InternVideo2.5:Empowering Video MLLMs with Long and Rich Context Modeling
一、TL;DR
- InternVideo2.5通过LRC建模来提升MLLM的性能。
- 层次化token压缩和任务偏好优化(mask+时空 head)整合到一个框架中,并通过自适应层次化token压缩来开发紧凑的时空表征
- MVBench/Perception Test/EgoSchema/MLVU数据benchmark上提升明显
二、介绍
MLLM的问题点:
MLLM在基本视觉相关任务上的表现仍不如人类,这限制了其理解和推理能力。它们在识别、定位和回忆常见场景中的物体、场景和动作时表现不佳。
本文如何解决:
研究多模态上下文的长度和细粒度如何影响MLLM以视觉为中心的能力和性能,而不是专注于通过scaling law直接扩展MLLM。
取得了什么结果:
具体而言,本文的贡献在于:
-
首次全面研究了如何实现长且丰富的上下文(Long and Rich Context,LRC),以提升MLLM的记忆和专注能力。
-
通过将层次化token压缩(Hierarchical Token Compression,HiCo)和任务偏好优化(Task Preference Optimization,TPO)整合到一个框架中
-
-
InternVideo2.5能够显著提升现有MLLM在视频理解方面的表现,并赋予它们专家级的视觉感知能力。
-
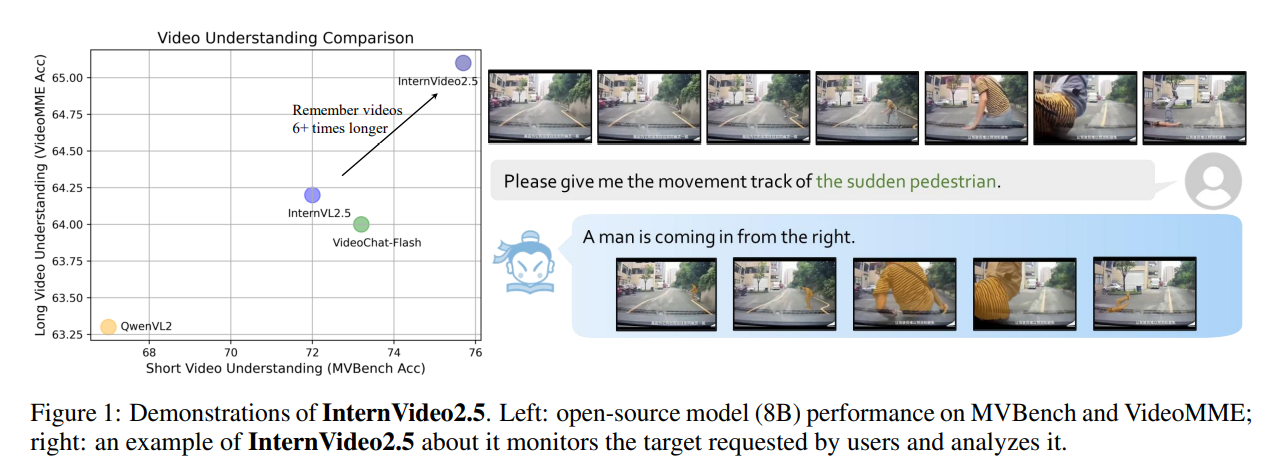
在多个短视频和长视频基准测试中取得了领先的性能。InternVideo2.5的视频记忆容量使其能够保留至少比原始版本长6倍的输入。
-
三、方法
InternVideo2.5通过增强MLLM的上下文长度和细粒度来获得长且准确的视频理解,采用了视频长度自适应的标记表示和任务偏好优化,如图2所示。整个模型通过三个阶段进行学习,利用了短视频、长视频以及经典视觉任务数据。整个方法详细描述如下。
说人话:在前面的clip encoder时使用Tome做token压缩,在浅层使用TDrop进行token prune做算力压缩,深层使用注意力机制提取关键token,然后增加了一个mask Head和时间理解的head用于理解上下文和视觉细节(任务偏好优化),最后面接生成出结果

3.1 视频长度自适应标记表示用于长多模态上下文
引入了一种实用的长度自适应token representation方法,能够高效地处理任意长度的视频序列。在动态帧采样之后,给定的流程实现了具有两个不同阶段的层次化标记压缩(HiCo):
- 视觉编码过程中的时空感知压缩
