AI小白:AI算法中常用的数学函数

文章目录
一、激活函数
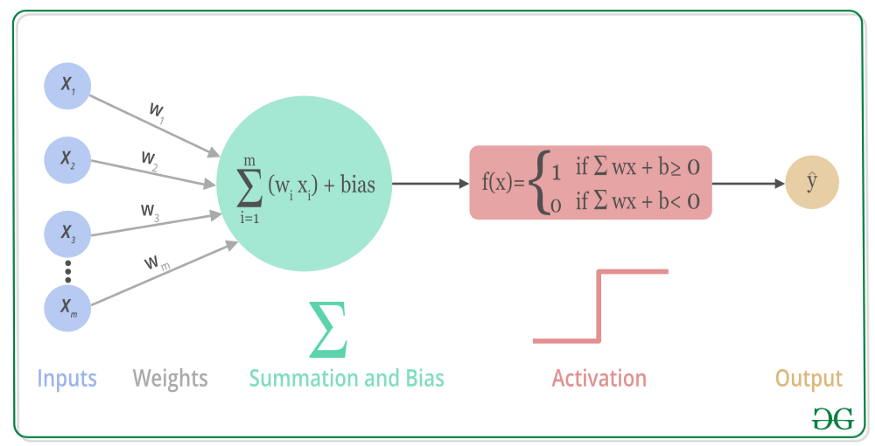
激活函数在神经网络中起着至关重要的作用,它们为网络引入非线性特性,使得网络能够学习复杂的模式和关系。以下是几种常见的激活函数及其特点:
1. Sigmoid
Sigmoid函数是一种常用的激活函数,能够将输入映射到(0,1)区间,常用于二分类问题的输出层。
- 数学形式:
$ f(x) = \frac{1}{1 + e^{-x}} $
- 应用:
- 二分类输出层:将输出映射到(0,1)区间,表示概率。
- 缺点:
- 梯度消失问题显著:当输入值较大或较小时,梯度接近于零,导致训练过程中的梯度更新非常缓慢。
- 输出非零中心:输出值集中在(0,1)区间,可能导致梯度更新时的偏移。
2. ReLU(Rectified Linear Unit)
ReLU是一种非常流行的激活函数,特别是在深度学习中。它通过引入非线性特性,同时保持计算的高效性。
- 数学形式:
$ f(x) = \max(0, x) $
- 应用:
- 神经网络隐藏层:计算高效且缓解梯度消失问题。
- 变体:
- Leaky ReLU:在负数区域引入一个小斜率,解决“死神经元”问题。数学形式为:
$ f(x) = \begin{cases}
x & \text{if } x > 0
\alpha x & \text{if } x \leq 0
\end{cases} $
其中,(\alpha) 是一个小的正数,通常取0.01。
3. Tanh(双曲正切)
Tanh函数是Sigmoid函数的一个变体,其输出范围为(-1,1),具有零中心特性。
- 数学形式:
$ f(x) = \frac{e^x - e{-x}}{ex + e^{-x}} $
- 应用:
- 输出映射到(-1,1):零中心特性适合隐藏层,有助于梯度更新。
4. Softmax
Softmax函数用于多分类问题的输出层,将输出归一化为概率分布。
- 数学形式:
$ f(x_i) = \frac{e{x_i}}{\sum_{j=1}n e^{x_j}} $
- 应用:
- 多分类输出层:将输出归一化为概率分布,表示每个类别的概率。
示例代码:激活函数的实现
import numpy as np
import matplotlib.pyplot as plt
# Sigmoid函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# ReLU函数
def relu(x):
return np.maximum(0, x)
# Leaky ReLU函数
def leaky_relu(x, alpha=0.01):
return np.where(x > 0, x, alpha * x)
# Tanh函数
def tanh(x):
return np.tanh(x)
# Softmax函数
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum()
# 绘制激活函数
x = np.linspace(-5, 5, 100)
plt.figure(figsize=(12, 8))
plt.subplot(2, 2, 1)
plt.plot(x, sigmoid(x), label='Sigmoid')
plt.title('Sigmoid Function')
plt.legend()
plt.subplot(2, 2, 2)
plt.plot(x, relu(x), label='ReLU')
plt.title('ReLU Function')
plt.legend()
plt.subplot(2, 2, 3)
plt.plot(x, leaky_relu(x), label='Leaky ReLU')
plt.title('Leaky ReLU Function')
plt.legend()
plt.subplot(2, 2, 4)
plt.plot(x, tanh(x), label='Tanh')
plt.title('Tanh Function')
plt.legend()
plt.tight_layout()
plt.show()
# Softmax函数示例
x = np.array([2.0, 1.0, 0.1])
softmax_values = softmax(x)
