Prometheus采集容器故障排查
一 背景
在某一天,突然收到了大量关于采集任务状态的告警截图。当时第一反应是这些告警的服务,状态全部出现了异常,有可能是这些服务挂掉了。由于集团监控对于采集任务状态的等级定义是严重,一时间告警电话瞬间被打爆。第一反应是上去排查各个组件的状态,可是奇怪的事情是每个组件任务状态均是正常没有问题,那么原因是什么呢?

(最开始接受的告警短信)

(组件页面状态图)
二 k8s版本
K8s版本 v1.19.12
Prometheus 版本 prometheus-v2.19.2
三 故障现象
从接收到第一条组件采集任务状态的告警开始。就不断收到各个组件任务状态的告警短信。每天都要被不同的oncall值班人员通知一会,其实这些个组件并没有出现任何问题。每次告警的组件都不是重复的,有时是node节点的kubelet,有时是master节点的组件有可能是etcd,有可能是apiserver。但是实际这些组件并没有出任何问题运行状态与告警日志全部都是正常的。告警间隔有时几分钟一条,有时可能一下午一条。

(陆续收到不同的告警短信)
四 故障分析
由于告警短信是从二级通过prometheus-kafka推送到一级的告警监控。我们最开始的排查思路是这个prometheus-kafka是不是有什么问题,导致推送数据受到延迟阻碍了,导致一级监控没有在取样区间内采集到指标。导致了一级监控会发出采集状态的告警。可是通过排查prometheus-kafka容器并没有发现里面有异常的告警日志或者是延迟的告警日志。这样我们把排查思路放在了二级的监控上。直到从众多的告警短信中看到了一条关于prometheus的数据采集状态的告警,更加明确了将排查目标放在二级监控上。


(prometheus集群数据状态告警)
这时我们将排查思路转到了二级的监控上,我们先登录查看prometheus二级页面

此时可以看到很多Endpoint指标状态为down的error原因均是context deadline exceeded。还是因为超时。继续刷新页面可以发现每次刷新后都是会有不同的Endpoint也会出现这种context deadline exceeded。之前有这种down掉的也可能会up起来。
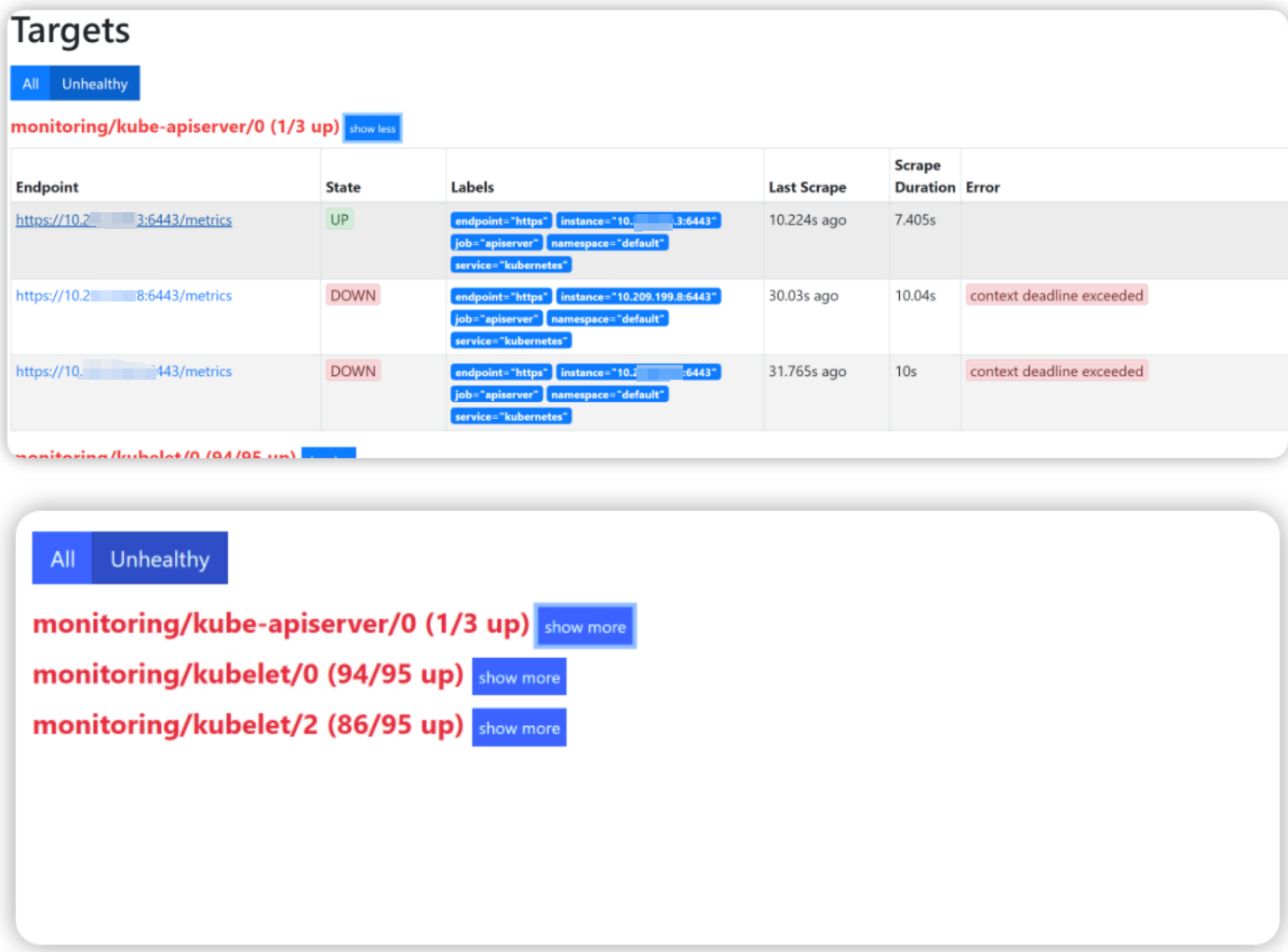

此时可以明确问题出现这种情况原因还是在于采集容器超时的原因。大体估计有可能是内存原因造成的超时,也有可能cpu使用率过高造成的超时,还有可能是网络原因造成的超时。
五 解决办法
登录上prometheus采集节点所在主机,大体先排查了一下内存与cpu的一个情况。都正常,排除掉是此原因引起的。后将主要的一个排查问题方向放到网络问题上,简单写了一条网络测试命令,从采集节点主机到目标采集主机的一条简单网络测试命令。

此时可以发现,延迟时间非常大。由于该节点托管在苏池pod2。第一时间找到了苏池值班人员进行一个网络情况的认定。可惜当天流量溯源设备出了问题,厂商一直没有处理好。我们只能自己写一个简单的流量监控脚本。取样是采集设备与被采集设备之间的一个网络状态。通过curl的方式去。
{ echo "--------------------------------------"; time curl -o /dev/null -s -w "%{http_code} " https://10.XXX.XXX.8:6443/metrics --header "Authorization: Bearer $TOKEN" --insecure; echo $(date); } 2>&1 | tee -a output.txt

发现超时状态还是很多的
由于该节点是一台虚拟机,最简单的一个解决办法就是将该prometheus采集容器迁移到别的主机上,看看是否还有告警。我们将采集容器迁移到另一台状态比较好的主机上,发现延迟很小,也不会有告警产生了。从页面上看所有组件监控页面也恢复正常。

六 总结和建议
通过这次故障,建议还是将prometheus采集容器部署在物理机上或者网络状态比较好的虚机上。这样可以避免网络延迟带来的一些列采集状态异常的故障,减少排查成本跟人力消耗。