【论文笔记】RL在LLM中的落地方法
文章目录
- 数据合成(RLAIF)
-
- ReST
- Slef-rewarding LM
- Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning
- 泛化/自我提升
-
- Easy-to-Hard Generalization: Scalable Alignment Beyond Human Supervision
- Small Language Models Need Strong Verifiers to Self-Correct Reasoning
- Time-search
-
- Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
- Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
- Retrieval Augmented Thought Process for Private Data Handling in Healthcare
数据合成(RLAIF)
优点:无需人工干预,机器自己给自己提供训练语料
缺点:可能过拟合
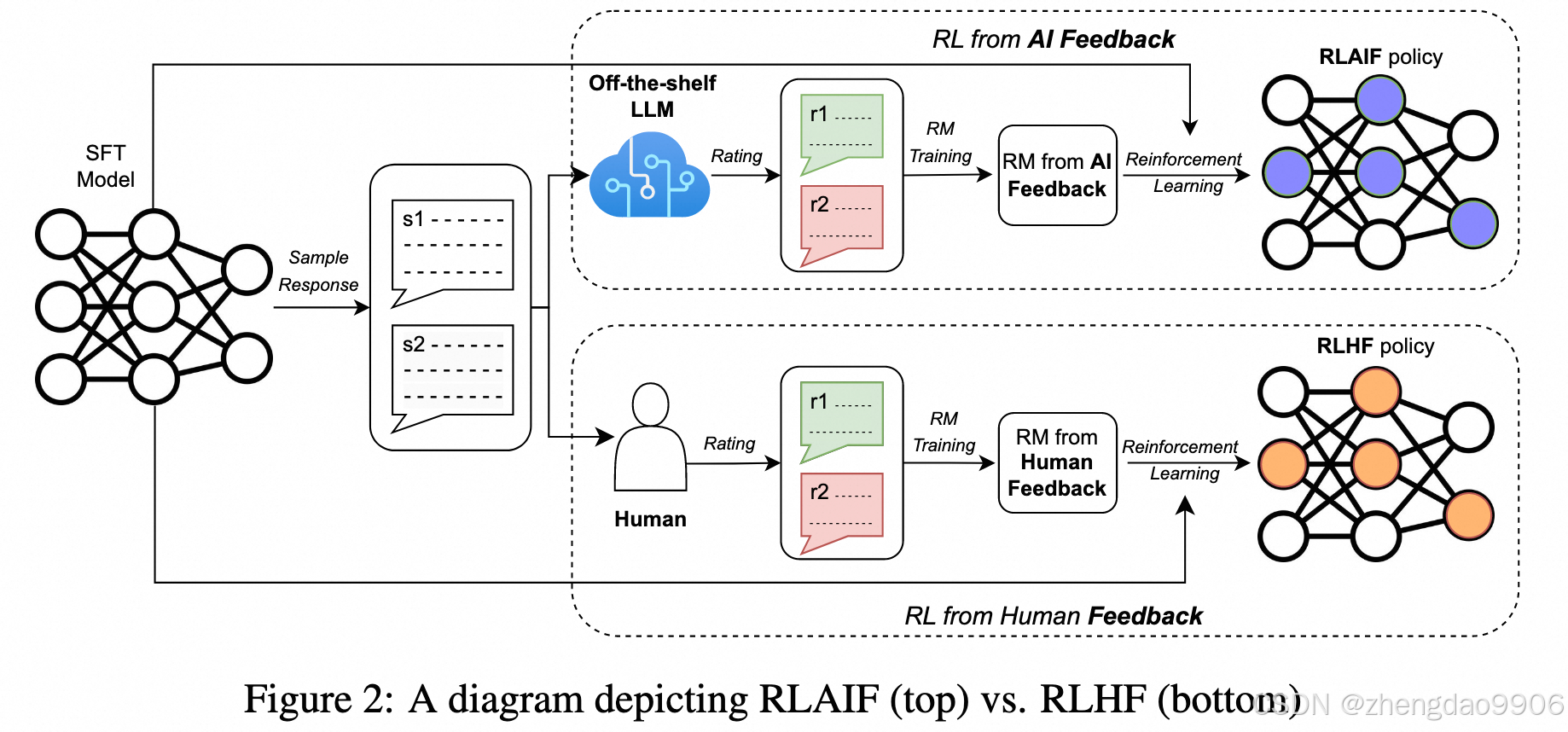
目前我比较认可的一种范式:“RLAIF”(http://arxiv.org/abs/2309.00267),即通过 LLM 给予 LLM 反馈,实现一种 self-play+RL 的效果。
就像AlphaGo和AlphaZero的关系那样,AlphaZero在训练过程中,没有用到人类的棋谱。这种范式下,机器自己给自己提供训练语料、奖励函数,人类的能力不会成为瓶颈。
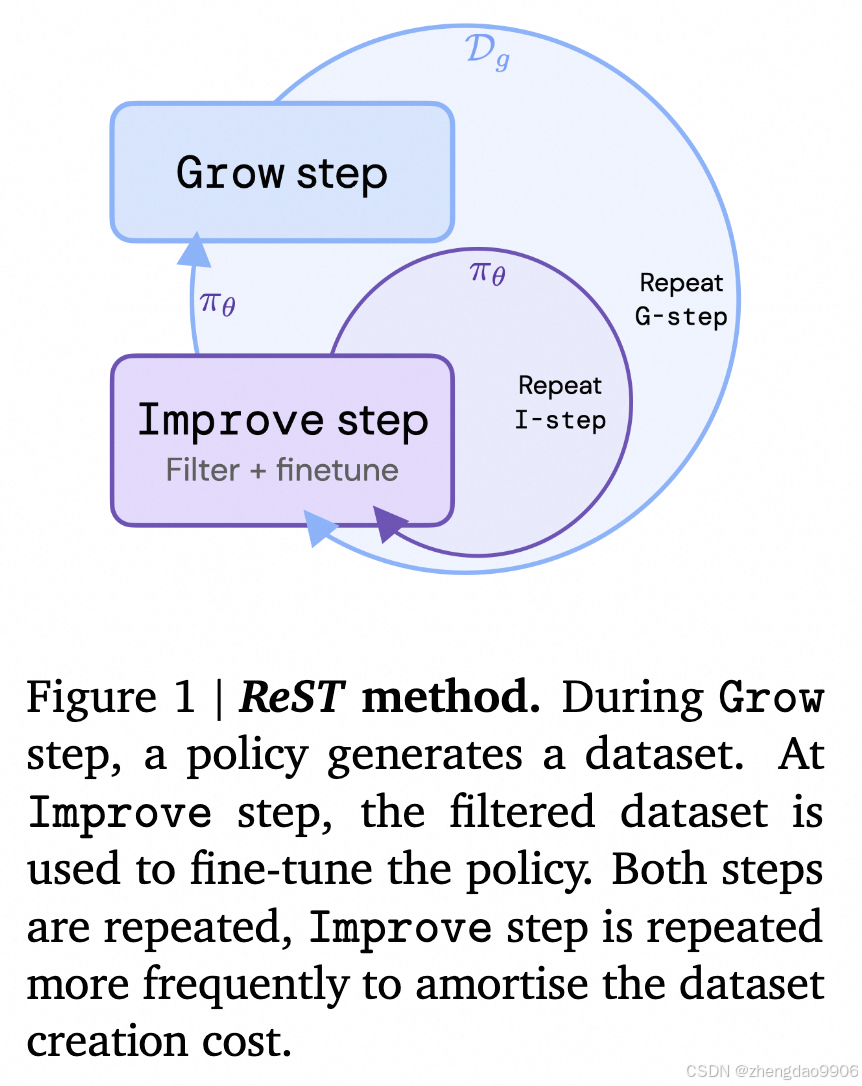
ReST
http://arxiv.org/abs/2308.08998, ReST(2023),早期数据合成方案,Grow 阶段生成多个输出预测、并打分构建数据集,在 Improve 阶段使用高质量数据进行 finetune;通过两个阶段的不断迭代,提升模型的性能。
类似 alphaGo,G 步骤就是不断自我对弈产生新的训练集,I 步骤就是通过训练迭代优化策略。
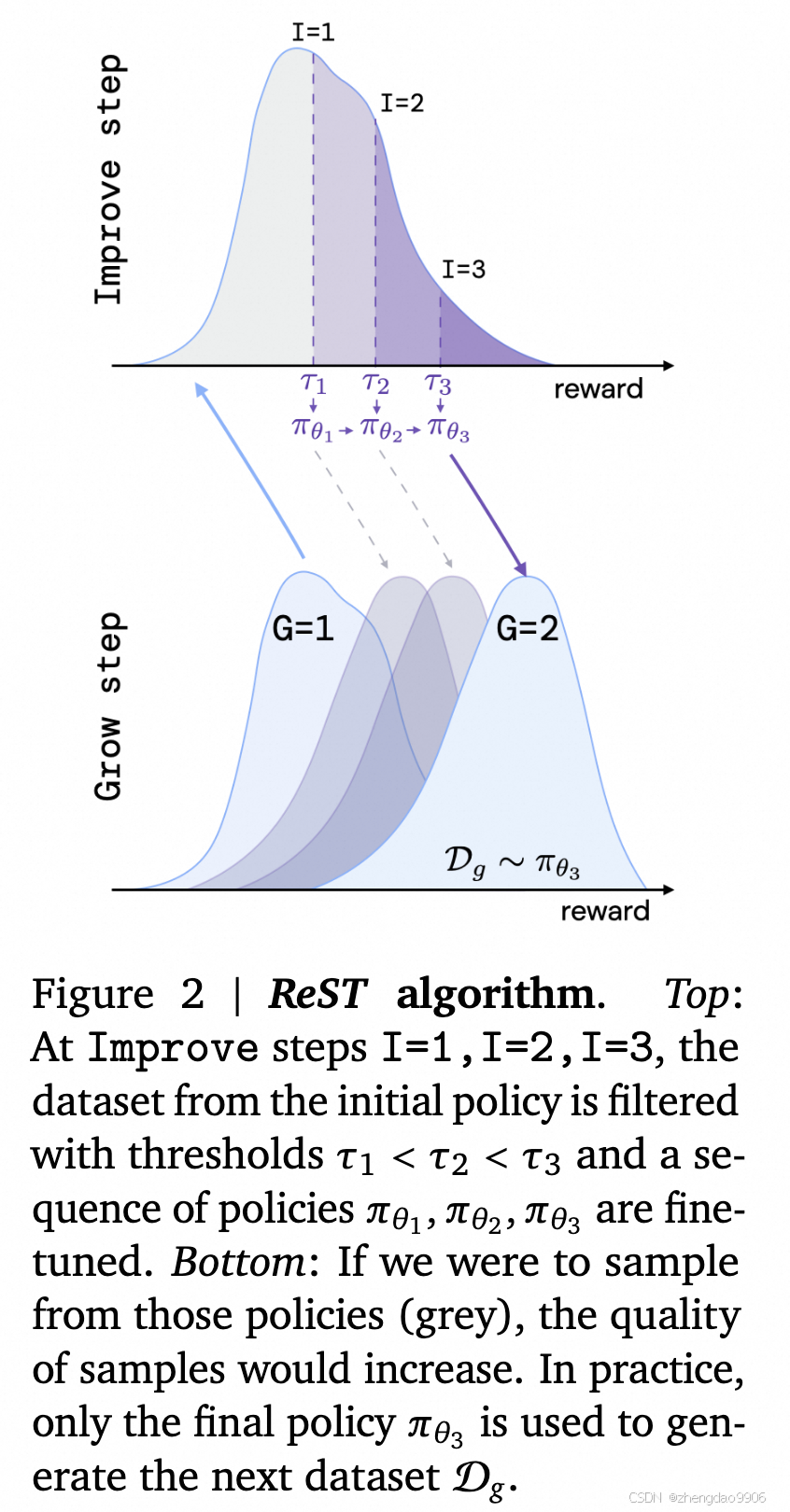
如Fig2所示,理想情况下,随着I轮数的增加,模型G步骤产生的策略,也能够获得更多Reward,提高最终数据集的数据质量,形成良性循环。
这个训练策略看起来比较简单,如果应用于数学/代码等领域,是否会有 reward hacking、overfitting 问题?后续有不少文章指出了这一点。