print("Softmax输出:", softmax_values)
激活函数是神经网络中的关键组件,它们为网络引入非线性特性,使得网络能够学习复杂的模式和关系。Sigmoid函数适用于二分类问题的输出层,ReLU及其变体(如Leaky ReLU)适用于隐藏层,Tanh函数适用于需要零中心输出的场景,而Softmax函数则用于多分类问题的输出层。选择合适的激活函数对于模型的性能和训练效率至关重要。
二、损失函数
损失函数是衡量模型预测值与真实值之间差异的重要指标,用于指导模型的训练过程。以下是两种常见的损失函数:均方误差(MSE)和交叉熵损失。
1. 均方误差(MSE)
均方误差是回归任务中常用的损失函数,用于衡量预测值与真实值之间的平方差的平均值。
- 数学形式:
$ J(\theta) = \frac{1}{2m} \sum_{i=1}m (h_\theta(x{(i)}) - y{(i)})2 $
其中,$ (h_\theta(x{(i)})) $ 是模型的预测值,$ (y{(i)}) $是真实值,(m) 是样本数量。
- 应用:
- 回归任务:用于衡量预测值与真实值之间的差异,常用于线性回归和多项式回归等任务。
2. 交叉熵损失(Cross-Entropy)
交叉熵损失是分类任务中常用的损失函数,用于衡量模型预测的概率分布与真实标签之间的差异。
- 数学形式:
$ L = -\sum_{i=1}^n y_i \log(p_i) $
其中,$ (y_i) 是真实标签( 0 或 1 ), 是真实标签(0或1), 是真实标签(0或1), (p_i) $ 是模型预测的概率值。
- 应用:
- 分类任务:与Softmax函数结合,用于优化多分类任务中的概率分布。
- 二分类任务:在二分类任务中,交叉熵损失可以简化为:
$ L = -\left[ y \log§ + (1 - y) \log(1 - p) \right]
$
其中,(y) 是真实标签(0或1),§ 是模型预测的正类概率。
示例代码:均方误差和交叉熵损失
import numpy as np
# 均方误差(MSE)
def mean_squared_error(y_true, y_pred):
return np.mean((y_pred - y_true) ** 2)
# 交叉熵损失
def cross_entropy_loss(y_true, y_pred):
return -np.sum(y_true * np.log(y_pred + 1e-9)) # 添加小常数避免log(0)
# 示例数据
y_true = np.array([1, 2, 3, 4])
y_pred = np.array([1.1, 1.9, 3.1, 4.1])
mse = mean_squared_error(y_true, y_pred)
print("均方误差(MSE):", mse)
y_true = np.array([0, 1, 0, 1])
y_pred = np.array([0.1, 0.9, 0.2, 0.8])
ce_loss = cross_entropy_loss(y_true, y_pred)
print("交叉熵损失:", ce_loss)
损失函数是机器学习和深度学习中的核心概念,用于衡量模型预测值与真实值之间的差异。均方误差(MSE)适用于回归任务,而交叉熵损失适用于分类任务。选择合适的损失函数对于模型的训练和优化至关重要。
三、概率相关函数
1. 概率密度函数(如高斯分布)
概率密度函数(PDF)描述了连续随机变量的概率分布。高斯分布(正态分布)是最常见的一种概率密度函数,广泛应用于统计学和机器学习中。
- 数学形式:
$ f(x) = \frac{1}{\sigma\sqrt{2\pi}} e{-\frac{(x-\mu)2}{2\sigma^2}} $
其中,$ (\mu) 是均值, 是均值, 是均值, (\sigma) 是标准差, 是标准差, 是标准差, (\sigma^2) $是方差。
- 应用:
- 贝叶斯推断:在贝叶斯统计中,高斯分布常用于描述先验和后验分布。
- 生成模型:在生成对抗网络(GAN)和变分自编码器(VAE)中,高斯分布用于建模数据的潜在分布。
2. Sigmoid概率输出
Sigmoid函数是一种常用的激活函数,能够将输入映射到(0,1)区间,常用于二分类问题中输出概率。
- 数学形式:
$ \sigma(x) = \frac{1}{1 + e^{-x}} $
- 应用:
- 逻辑回归:在逻辑回归中,Sigmoid函数用于将线性模型的输出转换为概率,从而实现二分类。
- 二分类问题:在深度学习中,Sigmoid函数常用于二分类任务的输出层,直接输出样本属于某一类的概率。
示例代码:概率密度函数和Sigmoid函数
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 高斯分布的概率密度函数
mu = 0 # 均值
sigma = 1 # 标准差
x = np.linspace(-5, 5, 100)
pdf = norm.pdf(x, mu, sigma)
plt.plot(x, pdf, label='Gaussian Distribution')
plt.xlabel('x')
plt.ylabel('Probability Density')
plt.title('Gaussian Distribution (μ=0, σ=1)')
plt.legend()
plt.show()
# Sigmoid函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.linspace(-10, 10, 100)
sigmoid_values = sigmoid(x)
plt.plot(x, sigmoid_values, label='Sigmoid Function')
plt.xlabel('x')
plt.ylabel('Sigmoid(x)')
plt.title('Sigmoid Function')
plt.legend()
plt.show()
概率相关函数在机器学习和深度学习中起着重要作用。高斯分布的概率密度函数用于描述连续随机变量的概率分布,广泛应用于贝叶斯推断和生成模型中。Sigmoid函数则用于将输入映射到(0,1)区间,常用于二分类问题中输出概率。掌握这些概率相关函数对于理解和实现机器学习算法非常重要。
四、优化相关函数
1. 梯度下降的梯度计算
梯度下降是一种常用的优化算法,用于最小化损失函数。通过计算损失函数对参数的梯度,逐步调整参数以找到损失函数的最小值。
- 数学形式:
$
\theta_j := \theta_j - \alpha \frac{\partial J(\theta)}{\partial \theta_j}
$
其中,$ (\theta_j) $ 是模型参数,$ (\alpha)
是学习率, 是学习率, 是学习率, (J(\theta)) 是损失函数, 是损失函数, 是损失函数, (\frac{\partial J(\theta)}{\partial \theta_j})
$是损失函数对参数 $ (\theta_j) $的梯度。 - 应用:
- 参数更新:通过计算梯度并更新参数,逐步最小化损失函数。
- 最小化损失函数:在训练过程中,梯度下降算法帮助模型找到最优参数,从而提高模型的性能。
2. 正则化项(L1/L2范数)
正则化是一种防止模型过拟合的技术,通过在损失函数中加入正则化项来约束模型的复杂度。
- 数学形式:
- L2正则化:
$ J(\theta) = J(\theta) + \lambda \sum \theta_j^2 $
其中,$ (\lambda) 是正则化参数, 是正则化参数, 是正则化参数, (\sum \theta_j^2) $是参数的L2范数。
- **L1正则化**:
$ J(\theta) = J(\theta) + \lambda \sum |\theta_j| $
其中,(\sum |\theta_j|) 是参数的L1范数。
- 应用:
- 防止过拟合:通过在损失函数中加入正则化项,可以减少模型对训练数据的过度拟合,提高模型的泛化能力。
- 约束模型复杂度:正则化项通过惩罚过大的参数值,限制模型的复杂度,使模型更加简洁和稳定。
示例代码:梯度下降和L2正则化
import numpy as np
# 梯度下降示例
def gradient_descent(X, y, theta, alpha, num_iterations):
m = len(y)
for i in range(num_iterations):
predictions = X.dot(theta)
errors = np.dot(X.transpose(), (predictions - y))
