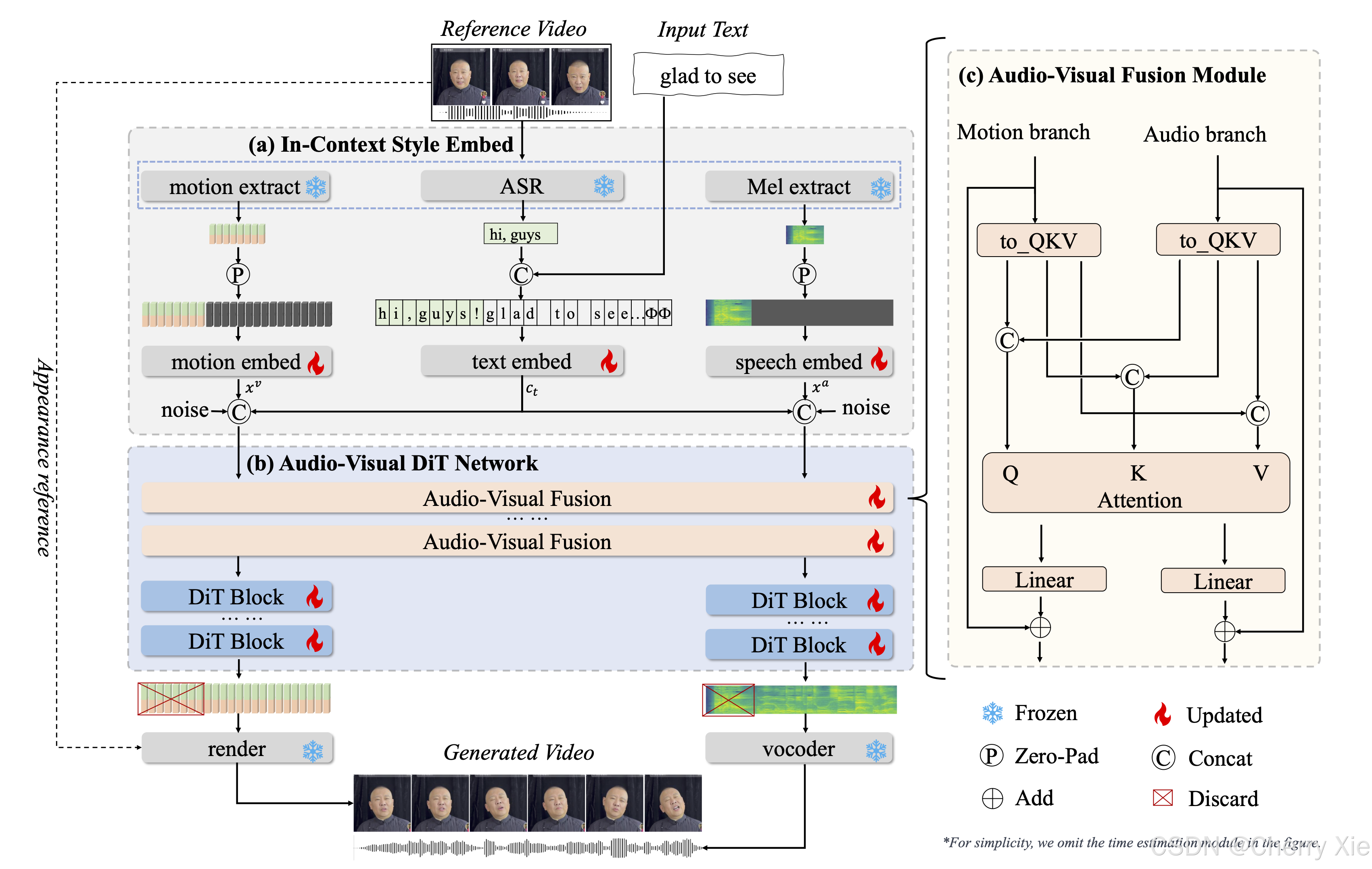
创新驱动:OmniTalker 提出了一个统一的端到端框架,利用多模态扩散变换器(Diffusion Transformer)同时生成语音(mel-spectrograms)和视频(头部姿态和面部动态),并通过音视频融合模块实现同步性和风格一致性。这种方法在业界尚属首创,尤其是在零样本(zero-shot)场景下。
-
应用潜力:项目强调其实时性(25 FPS)和风格保留能力,适用于虚拟助手、视频聊天、数字人生成等场景,与阿里巴巴的 AI 生态(如通义千问)有潜在协同效应。
项目目标
- 核心愿景:将文本驱动的交互升级为多模态体验,解决传统方法的冗余计算、错误累积和风格不匹配问题。
技术突破:
-
统一建模:将语音和视频生成整合到一个模型中,避免级联管道的复杂性。
-
零样本学习:通过单一参考视频捕获语音和面部风格,无需额外训练或风格提取模块。
-
实时性:模型参数量仅 0.8B(8 亿),推理速度达 25 帧/秒,适合实时应用。
-
