杂谈:模型训练参数是否存在临界点?
在深度学习模型的训练过程中,参数数量(模型规模)与模型性能之间的关系并非无限增长,而是存在一定的 “临界点”或 “收益递减点”。以下是关键分析:
---
1. 参数增长的收益递减现象
(1) Scaling Laws(缩放定律)
OpenAI、DeepMind 等机构的研究表明,模型性能(如损失函数值)与参数数量(N)、计算量(C)、数据量(D) 之间存在幂律关系:
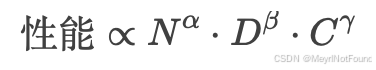
但 随着参数增长,单位参数带来的性能提升逐渐降低(即 alpha值减小)。
例子
- GPT-3(1750亿参数)相比 GPT-2(15亿参数)性能显著提升。
- GPT-4(约1.8万亿参数)相比 GPT-3 的提升幅度相对减小。
(2) 数据瓶颈
高质量数据有限:当模型参数远大于训练数据量时,容易过拟合。
数据重复利用:大规模模型(如LLM)通常需要多次训练相同数据,边际收益下降。
---
2. 参数临界点的实际限制
(1) 硬件算力限制
显存限制:单张GPU(如A100 80GB)最多训练 百亿级参数的稠密模型(Dense Model),万亿级模型需分布式训练。
通信开销:参数越多,分布式训练的同步成本(如All-Reduce)越高,效率下降。
(2) 训练稳定性问题
梯度消失/爆炸:超深层模型(如1000+层)的梯度传递困难。
优化器失效:Adam/SGD等优化器在超大规模参数下可能难以收敛。
(3) 边际成本激增
训练成本非线性增长: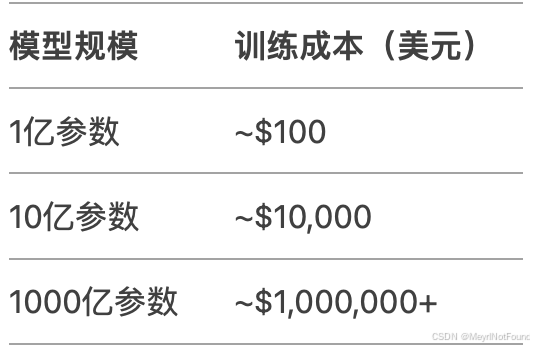
- 商业公司(如OpenAI、Google)可能继续推进,但对大多数研究者不现实。
---
3. 参数临界点的理论探讨
(1) 模型容量 vs. 任务复杂度
简单任务(如MNIST分类):几万参数即可饱和性能,增加参数无益。
复杂任务(如多模态推理):参数需求更高,但仍存在上限。
(2) 信息论视角
参数存储的信息量:模型参数本质是“压缩”训练数据的知识,但数据的信息量有限(香农熵)。
过参数化(Overparameterization):
当参数远超数据信息量时,多余参数仅拟合噪声,泛化性能不再提升。
(3) 神经网络的“无限宽度”理论
- 理论上,无限宽度的神经网络*可以逼近任意函数(Universal Approximation Theorem)。
- 但实际中,有限数据和计算资源使得无限参数无意义
---
4. 如何突破“参数临界点”?
(1) 稀疏化与条件计算
混合专家(MoE):如Google的Switch Transformer(万亿参数,但每次激活部分参数)。
动态网络:根据输入调整参数量(如早退机制)。
(2) 更高效的架构
非Transformer模型:如Mamba(状态空间模型)、RetNet(保留Transformer优势但更高效)。
神经符号混合:结合符号逻辑减少对纯参数的依赖。
(3) 数据与算法优化
合成数据:用生成模型(如Diffusion)创造高质量训练数据。
课程学习(Curriculum Learning):分阶段训练,逐步增加数据复杂度。
---
结论:参数临界点确实存在
1. 短期:参数数量仍会增长(如10万亿级模型),但依赖 稀疏化、MoE 等技术。
2. 长期:AI发展的核心指标将从“参数量”转向 “单位算力的性能提升”,重点包括:
- 更高参数效率的架构(1万亿参数模型达到当前10万亿的性能)。
- 更低的训练/推理成本(如1%算力实现同等效果)。
3. 对研究者的启示:
- 盲目堆参数已不可持续,需关注 轻量化技术(蒸馏、量化)和 算法创新。
未来,“小模型+高效训练”可能比“暴力Scaling”更具竞争力!