基于RoboTwin的数据训练RDT开源VLA模型
一、RoboTwin部署
1.配置RDT相关环境(python3.10 && torch2.1.0)
RoboticsDiffusionTransformer
conda create -n RoboTwin python=3.10.0
conda activate RoboTwin
# Install pytorch
# Look up https://pytorch.org/get-started/previous-versions/ with your cuda version for a correct command
pip install torch==2.1.0 torchvision==0.16.0 --index-url https://download.pytorch.org/whl/cu121
pip install packaging==24.0
# Install flash-attn
pip install flash-attn --no-build-isolation
# Install other prequisites
pip install -r requirements.txt2.配置RoboTwin
pip install sapien==3.0.0b1 scipy==1.10.1 mplib==0.1.1 gymnasium==0.29.1 trimesh==4.4.3 open3d==0.18.0 imageio==2.34.2 pydantic zarr openai huggingface_hub==0.25.03.测试是否配置成功
python scripts/test_render.py二、基于RoboTwin采集数据
采集数据
# 例如bash run_task.sh shoe_place 0
# 所有task_name可以在envs中查看
bash run_task.sh ${task_name} ${gpu_id}
bash run_task.sh block_hammer_beat 0数据格式转化hdf5
# 例如bash run_task.sh shoe_place 0
cd policy
git clone https://github.com/thu-ml/RoboticsDiffusionTransformer.git
mv RoboticsDiffusionTransformer-main RDT
mkdir RDT/processed_data
cd ..然后就可以在RoboTwin环境下运行python脚本pkl2hdf5_rdt.py
python pkl2hdf5_rdt.py ${task_name} ${setting} ${expert_data_num}
三、模型训练
基于RoboTwin的数据训练RDT和openpi两个目前认可度高的开源VLA模型。
RDT模型训练
RoboTwin最新版本已经集成RDT了,这是policy/RDT/README.md:
Deploy RDT on RoboTwin
1. Environment Setup
# Make sure python version == 3.10
conda activate RoboTwin# Install pytorch
# Look up https://pytorch.org/get-started/previous-versions/ with your cuda version for a correct command
pip install torch==2.1.0 torchvision==0.16.0 --index-url https://download.pytorch.org/whl/cu121
# Install packaging
pip install packaging==24.0
pip install ninja
# Verify Ninja --> should return exit code "0"
ninja --version; echo $?
# Install flash-attn
pip install flash-attn==2.7.2.post1 --no-build-isolation
# Install other prequisites
pip install -r requirements.txt
# If you are using a PyPI mirror, you may encounter issues when downloading tfds-nightly and tensorflow.
# Please use the official source to download these packages.
# pip install tfds-nightly==4.9.4.dev202402070044 -i https://pypi.org/simple
# pip install tensorflow==2.15.0.post1 -i https://pypi.org/simple2. Download Model
# In the RoboTwin/policy directory
cd ../weights
mkdir RDT && cd RDT
# Download the models used by RDT
huggingface-cli download google/t5-v1_1-xxl --local-dir t5-v1_1-xxl
huggingface-cli download google/siglip-so400m-patch14-384 --local-dir siglip-so400m-patch14-384
huggingface-cli download robotics-diffusion-transformer/rdt-1b --local-dir rdt-1b3 Generate HDF5 Data
First, create the processed_data and training_data folders in the policy/RDT directory:
mkdir processed_data && mkdir training_data
To generate the data for converting to HDF5, you need to run the following command in the RoboTwin/ directory:
cd ../..
bash run_task.sh ${task_name} ${gpu_id}The data will be saved by default in the RoboTwin/data/${task_name}_${camera_type}_pkl directory.
Then, run the following in the RoboTwin/policy/RDT directory:
cd policy/RDT
# task_name: the already generated data, default located in data/${task_name}
# head_camera_type: default to D435
# expert_data_num: the number of data to be converted to hdf5
# gpu_id: running language encoding,default to 0
# After running, the data will be saved to policy/RDT/processed_data by default
bash process_data_rdt.sh $task_name $head_camera_type $expert_data_num $gpu_idIf success, you will find the ${task_name}_${expert_data_num} folder under policy/RDT/processed_data, with the following data structure:
`processed_data/${task_name}_${expert_data_num}:`
`instructions/lang_embed_{%d}.pt`
`episode_{%d}.hdf5`4. Generate Configuration File
cd policy/RDT
# model_name: the name you want to save your model as, it is recommended to use ${task_name_1}_${num_1}_${task_name_2}_${num_2}... for easy record-keeping
bash generate.sh ${model_name}This will create a folder named \${model_name} under training_data and a configuration file \${model_name}.yml under model_config.
Move all the data you wish to use for training into training_data${model_name}. If you have multiple tasks with different data, simply move them in the same way.
5 Finetune model
Once the training parameters are set, you can start training with:
bash finetune.sh ${model_name}6. Eval on RoboTwin
Once the model fine-tuning is complete, you can test your model’s performance on the RoboTwin simulation platform. RoboTwin offers more than 20 tasks to choose from, and you can find them in the RoboTwin/task_config directory.
bash eval.sh $task_name $head_camera_type $model_name $checkpoint_id $seed $gpu_id模型训练笔记
huggingface-cli download google/t5-v1_1-xxl --local-dir t5-v1_1-xxl t5-v1_1-xxl

输出了render ok就是成功了
https://github.com/TianxingChen/RoboTwin/blob/main/policy/RDT/README.md
https://github.com/TianxingChen/RoboTwin/blob/main/INSTALLATION.md
https://github.com/TianxingChen/RoboTwin/blob/main/policy/RDT/README.md
具身智能VLA方向--基于仿真数据的单/双臂VLA模型训练(RDT与openpi)-CSDN博客
具身智能VLA方向--基于仿真数据的单/双臂VLA模型训练(RDT与openpi)-CSDN博客
【Generate HDF5 Data】
bash run_task.sh block_hammer_beat 0
bash process_data_rdt.sh block_hammer_beat D435 100 0
【生成模型】
bash generate.sh block_hammer_beat
【微调】
bash finetune.sh block_hammer_beat
【假设你想增加调试信息并记录输出日志,可以尝试如下命令】
bash finetune.sh block_hammer_beat --verbose > output.log 2>&1
+++++++++++++++++++++++++++++++++++++++++++++
笔记
解决报错
1.Windows: 解决diffusers库所导致的ImportError: cannot import name ‘cached_download‘ from ‘huggingface_hub‘
Windows: 解决diffusers库所导致的ImportError: cannot import name ‘cached_download‘ from ‘huggingface_hub‘_diffuers库的报错原因以及解决方法-CSDN博客