学术贡献:论文展示了 OmniTalker 在生成质量、风格保留和音视频同步性上的优越性,超越了现有方法。
数据与训练
数据集:OmniTalker 使用大规模多模态数据集(视频、音频、文本)从头训练,具体数据来源未公开,但论文提到自动化预处理系统支持数据扩展。
训练方法:采用多阶段训练策略,结合随机序列掩码技术,增强模型的上下文预测能力。
性能对比
TTS对比
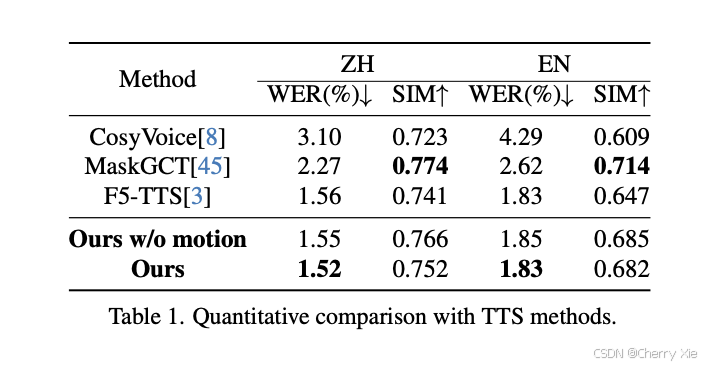
驱动模型之间的对比
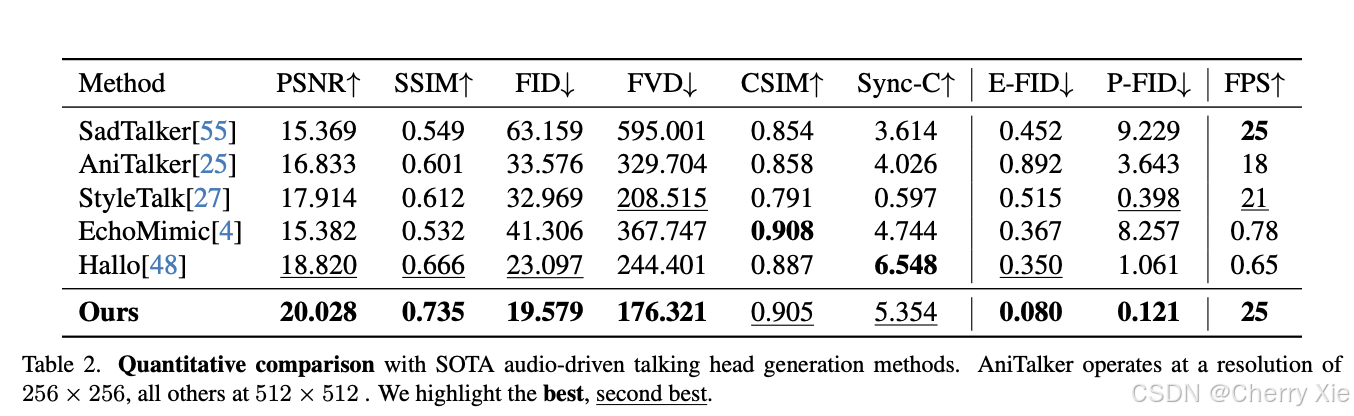
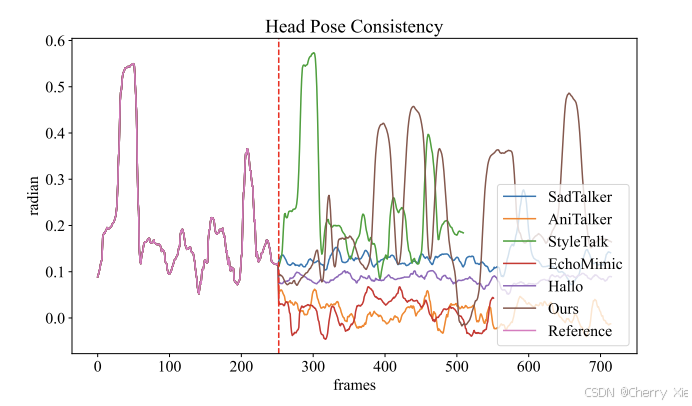
详细对比信息可见技术报告
看看效果
相关文献
github:https://github.com/HumanAIGC/omnitalker
官方地址:https://humanaigc.github.io/omnitalker/
技术报告:https://arxiv.org/pdf/2504.02433v1