vit中的位置编码,RoPE旋转位置编码,torch.nn.functional.embedding
位置编码和RoPE旋转位置编码,torch.nn.functional.embedding
文章目录
- 位置编码和RoPE旋转位置编码,torch.nn.functional.embedding
- 2. 位置编码和RoPE旋转位置编码
- 2.1 绝对位置编码
- 2.2 RoPE
- 2.3 图像视觉领域的绝对位置编码
- 2.4 vit rope2d
- 3. embedding函数 torch.nn.functional.embedding
2. 位置编码和RoPE旋转位置编码
2.1 绝对位置编码
https://blog.csdn.net/v_JULY_v/article/details/134085503
位置编码:
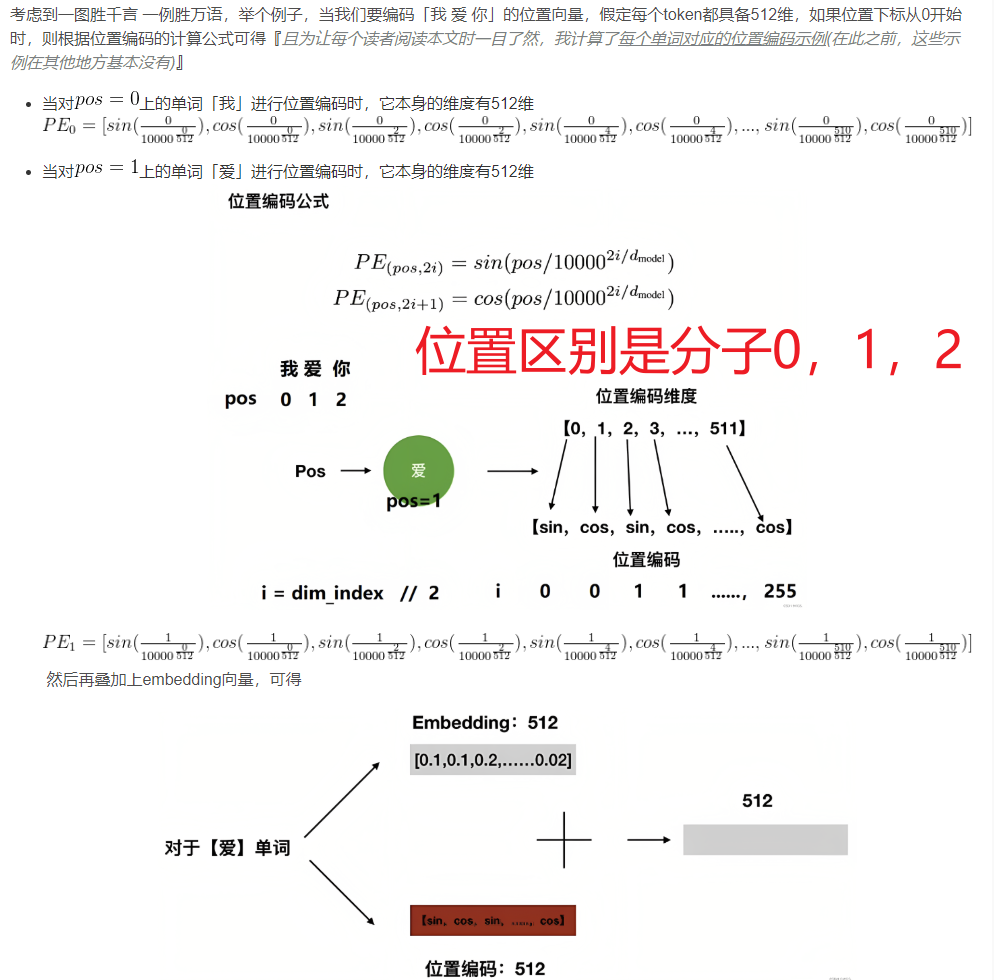
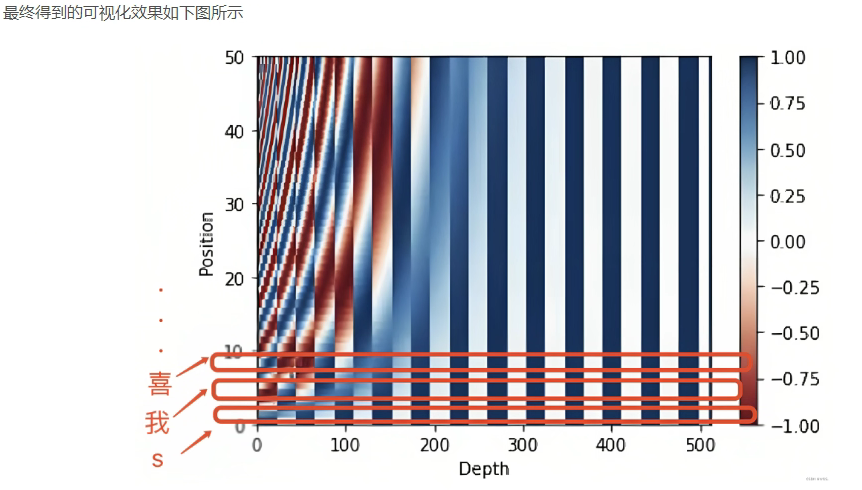
图中每一行是一个位置的编码,编码的长度等于特征的长度512
位置编码代码:就是每个位置得到一个向量,直接加在特征上。
为什么要这么编码呢?
下面代码输入输出shape都是: batch, seq_len, dim
"""位置编码的实现,调用父类nn.Module的构造函数"""
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout) # 初始化dropout层
# 计算位置编码并将其存储在pe张量中
pe = torch.zeros(max_len, d_model) # 创建一个max_len x d_model的全零张量
position = torch.arange(0, max_len).unsqueeze(1) # 生成0到max_len-1的整数序列,并添加一个维度
# 计算div_term,用于缩放不同位置的正弦和余弦函数
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
# 使用正弦和余弦函数生成位置编码,对于d_model的偶数索引,使用正弦函数;对于奇数索引,使用余弦函数。
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # 在第一个维度添加一个维度,以便进行批处理
self.register_buffer('pe', pe) # 将位置编码张量注册为缓冲区,以便在不同设备之间传输模型时保持其状态
# 定义前向传播函数
def forward(self, x):
# 将输入x与对应的位置编码相加
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
# 应用dropout层并返回结果
return self.dropout(x)
优势: 实现简单,可预先计算好,不用参与训练,速度快。
劣势: 没有外推性,即如果预训练最大长度为512的话,那么最多就只能处理长度为512的句子,再长就处理不了了。当然,也可以将超过512的位置向量随机初始化,然后继续微调。
2.2 RoPE
