不用训练,集成多个大模型产生更优秀的输出
论文标题
Collab: Controlled Decoding using Mixture of Agents for LLM Alignment
论文地址
https://arxiv.org/pdf/2503.21720
作者背景
JP摩根,马里兰大学帕克分校,普林斯顿大学
动机
大模型对齐(alignment)的主要目的是让模型输出更符合人类偏好或者业务需要,当前实现对齐的主流方案是RLHF,但不管是何种具体的实现都需要准备充足的训练数据,来训练调整模型参数,计算成本较大;
在高度专业化或者需要快速定制化的场景中,一般需要更轻量级的方法来实现业务对齐。此时不需要修改模型的受控解码便成为了更有前景的替代方案,它直接在推理阶段对模型的解码行为进行控制,以实现与目标偏好的对齐 。
相关研究表明,受控解码可以显著提高LLM满足特定需求的能力,甚至在某些场景下超过PPO/DPO(https://arxiv.org/pdf/2402.01694)
然而,现有受控解码方法大都针对于单一智能体,这在面对当下越来越多样化、可能有冲突的对齐需求时显得力不从心。例如,一方面我们可能希望模型叙事更严谨,另一方面又希望模型具有丰富的创造性;
尽管有些工作探索了集成多个智能体来应对上述挑战,但现有方法都依赖于弱监督或固定的公式来混合模型输出,缺乏灵活性并且可能需要额外的训练。
于是本文希望在不进行重新训练的情况下,设计一种推理时的动态解码机制,集成多个预训练好的LLMs,以实现最优的对齐效果
本文方法
作者提出Collab(基于混合agent的受控解码,Controlled decoding via mixture of agents),可以在token级别上动态选择最适合当前上下文的智能体来生成下一个词,这里的“智能体”指的就是已经预训练好,并且在特定任务或偏好上做了对齐的LLMs,如下图所示:
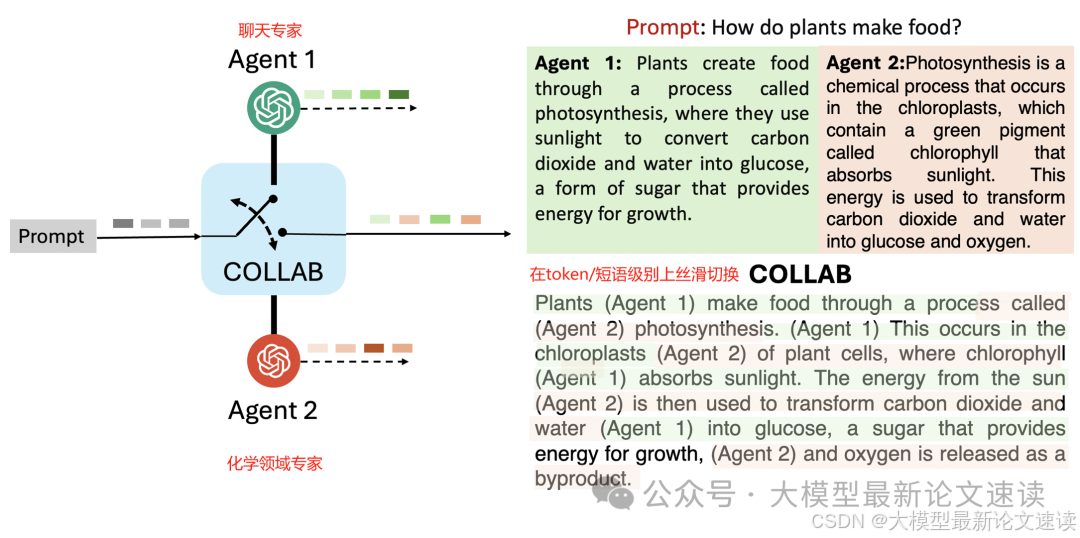
在token级别上选择合适的智能体,是一种奖励信号后置任务,可以使用Q-Learning等强化学习算法来解。为了实现上述“不重新训练”便恰当集成多个智能体的目标,作者从带KL正则项的强化学习(就是一般的RLHF)目标出发,尝试寻找出一个能够利用已知信息来近似Q函数的方法;
先说结论,作者找到的近似方法为:
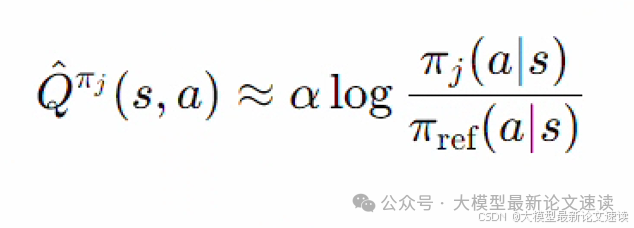
其中,Q(s, a)是在上下文状态为s的情况下,候选智能体π_j输出a的奖励期望;π_ref是参考模型,集成的结果不会过于偏离它。也就是说,Collab把【每个候选模型本身的输出概率分布,与参考模型分布的对数差】作为价值估计。更通俗地讲:相比于标准答案,每个“专家”提出的意见便是我们去咨询这个专家所获得的收益
获取到Q函数的估计结果后,便可以通过以下流程实现多LLMs的集成式解码:
- 在每个时间步,从每个模型中采样出top_p个token,使用预估的Q函数计算其奖励预期,
- 选择Q值最高的token作为当前解码结果,加入到上下文中,作为下一步解码的环境状态
- 重复上述过程,知道生成完整的响应
推导过程
一、近似Q函数推导
本节展示上述Q函数的估计过程,以及作者对其误差的估计。首先把问题建模为带KL正则项的强化学习:

其中参考模型使用的是Zephyr-7B-α、Starling-7B-α 等已经在通用文本任务上进行监督微调或RLHF的开源模型;
然后基于概率归一化条件(ΣΠ(a|s)=1),构造拉格朗日函数:
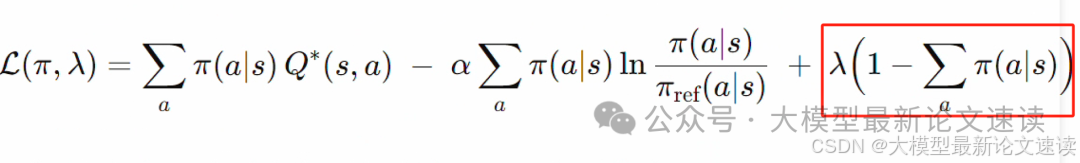
对策略概率Π(a|s)求偏导并令其为0,达到极值条件:

整理得到:
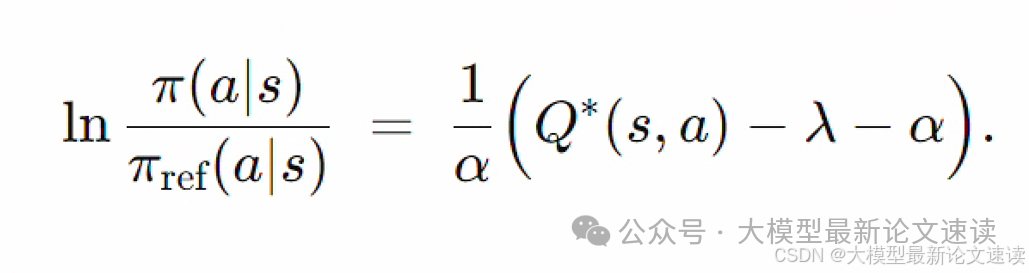
两边取指数:
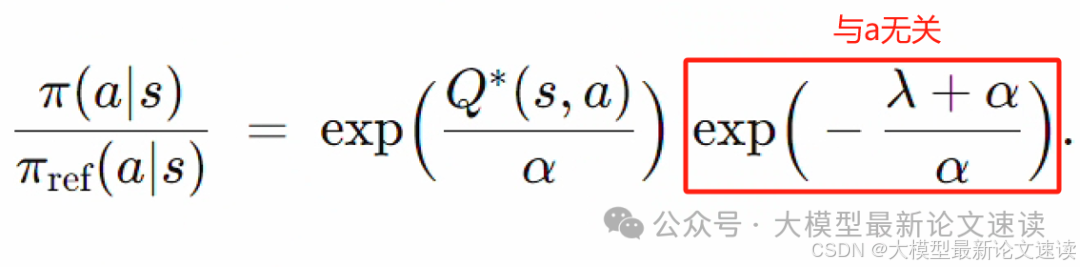
上面等式在Π(s, a)到达极小值时成立,即最优的策略模型,记为Π*;再把与a无关的项看成常数C,则可以解出最优Q函数:
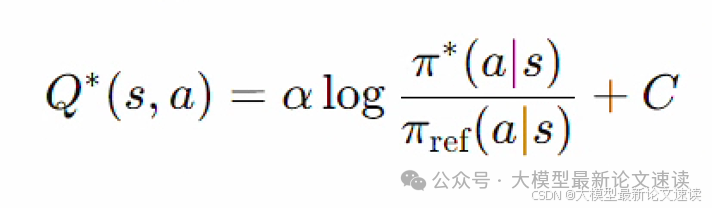
于是我们就找到了策略模型Π与价值函数Q的对应关系。但此时最优策略模型Π*是未知的,作者直接使用当前智能体Πj来代替Π*
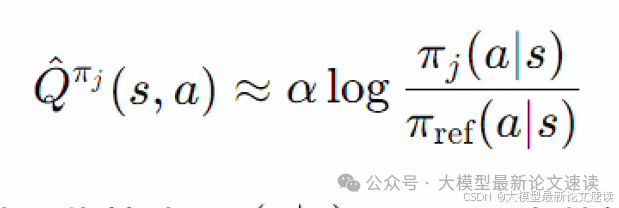
二、误差估计
使用当前候选智能体模型的分布Πj代替最优分布Π*带来了误差,具体可表示为:
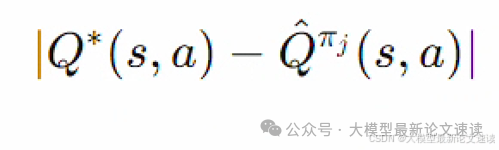
带入之前推导出来的Q与Π对应关系:
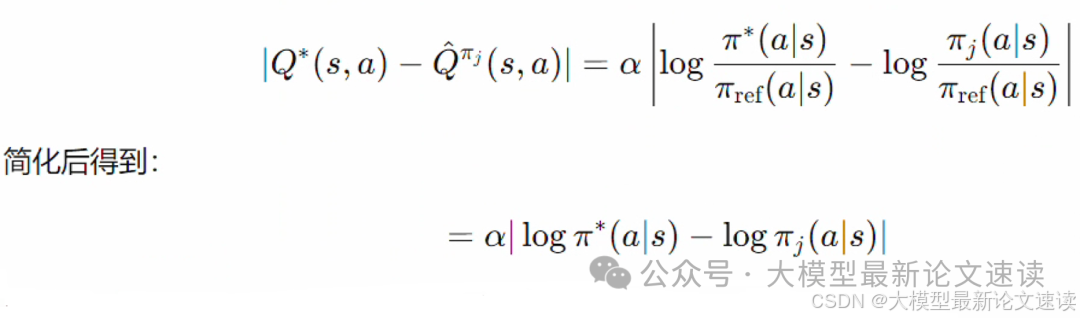
根据pinsker不等式与KL散度的定义,可推出:
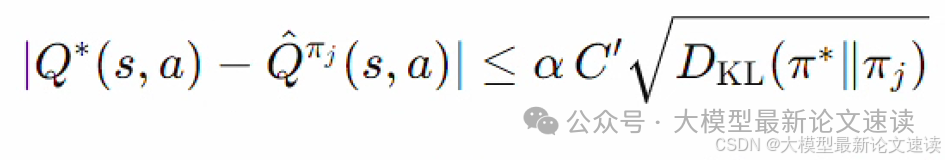
其中C’为某个有限的常数。也就是说,本文的Q函数估计方法,误差是有界的。如果Π*与Πj的差距不大,则估计的Q与最优的Q也很相近。
也就是说,如果我们的候选智能体本身都比较优秀、都经过了充分的训练与对齐,与目标策略差距不大(本文的动机确实也只是想结合不同的模型避免产生冲突),使用上述对数差来估计路由智能体的奖励是可靠的
实验结果
作者使用了市面上各种开源的,已经完成对齐训练的模型作为实验对象,在多轮对话与道德对齐数据集上进行测试,具体的实验设置如下:
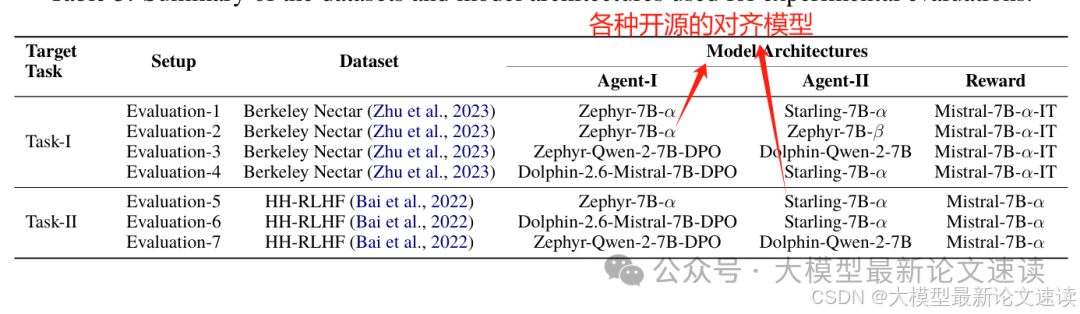
- Berkeley Nectar:多轮对话和问答数据集
- HH-RLHF:数据集对齐数据集
使用GPT-4作为裁判,本文提出的CoLLAB方法相较于对照组(参考上表)以及BoN采样的胜率:
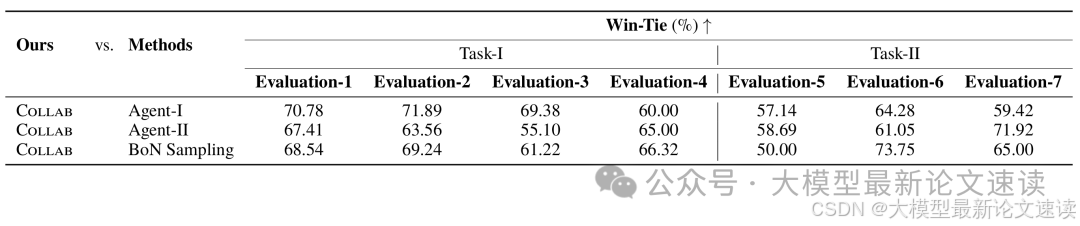
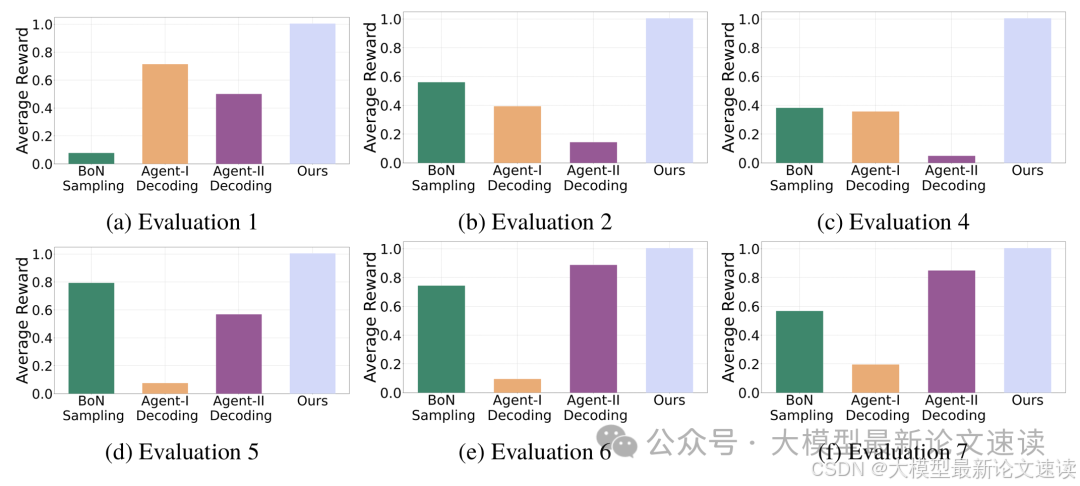
各对照组(参考上表)与实验组,在测试任务上的奖励分数对比:
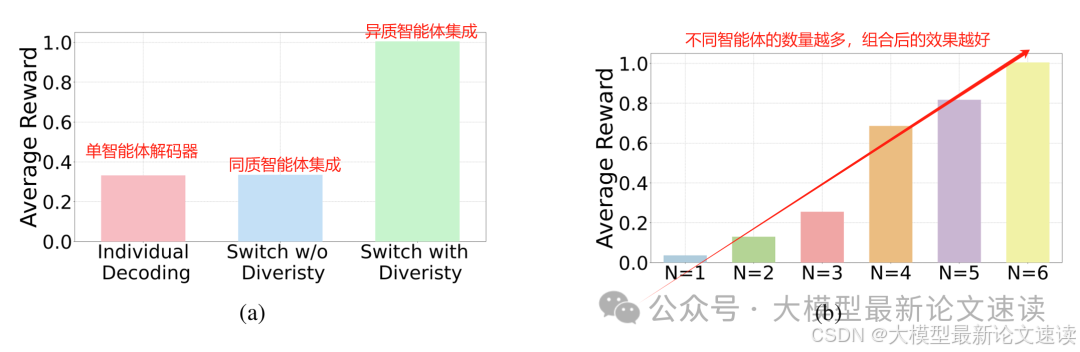
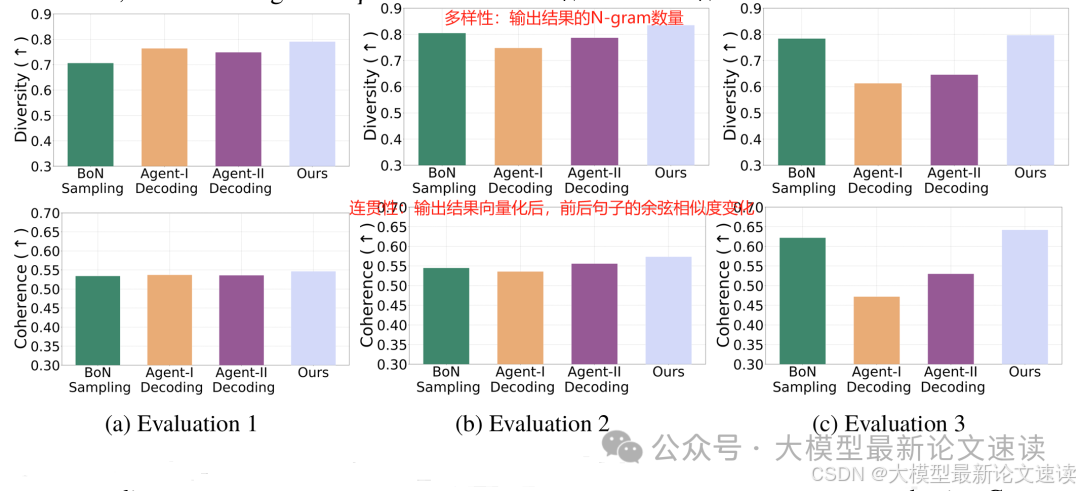
多样性与连贯性对比:
集成的智能体多样性越强效果越好: