基于Resemblyzer 声纹识别门禁系统设计
一、整体结构与思路
这份程序的核心目的是:
用麦克风录音 ➜ 识别说话人是谁 ➜ 图形化展示 ➜ 语音播报反馈
它主要由 4 个部分组成:
-
全局配置和依赖加载
-
语音采集和声纹提取逻辑
-
图形界面与交互(PyQt5)
-
语音播报反馈系统
二、各部分代码作用详解
1. 导入库与初始化配置
import os, threading
import numpy as np
import pyttsx3
from sounddevice import rec, wait
from scipy.io.wavfile import write
from resemblyzer import VoiceEncoder, preprocess_wav
from PyQt5.QtWidgets import ...
用于导入:
-
文件操作(
os) -
多线程(
threading,防止语音播报卡界面) -
录音与保存(
sounddevice,scipy) -
声纹识别核心(
resemblyzer) -
图形界面构建(
PyQt5)
VOICE_DIR = "voices"
os.makedirs(VOICE_DIR, exist_ok=True)
encoder = VoiceEncoder()
-
设置语音文件夹
-
初始化声纹编码器(Resemblyzer)
2. 语音播报功能
def speak(text):
def run():
engine = pyttsx3.init()
engine.say(text)
engine.runAndWait()
threading.Thread(target=run, daemon=True).start()
-
使用
pyttsx3实现 TTS 语音播报 -
放在线程中执行,防止
engine.runAndWait()阻塞程序
3. 录音窗口与功能
(1)录音窗口提示类
class RecordingDialog(QDialog):-
弹出一个小对话框,提示用户“正在录音”
-
录音完自动关闭,提升交互体验
(2)录音函数
def record_voice(filepath, duration=5, fs=16000, parent=None):-
调用
sounddevice.rec()录音,采样率16000Hz(Resemblyzer推荐) -
保存为
wav文件 -
弹出提示窗口进行录音反馈
4. 用户管理函数
def list_users():
return [f[:-4] for f in os.listdir(VOICE_DIR) if f.endswith(".wav") and f != "test.wav"]
扫描文件夹,返回除 test.wav 外的所有用户(注册过的)
5. 主界面类 VoiceApp
(1)初始化界面与样式
screen = QDesktopWidget().screenGeometry()
win_width = screen.width() // 3
self.resize(win_width, ...)
-
界面自动适配屏幕,设置合适大小
-
设置按钮字体大小统一风格
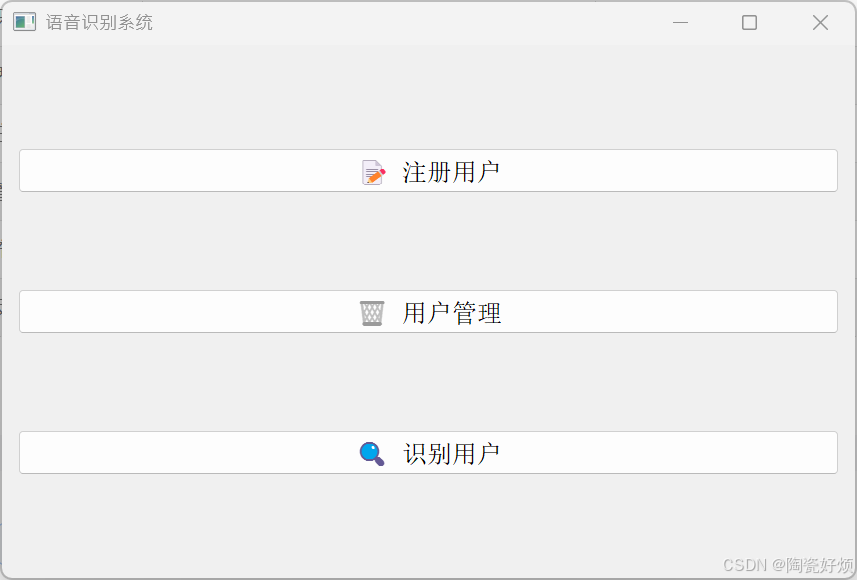
(2)注册用户
def register_user(self):
name, ok = QInputDialog.getText(...)
if ok and name:
filepath = ...
if os.path.exists(filepath): ...
record_voice(filepath, parent=self)
-
弹出输入框让用户输入用户名

-
检查是否重复
-
录音并保存为
{name}.wav
(3)用户管理(删除)
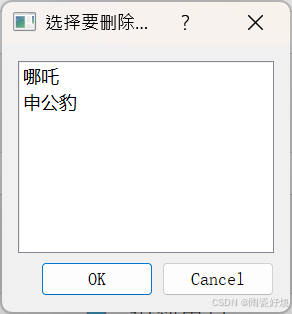
def manage_users(self):
users = list_users()
if not users: ...
...
selected_items = list_widget.selectedItems()
for item in selected_items:
os.remove(filepath)
-
弹出用户列表
-
选择后点击 OK 即可删除对应语音文件
(4)识别用户
def identify_user(self):
...
test_path = os.path.join(VOICE_DIR, "test.wav")
record_voice(test_path, ...)
-
录制测试语音
-
提取特征向量(
encoder.embed_utterance()) -
依次读取所有已注册用户的语音文件,提取向量,计算相似度:
sim = np.dot(embed, embed_test)
-
找到相似度最大的用户
-
如果相似度 > 0.8,就提示识别成功(播报+弹窗),否则视为非法
三、开发过程解析(思路演进)
| 阶段 | 功能 | 技术 |
|---|---|---|
| 1️⃣ 初始化项目 | 建立语音识别系统结构,准备声音文件夹 | os |
| 2️⃣ 实现录音功能 | 录音并保存语音为 .wav 文件 | sounddevice, scipy.io.wavfile |
| 3️⃣ 声纹识别模型加载 | 利用 Resemblyzer 提取说话人特征向量 | resemblyzer |
| 4️⃣ GUI 界面搭建 | 主界面+按钮布局+按钮功能绑定 | PyQt5 |
| 5️⃣ 用户注册功能 | 输入用户名 ➜ 录音 ➜ 存储 | QInputDialog |
| 6️⃣ 用户管理功能 | 显示用户列表 ➜ 可删除 | QListWidget, QDialog |
| 7️⃣ 识别流程 | 测试录音 ➜ 与已有用户匹配 ➜ 相似度判断 | 向量点积识别逻辑 |
| 8️⃣ 播报反馈 | 加入语音播报,提示识别结果 | pyttsx3 + 多线程避免阻塞 |