2.huggingface-cli download google/t5-v1_1-xxl --local-dir t5-v1_1-xxl失败问题
export HF_ENDPOINT="https://hf-mirror.com"
https://zhuanlan.zhihu.com/p/663712983
3.修改批处理大小
如果你原来的批处理大小是32,可以尝试减半到16或更小:
python main.py --train_batch_size=16 --sample_batch_size=32
export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128
4.训练配置文件
model: block_hammer_beat
data_path: training_data/block_hammer_beat
checkpoint_path: checkpoints/block_hammer_beat
pretrained_model_name_or_path: ../weights/RDT/rdt-1b
cuda_visible_device: 1
train_batch_size: 1
sample_batch_size: 8 # 减小 sample_batch_size
max_train_steps: 20000
checkpointing_period: 2500
sample_period: 100
checkpoints_total_limit: 40
learning_rate: 0.0001
dataloader_num_workers: 4 # 减少数据加载器工作线程数
state_noise_snr: 40
gradient_accumulation_steps: 4 # 增加梯度累积步数
mixed_precision: bf16 # 启用混合精度训练
训练结果
mple_l2err': 1.71, 'overall_avg_sample_mse': 0.0008, 'overall_avg_sample_l2err': 1.71}
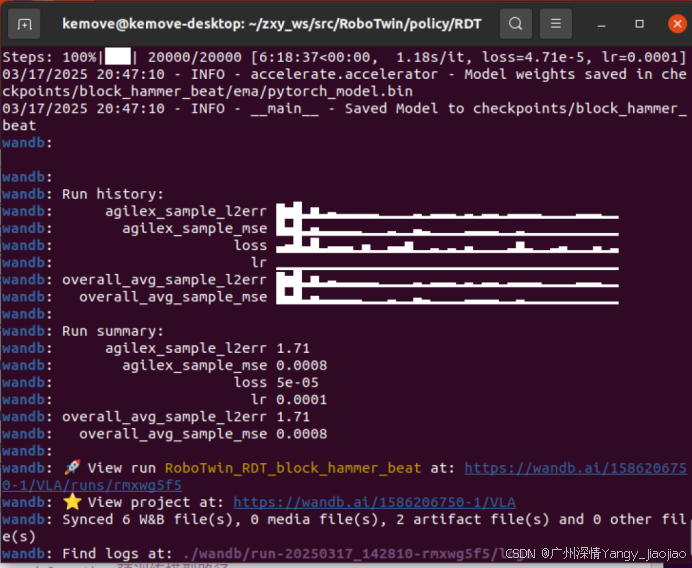
Steps: 100%|███| 20000/20000 [6:18:37<00:00, 1.18s/it, loss=4.71e-5, lr=0.0001]03/17/2025 20:47:10 - INFO - accelerate.accelerator - Model weights saved in checkpoints/block_hammer_beat/ema/pytorch_model.bin
03/17/2025 20:47:10 - INFO - __main__ - Saved Model to checkpoints/block_hammer_beat
wandb:
wandb:
wandb: Run history:
wandb: agilex_sample_l2err ▇▅█▂▅▂▃▂▂▂▂▂▁▁▁▁▂▁▂▂▂▁▂▁▂▂▁▂▂▂▂▁▁▁▁▂▂▂▁▁
wandb: agilex_sample_mse █▄█▂▄▂▂▂▂▂▁▁▁▂▁▁▃▂▁▁▁▁▂▂▂▂▁▁▂▁▁▁▁▁▁▁▁▁▁▁
wandb: loss ▃▄█▃▇▂▃▃▃▁▄▁▁▃▃▅▁▁▂▁▂▁▃▁▁▁▁▂▅▂▁▁▂▃▁▁▁▃▁▂
wandb: lr ▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁
wandb: overall_avg_sample_l2err ▇▅█▂▅▂▃▂▂▂▂▂▁▁▁▁▂▁▂▂▂▁▂▁▂▂▁▂▂▂▂▁▁▁▁▂▂▂▁▁
wandb: overall_avg_sample_mse █▄█▂▄▂▂▂▂▂▁▁▁▂▁▁▃▂▁▁▁▁▂▂▂▂▁▁▂▁▁▁▁▁▁▁▁▁▁▁
wandb:
wandb: Run summary:
wandb: agilex_sample_l2err 1.71
wandb: agilex_sample_mse 0.0008
wandb: loss 5e-05
wandb: lr 0.0001
wandb: overall_avg_sample_l2err 1.71
wandb: overall_avg_sample_mse 0.0008
wandb:
wandb:
bash eval.sh $task_name $head_camera_type $train_config_name $model_name $checkpoint_id $seed $gpu_id
bash eval.sh block_hammer_beat D435 $train_config_name $model_name $checkpoint_id $seed $gpu_id
微调结果
数据生成

参考资料
https://github.com/TianxingChen/RoboTwin/blob/main/policy/RDT/README.md
https://github.com/TianxingChen/RoboTwin/blob/main/README.md
https://github.com/TianxingChen/RoboTwin/blob/main/INSTALLATION.md
参考链接
https://github.com/TianxingChen/RoboTwin/blob/main/policy/RDT/README.md
https://github.com/TianxingChen/RoboTwin/blob/main/INSTALLATION.md
https://github.com/TianxingChen/RoboTwin/blob/main/policy/RDT/README.md
具身智能VLA方向--基于仿真数据的单/双臂VLA模型训练(RDT与openpi)-CSDN博客
具身智能VLA方向--基于仿真数据的单/双臂VLA模型训练(RDT与openpi)-CSDN博客