EMA注意力机制
高效多尺度注意力(EMA)模块
作用:
-
多尺度特征融合
- 通过水平和垂直池化分离空间维度信息,结合1x1和3x3卷积捕捉局部与全局特征,实现对多尺度上下文的高效融合。
-
动态权重分配
- 使用可学习的权重矩阵(通过
softmax和matmul生成),动态调整不同区域特征的重要性,增强模型对关键区域的关注。
- 使用可学习的权重矩阵(通过
-
计算效率优化
- 分组卷积(Grouped Conv):将通道分组后并行处理,减少参数量和计算量(复杂度从
O(C^2)降至O(C/G * C/G),其中G为分组数)。 - 稀疏交互:仅对关键区域分配高权重,避免冗余计算。
- 分组卷积(Grouped Conv):将通道分组后并行处理,减少参数量和计算量(复杂度从
-
抑制梯度消失/爆炸
- GroupNorm:稳定训练过程,缓解内部协变量偏移。
- Sigmoid权重约束:确保权重在合理范围,避免数值不稳定。
-
任务适应性
- 适用于目标检测、语义分割等需要精细空间建模的任务,尤其在处理小目标或复杂纹理时表现突出。
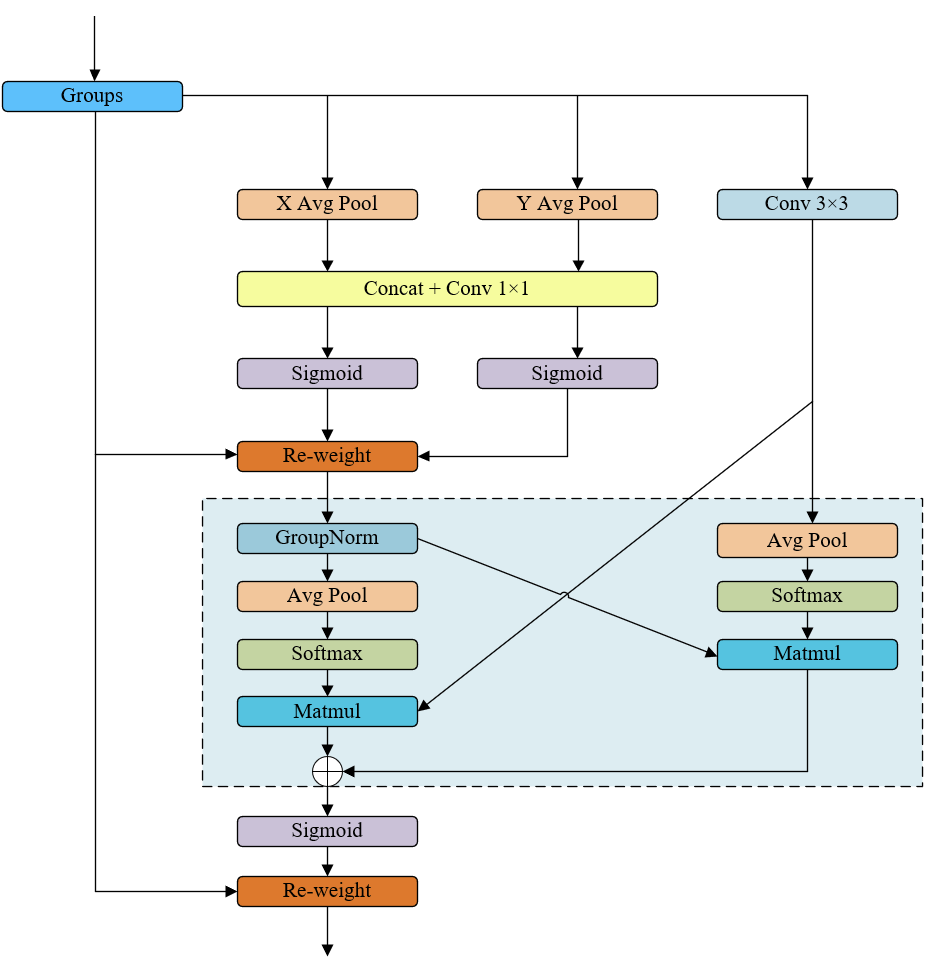
图1 EMA模块结构框图
源码如下:
import torch
from torch import nn
class EMA(nn.Module):
def __init__(self, channels, c2=None, factor=32):
super(EMA, self).__init__()
self.groups = factor
assert channels // self.groups > 0
self.softmax = nn.Softmax(-1)
self.agp = nn.AdaptiveAvgPool2d((1, 1))
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups)
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0)
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1)
def forward(self, x):
b, c, h, w = x.size()
group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,w
x_h = self.pool_h(group_x)
x_w = self.pool_w(group_x).permute(0, 1, 3, 2)
hw = self.conv1x1(torch.cat([x_h, x_w], dim=2))
x_h, x_w = torch.split(hw, [h, w], dim=2)
x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())
x2 = self.conv3x3(group_x)
x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)
return (group_x * weights.sigmoid()).reshape(b, c, h, w)