RoPE通过绝对位置编码的方式实现相对位置编码,综合了绝对位置编码和相对位置编码的优点。RoPE 代表了一种编码位置信息的新方法。传统方法中无论是绝对方法还是相对方法,都有其局限性。绝对位置编码为每个位置分配一个唯一的向量,虽然简单但不能很好地扩展并且无法有效捕获相对位置;相对位置编码关注标记之间的距离,增强模型对标记关系的理解,但使模型架构复杂化。
RoPE巧妙地结合了两者的优点。允许模型理解标记的绝对位置及其相对距离的方式对位置信息进行编码。这是通过旋转机制实现的,其中序列中的每个位置都由嵌入空间中的旋转表示。RoPE 的优雅之处在于其简单性和高效性,这使得模型能够更好地掌握语言语法和语义的细微差别。
主要就是对attention中的q, k向量注入了绝对位置信息,然后用更新的q,k向量做attention中的内积就会引入相对位置信息了。
https://blog.csdn.net/weixin_43646592/article/details/130924280 这篇博客里面的代码写的比较清晰
1)第m个位置的q,第n个位置的k经过某个变换f之后,两者相乘得到的attention包含相对位置信息
如公式2,得到的attention(g)可以分解出m-n

2)其实利用旋转是可以达到公式2的要求的。
因此:如下图,Rm是第m位置的编码矩阵

3)再度简化后:得到公式13
还记得 绝对位置的编码是什么吗?绝对位置编码就是对每个位置编码一个位置相关的向量 ,然后加到原来的特征上。也就是直接相加
这里变成了下图:相乘后相加

4)具体代码如下
RoPE中首先是绝对位置编码,然后对q,k进行编码
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
# %%
def sinusoidal_position_embedding(batch_size, nums_head, max_len, output_dim, device):
# (max_len, 1)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(-1)
# (output_dim//2)
ids = torch.arange(0, output_dim // 2, dtype=torch.float) # 即公式里的i, i的范围是 [0,d/2]
theta = torch.pow(10000, -2 * ids / output_dim)
# (max_len, output_dim//2)
embeddings = position * theta # 即公式里的:pos / (10000^(2i/d))
# (max_len, output_dim//2, 2)
embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1)
# (bs, head, max_len, output_dim//2, 2)
embeddings = embeddings.repeat((batch_size, nums_head, *([1] * len(embeddings.shape)))) # 在bs维度重复,其他维度都是1不重复
# (bs, head, max_len, output_dim)
# reshape后就是:偶数sin, 奇数cos了
embeddings = torch.reshape(embeddings, (batch_size, nums_head, max_len, output_dim))