- 语言模型处理过程中的自适应多模态上下文整合。
自适应时间采样:实现了一种根据视频时长和内容特征进行调整的上下文感知采样机制。
- 对于运动粒度至关重要的较短序列,我们采用密集时间采样(每秒15帧)。
- 对于专注于事件级别理解的长序列(例如分钟/小时级别的视频),我们使用稀疏采样(每秒1帧)。
- 这种自适应方法确保了在不同时间尺度上都能正确捕捉运动。
分层token压缩:我们通过事件中的时空冗余和事件之间的语义冗余来压缩长视觉信号。
-
时空token合并:通过层次化压缩方案解决时空冗余问题,通过语义相似性进行令牌合并,保留视频中的关键信息:
-
给定一个被划分为T个时间片段的视频序列,每个片段由视觉编码器E处理以生成M个初始标记:vji(i=1,2,...,M)用于第j个片段。这些标记通过标记连接器C进行自适应压缩,产生N个压缩后的标记sji(i=1,2,...,N),其中N < M
-
![]()
通过语义相似性进行令牌合并,保留视频中的关键信息。实验表明,基于语义相似性的令牌合并方法(如ToMe)在视觉压缩中表现出色,能够在保留细节的同时显著减少计算开销。
-
多模态token丢弃:我们引入了在语言模型处理过程中运行的标记丢弃,以进一步优化长距离视觉理解。它实现了两阶段标记减少策略:
-
浅层中进行均匀token prune,以保持结构完整性,同时减少计算开销;
-
深层中进行注意力引导的token选择,以保留与任务的关键信息。
-
3.2 通过任务偏好优化增强多模态上下文中的视觉精度
为了增强多模态语言模型(MLLMs)在细粒度视觉任务中的表现,我们引入了多任务偏好学习(MPL)。该方法通过将专门的视觉感知模块与基础MLLM架构集成,实现了精确的定位和时间理解等能力。
-
时间理解:为了处理动态视觉内容,我们开发了一个时间组件,结合视频特征提取和时间对齐能力。该组件能够预测精确的时间边界和相关分数,从而帮助模型更好地理解视频中的时间关系。
-
实例分割:为了实现像素级理解和实例级区分,我们设计了一个分割模块,基于最新的分割基础模型(如SAM2)。该模块通过自适应投影层将MLLM的嵌入与像素级预测连接起来,从而实现了对视频中目标的精确分割。
模型通过联合优化视觉感知模块和基础MLLM,实现了对细粒度视觉任务的精确处理。
3.3 多模态上下文建模的训练视频语料库
训练过程分为三个阶段,分别使用了视觉-文本对齐数据、长视频数据和特定任务的视觉数据。训练数据如表1所示。
-
视觉-文本数据用于跨模态对齐:我们收集了包含700万图像-文本对和370万视频-文本对的视觉-文本数据,以及14.3万用于增强语言能力的文本数据。
-
长视频语料库用于上下文扩展:我们主要使用了来自MoiveChat、Cineplie、Vript和LongVid的长视频指令数据。
-
特定任务的数据用于精确感知:包括用于指代分割任务的MeViS和SAMv2,用于空间定位的AS-V2、Visual Genome、RefCOCO等。
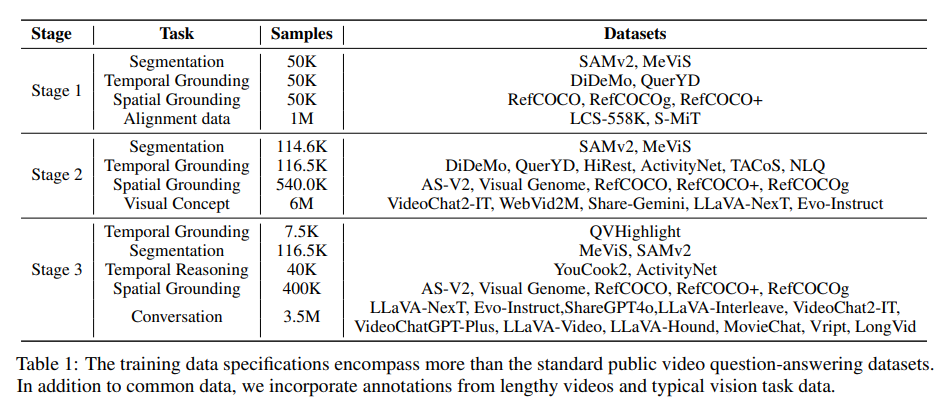
3.4 逐步多阶段训练
我们提出了一个统一的逐步训练方案,共同增强MLLM的细粒度感知和时间理解能力。该方法包括三个主要阶段,逐步增加任务的复杂性和视频输入的时间长度。
-
阶段1:基础学习:该阶段专注于两个并行目标:(a)使用多样化的对话模板对LLM进行任务识别指令调整,使模型能够识别和路由不同的视觉任务;(b)视频-语言对齐训练,其中我们冻结视觉编码器和LLM,同时优化压缩器和MLP以建立基本的视觉-语言连接。
-
阶段2:细粒度感知训练:该阶段通过(a)使用特定任务的数据集集成和训练特定任务的组件,包括任务标记、区域头、时间头和掩码适配器;以及(b)使用350万图像和250万短视频-文本对进行视觉概念预训练来增强模型的视觉理解能力。
-
阶段3:集成准确和长形式上下文训练:最后阶段通过(a)在结合多模态对话和特定任务数据的混合语料库上进行多任务训练,允许任务监督梯度从专门头流向MLLM;以及(b)在包含350万样本的综合数据集上进行指令调整,包括110万图像、170万短视频(<60秒)和70万长视频(60-3600秒)。
这种逐步训练策略使模型能够在发展细粒度感知和长形式视频理解的同时,减少对通用能力的潜在退化。与依赖长文本扩展上下文窗口的先前方法不同,我们直接在长视频上进行训练,以最小化训练和部署场景之间的差距。
3.5 实现
-
分布式系统:基于XTuner开发了一个多模态序列并行系统,用于训练和测试数百万个多模态标记(主要是视觉)。通过整合序列和张量分布式处理以及多模态动态(软)数据打包,我们实现了长视频的可扩展计算。
-
模型配置:在我们的多模态架构中,我们使用了一个结合先进视频处理和语言建模能力的综合框架。该系统实现了动态视频采样,处理64-512帧,每个8帧剪辑压缩为128个标记,产生大约每帧16个标记的表示
四、实验结果
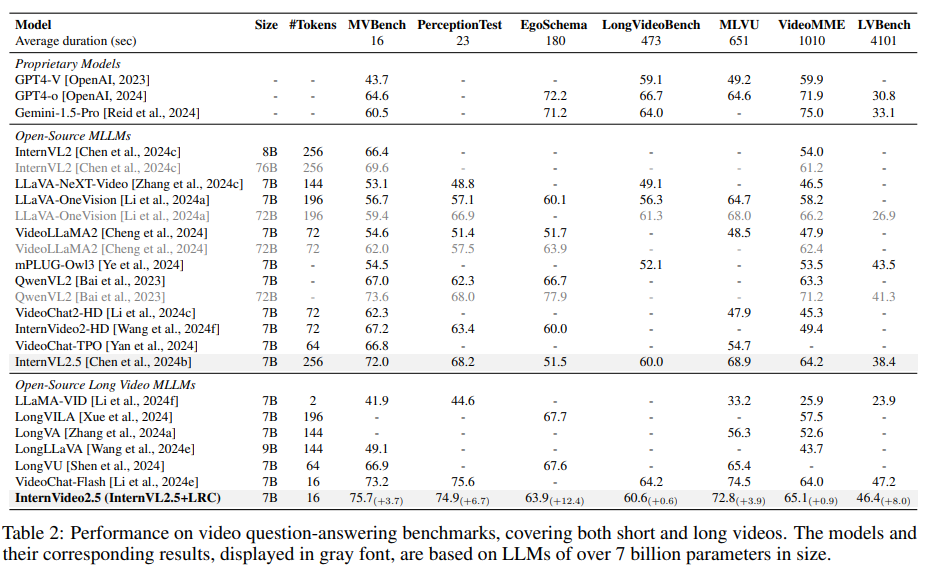
在MVBench和Perception Test上,InternVideo2.5分别提升了3.7分和6.7分。在长视频理解方面,InternVideo2.5在EgoSchema和MLVU上的提升尤为明显,分别提升了12.4分和3.9分
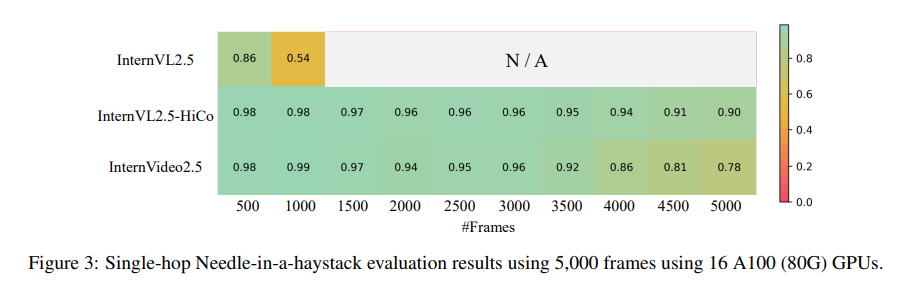
视频理解效果好,尤其是细节:

在特定任务上也表现出色: