ebpf: CO-RE, BTF, and Libbpf(一)
本文内容主要来源于Learning eBPF,可阅读原文了解更全面的内容。
概述
一个ebpf程序可以在一个kernel版本中编译,而在另外一个kernel版本上运行,即便两个kernel版本中有些结构体有变化。而BTF(BPF Type Format) 是能让ebpf有这种强大兼容性的关键一环,使其能够实现CO-RE(complie once, run everywhere)。
CO-RE允许ebpf程序包含有关它们编译时使用的数据结构的布局,并提供了一种机制,用于调整当在不同机器上运行时,如果数据结构布局不一样,应当如何访问对应的字段。
在深入探讨 CO-RE 原理前,先看一下在此之前是如何解决可移植性的,以便了解 CO-RE 有什么突破性的技术
BCC的可移植性方案
BCC是一个早期实现的 ebpf 项目,它为用户空间和内核空间提供了一个相对容易访问的框架,对于没有太多内核经验的程序员来说非常有用。为了解决跨内核的可移植性问题,BCC实现了在目标机器上运行时编译 eBPF 代码的方法。这种方法存在一些问题:
- 需要在每个需要运行的机器上按钻过编译工具链和内核头文件(因为并不是所有机器都有完整的头文件)
- 在工具启动前,必须等待编译完成,这会导致每次启动工具时都会有几秒的延迟
- 如果在很多机器上运行,重复在每个机器上编译太浪费计算资源了
- 有些基于BCC的项目将 eBPF 代码和编译工具链打包在一份镜像文件中,以便更加容易在每个机器上运行。但这并不能确保头文件都存在,且如果每个机器上安装了多个这样的 BCC 容器,会导致更多的资源浪费
- 嵌入式设备可能没有足够的内存资源来执行这么复杂的编译步骤
基于这些问题,如果想要开发一个重要的 eBPF 项目,最好不要使用这种传统的 BCC 方法,尤其是如果需要将这个项目分发给其他人使用。
CO-RE 为 eBPF 程序的跨内核可移植性问题提供了更好的解决方案
CO-RE 概述
CO-RE 主要包含以下几个要素:
- BTF
BTF 是一种用于表达数据结构布局和函数签名的格式。在 CO-RE 中,它用于确定编译时和运行时所使用的数据结构之间的差异。同时它也被像 bpftool 这样的工具用来输出供人类可读的数据结构。Linux kernel 从 5.4 版本开始支持 BTF。 - 内核头文件
Linux kernel 的源码中包含了许多用于描述数据结构的头文件,这些头文件在不同内核版本间会有变化。eBPF 程序员可以选择包含单独的头文件,或者使用 bpftool 生成一个名为 vmlinux.h 的头文件,它包含了在运行时的系统中,该 BPF 程序所需的所有内核数据结构信息。 - 编译器支持
Clang 编译器使用 -g 选项编译 eBPF程序时,它会从 BTF 信息中派生出 CO-RE 重定位信息。 GCC 编译器在 12 版本开始支持 CO-RE。 - 支持数据结构重定位的库
在 eBPF 程序从用户空间加载进 kernel 的那一刻,CO-RE 会要求调整字节码以补偿 eBPF 程序在编译时和运行时数据结构的差异,这需要基于编译到对象中的 CO-RE 重定位信息。目前有几个库可以满足该需求:libbpf 是原始的 C 库,包含这种重定位能力;另外还有支持 GO 语言的 Cilium eBPF 库,以及支持 Rust 的 Aya。 - (可选)BPF 骨架( skeleton )
skeleton 可以从编译好的 BPF 对象文件中自动生成,它提供了用很多方便用户空间调用的辅助函数,可以用于管理 BPF 程序的生命周期、将 BPF 程序加载到内核中、附加到 内核事件上,等等。如果你需要用 C 语言写用户空间代码,可以通过bpftool gen skeleton生成skeleton。相较于使用底层库(libbpf、cilium、ebpf等)来说,这些高级抽象函数更利于开发者使用。
现在,你已经了解了 CO-RE 各关键元素的概述,接下来深入探索下他们是如何工作的,让我们先从 BTF 开始。
BPF Type Format
BTF 信息描述了数据结构和函数代码在内存中的布局情况,这个信息可以用于很多方面。
BTF 应用场景
利用 BTF 记录的信息,可以实现以下用途:
- 最重要的,有了编译时和运行时的数据结构信息,可以使程序在加载到内核时做适当的改变,来适配运行时的内核。
- 可以将字节码转换为人类可读的字符信息
- 由于保留了函数和行号信息,使得 bpftool 能够在翻译或 JIT 转储的输出中交替显示源码。方便进行字节码-源码的对照或日志-源码的对照。
使用 bpftool 列出 BTF 信息
可以用 bpftool btf list 来列出当前内核中加载的所有 BTF 数据:
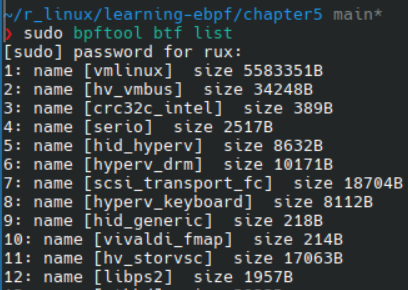
上图第一行 vmlinux 就是前面提到的包含了当前运行时内核的所有 BTF 信息。

当我们主动加载了一个名为 hello 的 eBPF 程序到内核中时,可以看到其 BTF 信息,各项信息解读如下:
- 这段 BTF 信息 ID 是 171(这个ID可用于后续索引,用于显示更加详细的信息)
- 这是一个大约2KB大小的匿名 BTF 信息块
- 这个 BTF 信息对应于 id 为 107 的 BPF 程序
- 这个 BTF 包含了 id 为37,34,36 三个 BPF map(map用于存储 BPF 程序所用到的各类信息,和其他语言中的map类似,也是用键值对来存储)
也可以用 bpftool prog show [id/name] 来显示更详细的信息

BTF Types
在知道 BTF 的 id 之后,可以通过bpftool btf dump id <id> 来获取其详细信息(输出结果很多,总共有44行,这里不一一列出):
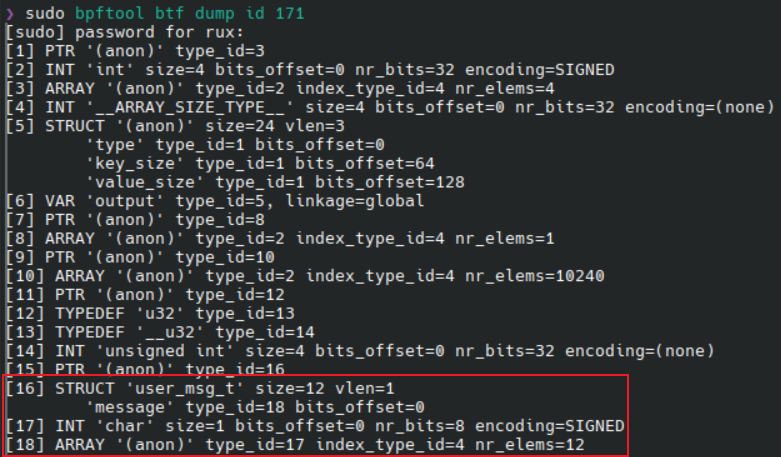
我们看标红这段:
第一列是type_id;第二列是类型,如struct、int、arrary、func等;
看type 16可以知道:
- 这是个名为user_msg_t的struct类型
- size=12:这个结构体总大小是12byte
- vlen=1:这个结构体共有一个成员
- 第一个成员(也是唯一的)是message,其类型是type 18,在结构体中的偏移是0(bits_offset=0)
type 18:
- ARRARY:这是一个数组;
- type_id=17:数组类型是type 17;
- 包含12个元素(nr_elems=12);
- 索引的类型是type 4
type 17:
- INT:是整数类型的,名为char;
- size=1:大小为1byte;
- bit_offset:偏移为0;
- nr_bits=8:大小为8bit;
- encoding=SIGNED:是有符号的
type 4:
同理,这是一个int类型的数据,大小为4byte
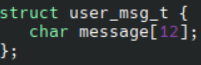
这个记录看起来很复杂,其实总结下来就是一个user_msg_t的结构体,里面有一个char类型的数组,包含12个元素。源码中就是这样写的:
函数和函数原型的 BTF type
前面举例说明了数据结构的 BTF type,下面看一下函数是如何记录 BTF 信息的。

这里表明,有一个名为hello的函数 BTF 类型是34,链接属性是global(相对的有static)。
type 34记录了函数原型,返回值为type 2,有一个参数,名为ctx,BTF type是21
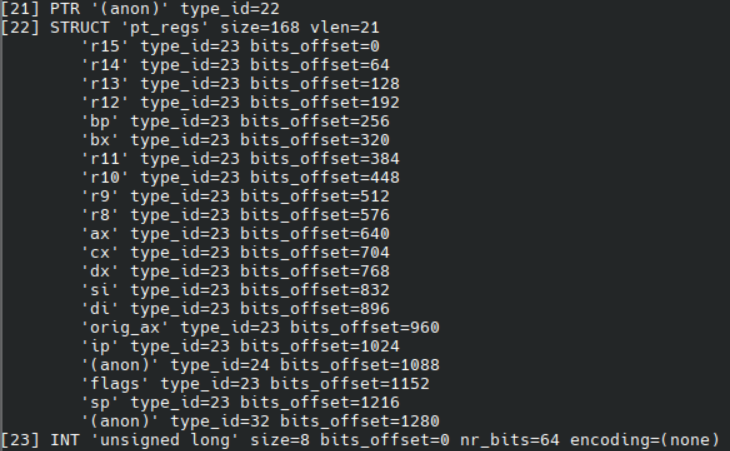
上图详细说明了参数 ctx 的类型,是一个pt_regs结构体,列出了其所有的成员
到此为止,我们已了解了内核是如何通过 BTF 来记录内核中的数据结构和函数的。
接下来看一下在程序中包含这些相关头文件有多简单。
生成内核头文件
通常我们写一个程序的时候需要包含所有需要用到的数据结构和定义相关函数的头文件,在 eBPF 中,这个事情变得非常简单。
前面提到,BTF 工具可以生成一个文件,包含当前内核中的所有数据结构和函数,这个函数一般命名为vmlinux.h。我们可以通过bpftool来手动生成它:
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
这个生成的文件就包含所有我们需要的信息了,例如前面提到的pt_regs:
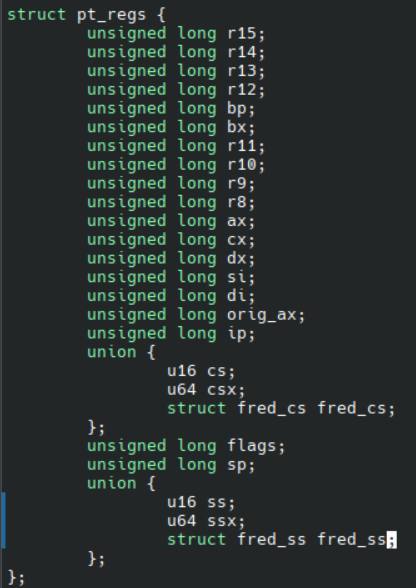
将这个头文件包含在 eBPF 程序的源码中,我们就得到了在编译时用到的所有数据结构和函数布局,当在目标机器上运行时,只需要和目标机器上的 vmlinux.h 进行对比,就知道两者的差异,对不同的部分进行调整就可以实现在不同机器上运行啦。
总结
本文主要介绍了 CO-RE 出现的背景和大致原理,并讲解了内核中如何通过 BTF 来记录所有的数据结构和函数原型信息。下篇文章将讲解如何使用 CO-RE 和 libbpf 来编写 eBPF 程序。
参考
Learning eBPF
BPF CO-RE (Compile Once – Run Everywhere)
BPF CO-RE reference guide
Building BPF applications with libbpf-bootstrap