theta -= alpha * (1/m * errors + 2 * lambda_ * theta)
return theta
# L2正则化示例
lambda_ = 0.1 # 正则化参数
X = np.array([[1, 2], [3, 4], [5, 6]]) # 特征矩阵
y = np.array([1, 2, 3]) # 目标值
theta = np.array([0.0, 0.0]) # 初始参数
alpha = 0.01 # 学习率
num_iterations = 1000 # 迭代次数
theta = gradient_descent(X, y, theta, alpha, num_iterations)
print("优化后的参数:")
print(theta)
优化相关函数在深度学习和机器学习中起着关键作用。梯度下降算法通过计算梯度并更新参数,帮助模型最小化损失函数,提高性能。正则化项(如L1和L2范数)通过在损失函数中加入惩罚项,防止模型过拟合,提高模型的泛化能力。掌握这些优化技术对于构建高效、稳定的模型至关重要。
五、基础数学工具函数
1. 矩阵乘法与分解
矩阵乘法和分解是线性代数中的基本操作,它们在深度学习和机器学习中扮演着重要的角色。
- 应用:
- 神经网络权重更新:在反向传播过程中,矩阵乘法用于计算梯度和更新权重。
- 主成分分析(PCA):矩阵分解用于将数据投影到主要成分上,实现降维。
- 示例代码:矩阵乘法与分解
import numpy as np
# 矩阵乘法
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
C = np.dot(A, B)
print("矩阵乘法结果:")
print(C)
# 矩阵分解(PCA)
from sklearn.decomposition import PCA
X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X)
print("PCA降维结果:")
print(X_reduced)
2. 指数与对数函数
指数和对数函数是数学中的基本函数,它们在深度学习中用于各种计算,特别是在处理概率和损失函数时。
- 应用:
- Softmax:将模型的输出转换为概率分布,常用于多分类问题。
- 交叉熵损失:用于计算模型输出与真实标签之间的差异,对数函数在其中用于处理概率值,提高数值稳定性。
- 示例代码:指数与对数函数
import numpy as np
# Softmax函数
def softmax(x):
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum()
logits = np.array([2.0, 1.0, 0.1])
probs = softmax(logits)
print("Softmax结果:")
print(probs)
# 交叉熵损失
def cross_entropy(y_true, y_pred):
return -np.sum(y_true * np.log(y_pred))
y_true = np.array([1, 0, 0])
y_pred = np.array([0.7, 0.2, 0.1])
loss = cross_entropy(y_true, y_pred)
print("交叉熵损失结果:")
print(loss)
基础数学工具函数是深度学习和机器学习中的重要组成部分。矩阵乘法与分解在处理数据和模型参数时至关重要,而指数与对数函数则在处理概率和损失函数时发挥着关键作用。掌握这些基础数学工具函数对于理解和实现深度学习算法非常重要。
关键应用场景总结
| 函数类型 | 典型算法/模型 | 作用 |
|---|---|---|
| Sigmoid/Softmax | 逻辑回归、神经网络分类层 | 概率映射与多分类决策13 |
| ReLU/Tanh | CNN、RNN隐藏层 | 非线性特征提取与梯度稳定45 |
| MSE/交叉熵 | 线性回归、深度学习分类任务 | 误差度量与模型优化13 |
| 正则化项 | 防止过拟合的模型(如Lasso、SVM) | 参数约束与泛化提升48 |
以上函数在AI算法中通过组合使用(如Softmax+交叉熵、ReLU+梯度下降)实现模型训练与推理,需结合实际任务选择适配函数。
图片来源网络,侵权删