Slef-rewarding LM
http://arxiv.org/abs/2401.10020,2024,也很有名。给模型打分的不应该是人类,而应该是模型;这样人类的能力才不会成为瓶颈。
跟 ReST 做 SFT 不一样,这里是使用模型自己生成内容,自己打分形成偏好数据集,进行 DPO 训练生成下一代模型。
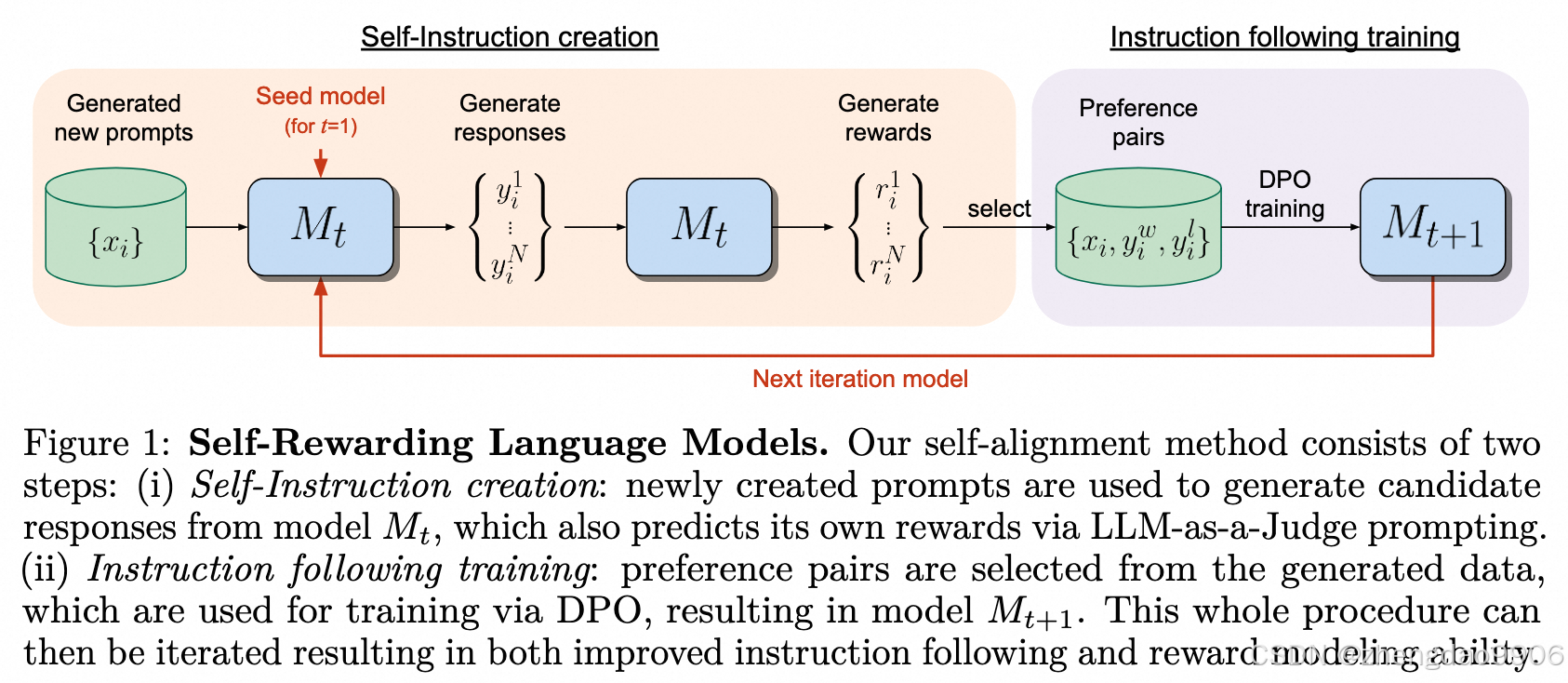
这张训练框架图画得很清晰了。根据 prompt 模型生成一系列回答 y,然后用模型评价并估计每个回答的奖励函数 r,如此一来,就可以生成一系列 偏好数据集,用于 DPO 训练。
语言模型评估往往倾向于更长的回答,或许是一种 reward hacking 的表现。另外也有多样性丧失的风险。