20250408-报错:pre_state = state同更新现象
项目场景:
基于强化学习解决组合优化问题
问题描述
# POMO Rollout
state, reward, done = self.env.pre_step()
# next_state = state
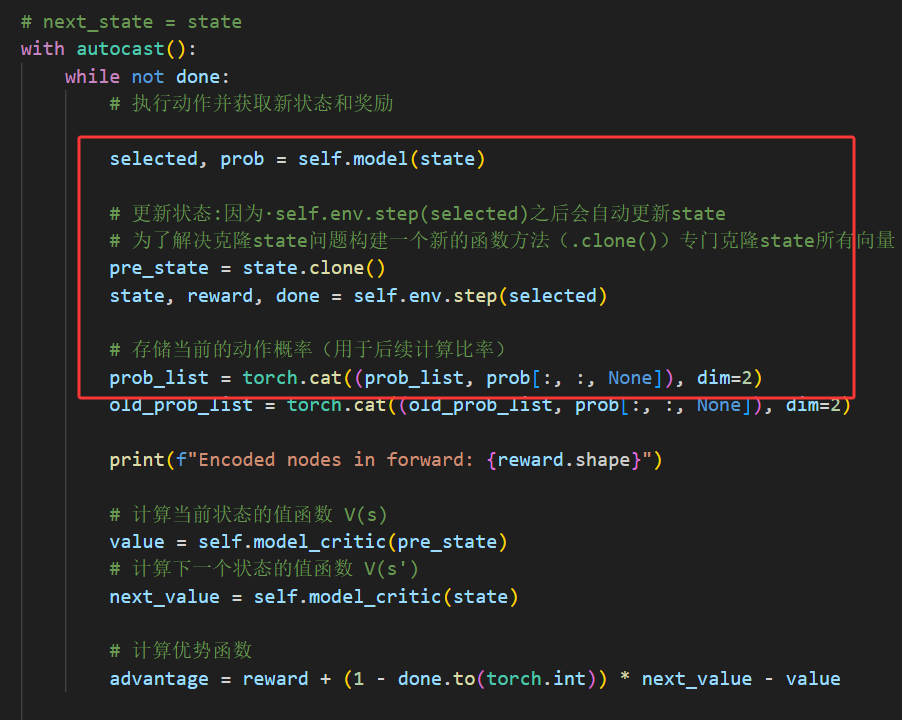
with autocast():
while not done:
# 执行动作并获取新状态和奖励
selected, prob = self.model(state)
# 更新状态:因为·self.env.step(selected)之后会自动更新state
# 为了解决克隆state问题构建一个新的函数方法(.clone())专门克隆state所有向量
pre_state = state
state, reward, done = self.env.step(selected)
# 存储当前的动作概率(用于后续计算比率)
prob_list = torch.cat((prob_list, prob[:, :, None]), dim=2)
old_prob_list = torch.cat((old_prob_list, prob[:, :, None]), dim=2)
print(f"Encoded nodes in forward: {reward.shape}")
# 计算当前状态的值函数 V(s)
value = self.model_critic(pre_state)
# 计算下一个状态的值函数 V(s')
next_value = self.model_critic(state)
# 计算优势函数
advantage = reward + (1 - done.to(torch.int)) * next_value - value
pre_state = state
出现与目标相反的现象:pre_state = state目的是保存state的前一步数据,因为state, reward, done = self.env.step(selected)会更新state的值。但随着state的更新pre_state也会更新。
原因分析:
state是类似全局变量的参数,可能pre_state与state指着同一个地址,这导致state更新pre_state也更新。
解决方案:
使用.clone()操作将他们分开到两个地址中。
但要注意的是state = Step_State()。其中 Step_State()为多向量数据。
@dataclass
class Step_State:
BATCH_IDX: torch.Tensor = None #表示批次的索引 # shape: (batch, pomo)
POMO_IDX: torch.Tensor = None #表示 POMO 算法中的多智能体索引 # shape: (batch, pomo)
selected_count: int = None #表示当前已经选中的节点数量 # shape: (batch, pomo)
load: torch.Tensor = None #表示当前负载状态 # shape: (batch, pomo)
current_node: torch.Tensor = None #表示当前正在访问的节点编号 # shape: (batch, pomo)
ninf_mask: torch.Tensor = None #表示负无穷掩码 # shape: (batch, pomo, problem+1)
这里构建一个函数cloneStep_State()所有向量。
@dataclass
class Step_State:
BATCH_IDX: torch.Tensor = None #表示批次的索引 # shape: (batch, pomo)
POMO_IDX: torch.Tensor = None #表示 POMO 算法中的多智能体索引 # shape: (batch, pomo)
selected_count: int = None #表示当前已经选中的节点数量 # shape: (batch, pomo)
load: torch.Tensor = None #表示当前负载状态 # shape: (batch, pomo)
current_node: torch.Tensor = None #表示当前正在访问的节点编号 # shape: (batch, pomo)
ninf_mask: torch.Tensor = None #表示负无穷掩码 # shape: (batch, pomo, problem+1)
def clone(self):
# 克隆每个张量属性
return Step_State(
BATCH_IDX=self.BATCH_IDX.clone() if self.BATCH_IDX is not None else None,
POMO_IDX=self.POMO_IDX.clone() if self.POMO_IDX is not None else None,
selected_count=self.selected_count, # 如果是整数,直接赋值即可
load=self.load.clone() if self.load is not None else None,
current_node=self.current_node.clone() if self.current_node is not None else None,
ninf_mask=self.ninf_mask.clone() if self.ninf_mask is not None else None
)