embeddings = embeddings.to(device)
return embeddings
# %%
def RoPE(q, k):
# q,k: (bs, head, max_len, output_dim)
batch_size = q.shape[0]
nums_head = q.shape[1]
max_len = q.shape[2]
output_dim = q.shape[-1]
# (bs, head, max_len, output_dim)
pos_emb = sinusoidal_position_embedding(batch_size, nums_head, max_len, output_dim, q.device)
# cos_pos,sin_pos: (bs, head, max_len, output_dim)
# 看rope公式可知,相邻cos,sin之间是相同的,所以复制一遍。如(1,2,3)变成(1,1,2,2,3,3)
cos_pos = pos_emb[..., 1::2].repeat_interleave(2, dim=-1) # 将奇数列信息抽取出来也就是cos 拿出来并复制
sin_pos = pos_emb[..., ::2].repeat_interleave(2, dim=-1) # 将偶数列信息抽取出来也就是sin 拿出来并复制
# q,k: (bs, head, max_len, output_dim)
q2 = torch.stack([-q[..., 1::2], q[..., ::2]], dim=-1)
q2 = q2.reshape(q.shape) # reshape后就是正负交替了
# 更新qw, *对应位置相乘
q = q * cos_pos + q2 * sin_pos
k2 = torch.stack([-k[..., 1::2], k[..., ::2]], dim=-1)
k2 = k2.reshape(k.shape)
# 更新kw, *对应位置相乘
k = k * cos_pos + k2 * sin_pos
return q, k
https://cloud.tencent.com/developer/article/2403895 这篇博客中的RoPE给了另一个角度
2.3 图像视觉领域的绝对位置编码
2.1小节是 batch, seqlen, dim 用于自然语言处理
对于图像视觉领域对图像划分了patch,编码每个patch的位置
input:bchw
output:b2hw
来源:https://github.com/MCG-NJU/SGM-VFI/blob/main/model/position.py
import torch
import torch.nn as nn
import math
class PositionEmbeddingSine(nn.Module):
"""
This is a more standard version of the position embedding, very similar to the one
used by the Attention is all you need paper, generalized to work on images.
"""
def __init__(self, num_pos_feats=64, temperature=10000, normalize=True, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats
self.temperature = temperature
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, x):
# x = tensor_list.tensors # [B, C, H, W]
# mask = tensor_list.mask # [B, H, W], input with padding, valid as 0
b, c, h, w = x.size()
mask = torch.ones((b, h, w), device=x.device) # [B, H, W]
y_embed = mask.cumsum(1, dtype=torch.float32)
x_embed = mask.cumsum(2, dtype=torch.float32)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None] / dim_t
pos_y = y_embed[:, :, :, None] / dim_t
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos
2.4 vit rope2d
图像领域相对位置编码
from torch import Tensor
from typing import Optional, List
import torch
import torch.nn as nn
import torch.nn.functional as F
from itertools import repeat
import collections.abc
def _ntuple(n):
def parse(x):
if isinstance(x, collections.abc.Iterable) and not isinstance(x, str):
return x
return tuple(repeat(x, n))
return parse
to_2tuple = _ntuple(2)
import torch
class RoPE2D(torch.nn.Module):
"""
二维旋转位置编码(Rotary Position Embedding, RoPE)模块。
将二维坐标(y, x)的位置信息通过旋转操作编码到特征向量中。
"""
def __init__(self, freq=10000.0, F0=1.0):
"""
初始化函数。
Args:
freq (float): 基础频率参数,控制位置编码的频率范围。默认值10000.0(原论文设定)。
F0 (float): 未使用的参数(保留参数,可能为后续扩展保留)。
"""
super().__init__()
self.base = freq # 基础频率,用于计算逆频率
self.F0 = F0 # 保留参数
self.cache = {} # 缓存预计算的cos和sin值,避免重复计算
def get_cos_sin(self, D, seq_len, device, dtype):
"""
预计算并缓存给定参数对应的cos和sin值。
Args:
D (int): 每个方向(y/x)的特征维度的一半(总特征维度为2D)。
seq_len (int): 最大序列长度(位置索引的最大值+1)。
device (torch.device): 计算设备(如CPU/GPU)。
dtype (torch.dtype): 数据类型(如float32/float16)。
Returns:
tuple: (cos, sin) 张量,形状均为(seq_len, D*2)
"""
# 检查缓存是否存在
cache_key = (D, seq_len, device, dtype)
if cache_key not in self.cache:
# 计算逆频率(公式:inv_freq = 1.0 / (base^(2i/D)), i=0,...,D/2-1)
inv_freq = 1.0 / (self.base ** (torch.arange(0, D, 2).float().to(device) / D))
# 生成位置序列[0, 1, ..., seq_len-1]
t = torch.arange(seq_len, device=device, dtype=inv_freq.dtype)
# 计算频率矩阵(外积:t[:, None] * inv_freq[None, :])
freqs = torch.einsum("i,j->ij", t, inv_freq).to(dtype) # 形状:(seq_len, D/2)
# 拼接重复的频率以匹配特征维度(D*2)
freqs = torch.cat((freqs, freqs), dim=-1) # 形状:(seq_len, D)
# 计算cos和sin
cos = freqs.cos() # 形状:(seq_len, D)
sin = freqs.sin()
# 缓存结果
self.cache[cache_key] = (cos, sin)
return self.cache[cache_key]
@staticmethod
def rotate_half(x):
"""
将输入张量的后一半特征维度旋转并取反。
例如,x = [x1, x2],返回[-x2, x1]
"""
x1, x2 = x[..., : x.shape[-1] // 2], x[..., x.shape[-1] // 2:]
return torch.cat((-x2, x1), dim=-1)
def apply_rope1d(self, tokens, pos1d, cos, sin):
"""
应用一维旋转位置编码到特征张量。
Args:
tokens (torch.Tensor): 输入特征,形状为(batch_size, nheads, ntokens, D)
pos1d (torch.Tensor): 一维位置索引,形状为(batch_size, ntokens)
cos (torch.Tensor): 预计算的cos值,形状为(seq_len, D)
sin (torch.Tensor): 预计算的sin值,形状为(seq_len, D)
Returns:
torch.Tensor: 旋转后的特征,形状与输入相同
"""
# 根据位置索引提取对应的cos和sin值
cos_emb = torch.nn.functional.embedding(pos1d, cos) # 形状:(batch_size, ntokens, D)
sin_emb = torch.nn.functional.embedding(pos1d, sin)
# 调整维度以匹配输入特征形状 [batch_size, 1, ntokens, D]
cos_emb = cos_emb[:, None, :, :]
sin_emb = sin_emb[:, None, :, :]
# 应用旋转公式:rotated = tokens * cos + rotate_half(tokens) * sin
return (tokens * cos_emb) + (self.rotate_half(tokens) * sin_emb)
def forward(self, tokens, positions):
"""
前向传播,应用二维旋转位置编码。
Args:
tokens (torch.Tensor): 输入特征,形状为(batch_size, nheads, ntokens, dim)
positions (torch.Tensor): 二维位置坐标,形状为(batch_size, ntokens, 2)
Returns:
torch.Tensor: 编码后的特征,形状与输入相同
"""
assert tokens.size(3) % 2 == 0, "特征维度必须是偶数"
D = tokens.size(3) // 2 # 每个方向(y/x)的特征维度
# 确保位置张量形状正确
assert positions.ndim == 3 and positions.shape[-1] == 2
# 获取预计算的cos和sin(覆盖可能的最大位置索引)
max_pos = int(positions.max()) + 1
cos, sin = self.get_cos_sin(D, max_pos, tokens.device, tokens.dtype)
# 将特征拆分为y和x部分(各D维)
y, x = tokens.chunk(2, dim=-1) # 每部分形状:(batch_size, nheads, ntokens, D)
# 对y部分应用一维旋转(使用y坐标)
y = self.apply_rope1d(y, positions[:, :, 0], cos, sin)
# 对x部分应用一维旋转(使用x坐标)
x = self.apply_rope1d(x, positions[:, :, 1], cos, sin)
# 拼接结果并返回
return torch.cat((y, x), dim=-1)
# patch embedding
class PositionGetter(object):
""" return positions of patches """
def __init__(self):
self.cache_positions = {}
def __call__(self, b, h, w, device):
if not (h, w) in self.cache_positions:
x = torch.arange(w, device=device)
y = torch.arange(h, device=device)
self.cache_positions[h, w] = torch.cartesian_prod(y, x) # (h, w, 2)
pos = self.cache_positions[h, w].view(1, h * w, 2).expand(b, -1, 2).clone() # B,h*w,2
return pos
class PatchEmbed(nn.Module):
""" just adding _init_weights + position getter compared to timm.models.layers.patch_embed.PatchEmbed"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, norm_layer=None, flatten=True):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.flatten = flatten
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
self.position_getter = PositionGetter()
def forward(self, x):
B, C, H, W = x.shape
torch._assert(H == self.img_size[0], f"Input image height ({H}) doesn't match model ({self.img_size[0]}).")
torch._assert(W == self.img_size[1], f"Input image width ({W}) doesn't match model ({self.img_size[1]}).")
x = self.proj(x)
pos = self.position_getter(B, x.size(2), x.size(3), x.device)
if self.flatten:
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
x = self.norm(x)
return x, pos
def _init_weights(self):
w = self.proj.weight.data
torch.nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
def drop_path(x, drop_prob: float = 0., training: bool = False, scale_by_keep: bool = True):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = x.new_empty(shape).bernoulli_(keep_prob)
if keep_prob > 0.0 and scale_by_keep:
random_tensor.div_(keep_prob)
return x * random_tensor
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob: float = 0., scale_by_keep: bool = True):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
self.scale_by_keep = scale_by_keep
def forward(self, x):
return drop_path(x, self.drop_prob, self.training, self.scale_by_keep)
def extra_repr(self):
return f'drop_prob={round(self.drop_prob, 3):0.3f}'
class Mlp(nn.Module):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, bias=True, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
bias = to_2tuple(bias) # 一个数复制成2个数而已
drop_probs = to_2tuple(drop)
self.fc1 = nn.Linear(in_features, hidden_features, bias=bias[0])
self.act = act_layer()
self.drop1 = nn.Dropout(drop_probs[0])
self.fc2 = nn.Linear(hidden_features, out_features, bias=bias[1])
self.drop2 = nn.Dropout(drop_probs[1])
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class Attention(nn.Module):
def __init__(self, dim, rope=None, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.rope = rope
def forward(self, x, xpos):
B, N, C = x.shape # B, 14*14, 768
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).transpose(1,
3) # B, 8, 3, 14*14, 768//8
q, k, v = [qkv[:, :, i] for i in range(3)] # B, 8, 14*14, 768//8
# q,k,v = qkv.unbind(2) # make torchscript happy (cannot use tensor as tuple)
if self.rope is not None:
q = self.rope(q, xpos) # batch_size x nheads x ntokens x dim
k = self.rope(k, xpos)
attn = (q @ k.transpose(-2, -1)) * self.scale # B, head=8, 14*14, 14*14 head=8就当作8个并列的
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # B, 8, 14*14, 768//8 -->B, 14*14, 8, 768//8 ->BNC
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
"""
Block(enc_embed_dim, enc_num_heads, mlp_ratio, qkv_bias=True, norm_layer=norm_layer, rope=self.rope)
Block(768, 8, mlp_ratio, qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), rope=self.rope)
"""
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, rope=None):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(dim, rope=rope, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop,
proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
# B,196,768 and B,196,2 ->B,196,768
def forward(self, x, xpos):
x = x + self.drop_path(self.attn(self.norm1(x), xpos))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class VIT(nn.Module):
def __init__(self, embed_dim=512, patch_size=16, block_num=4):
super().__init__()
self.position_getter = PositionGetter()
self.rope = RoPE2D(freq=100)
self.block = Block(embed_dim, num_heads=8, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, rope=self.rope)
self.patch_size = patch_size
self.proj = nn.Linear(embed_dim, (3 + 0) * self.patch_size**2)
self.block_num = block_num
def forward(self, x):# b, 512, 16, 16
# assert self.patch_size[0] == x.size(2)
# assert self.patch_size[1] == x.size(3)
b, c, h, w = x.shape
pos = self.position_getter(x.size(0), h, w, x.device)
x = x.flatten(2).transpose(1, 2) # b,256,512
#print(x.shape)
for i in range(self.block_num):
x = self.block(x, pos) # b,256,512
feat = x.transpose(1, 2).view(b, c, h, w)
#print(x.shape)
# feat = self.proj(x) # 12, 256, 3 * 16 * 16
# feat = feat.transpose(-1, -2).view(x.size(0), -1, h, w)
# feat = F.pixel_shuffle(feat, self.patch_size) # B,3,H,W
return feat
if __name__ == "__main__":
# img_size = 256
# patch_size = 16
# embed_dim = 768
# in_chans = 3
# block_num = 4
# has_conf = 0
# B = 12
#
# patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim, norm_layer=None, flatten=True)
# rope = RoPE2D(freq=100)
# block = Block(dim=embed_dim, num_heads=8, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,
# drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, rope=rope)
#
#
# x = torch.rand([B, in_chans, img_size, img_size])
# x, pos = patch_embed(x)
# print(pos)
# print(x.shape, pos.shape)
# for i in range(block_num):
# x = block(x, pos)
# print(x.shape) # 12, 256, 768
#
# proj = nn.Linear(embed_dim, (3 + has_conf) * patch_size ** 2)
# feat = proj(x) # 12, 256, 3 * 16 * 16
# feat = feat.transpose(-1, -2).view(B, -1, img_size // patch_size, img_size // patch_size)
# feat = F.pixel_shuffle(feat, patch_size) # B,3,H,W
# feat = feat.permute(0, 2, 3, 1)
#
# print(feat.shape)
x = torch.rand([6, 512, 36, 24])
vit = VIT( embed_dim=512, patch_size=16, block_num=8)
y = vit(x)
print(y.shape)
3. embedding函数 torch.nn.functional.embedding
torch.nn.functional.embedding 是 PyTorch 中的一个函数,用于根据索引(indices)从预定义的嵌入矩阵(embedding matrix)中提取对应的行(向量)。它的行为类似于一个高效的“查表”操作。
函数定义
torch.nn.functional.embedding(
input, # 索引张量(包含要查找的索引值)
weight, # 嵌入矩阵(即要查的“表”)
...
)
核心作用
假设嵌入矩阵 weight 的形状为 (num_embeddings, embedding_dim),即:
共有 num_embeddings 个不同的嵌入向量
每个向量的维度是 embedding_dim
给定一个索引张量 input,函数会:
将 input 中的每个索引值视为要查找的行号。
从 weight 中提取对应行的向量。
最终返回一个形状为 (*input.shape, embedding_dim) 的张量。
示例
假设:
weight = torch.tensor([
[0.1, 0.2], # 索引0对应的向量
[0.3, 0.4], # 索引1对应的向量
[0.5, 0.6] # 索引2对应的向量
])
input = torch.tensor([0, 2, 1]) # 要查找的索引
调用 embedding(input, weight) 会返回:
[
[0.1, 0.2], # 索引0的向量
[0.5, 0.6], # 索引2的向量
[0.3, 0.4] # 索引1的向量
]