利用CNN卷积神经网络进行声呐图像分类
笔者最近在系统性的学习当下AI最火的深度学习算法,在笔者询问了DeepSeek后,DeepSeek推荐了几本书籍,其中《深度学习:从基础到实践》(作者Andrew Glassner)这本数对笔者的帮助最大,该书分为上下两册,作者深入浅出的讲解了当下几乎所有门类的深度学习相关的知识。笔者也按照该书作者的建议把python也下载安装后学习了一遍,然后就按照书上给的python代码愉快的进行了编程学习。通过通读此书,原本在笔者心目中高大上的深度学习也变得不再神秘,曾经笔者觉得深度学习的部署需要计算能力很强的平台才行,经过学习后发现原来只是在训练的过程中才需要强大的算力,而在推理的过程中其实不需要很大的算力了,甚至于像stm32系列的单片机就可以轻松的运行参数量在百万规模神经网络,这样就解释了为什么DeepSeek在训练时需要5万多张H100,而在笔记本上就可以轻松部署一个参数量在1.5B的DeepSeek。
好了,说了这么多,接下来进入到今天的主题,笔者将使用一个CNN网络来进行声呐图像的分类识别,笔者利用先前笔者发布的成像声呐仿真软件生成了13种不同目标的360度旋转的图像,他们分别是立方体、轮胎、三角体、圆台、飞碟、超人、外星人、吉普车、古代帆船、波音747飞机、摩托车、卡车、跑车这13样目标。他们的点云图如下:
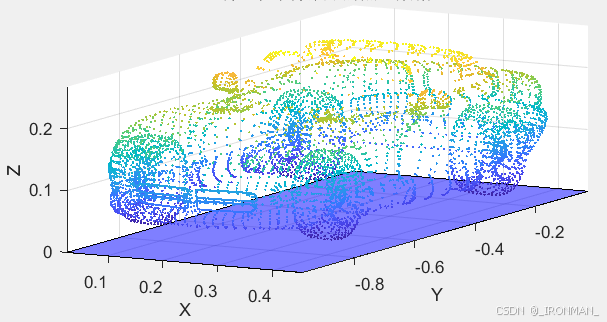
将他们分别导入到成像声呐仿真软件中,使用声呐不动目标运动模式进行仿真生成图片,这里笔者让每种目标旋转360度每0.2度生成一张图片,即每个目标可以生成1800张声呐图片,一共是23400张图片,其中随机选择18720张图片用于训练,剩余的用于测试,生成的声呐图片如下所示:
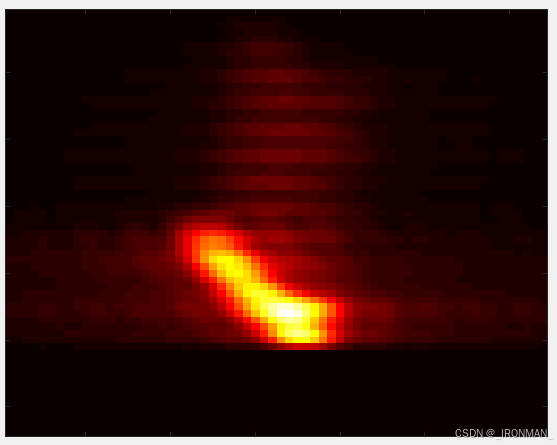

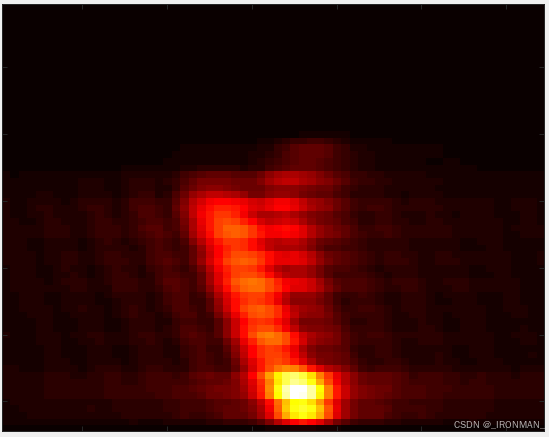










如果直接看成像图片人眼很难正确分辨,但是这难不倒神经网络!!!仿真软件的界面参数如下图所示:

笔者并不是直接用上述生成的图片进行处理的,而是对输出的数据截取了64x64大小的图片然后将其打包处理成神经网络能够处理的数据形式。好了先不多说了,直接放出python代码:
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.constraints import max_norm
from keras import backend as keras_backend
from keras.optimizers import Adam, SGD, RMSprop
# from keras.utils.np_utils import to_categorical
from keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import scipy.io as sio
random_seed = 42
np.random.seed(random_seed)
# 载入Sonar数据并保存尺寸
data_in = sio.loadmat('sonar_dataset_type13.mat') #载入.mat格式数据
print('import X_train shape:', data_in['X_train'].shape)
print('import y_train shape:', data_in['y_train'].shape)
print('import X_test shape:', data_in['X_test'].shape)
print('import y_test shape:', data_in['y_test'].shape)
X_train = data_in['X_train']
y_train = data_in['y_train']
X_test = data_in['X_test']
y_test = data_in['y_test']
image_height = X_train.shape[1]
image_width = X_train.shape[2]
number_of_pixels = image_height * image_width
# 将数据压缩至[0,1]范围
X_train = X_train*1.0/255.0
X_test = X_test*1.0/255.0
#存储原始的y_train和y_test
original_y_train = y_train
original_y_test = y_test
#将数据标签转换成独热码
number_of_classes = 1+max(np.append(y_train, y_test))
print(number_of_classes)
y_train = to_categorical(y_train, number_of_classes)
y_test = to_categorical(y_test, number_of_classes)
#将数据重塑成4D张量形式
X_train = X_train.reshape(X_train.shape[0], image_height,image_width,1)
X_test = X_test.reshape(X_test.shape[0], image_height,image_width,1)
def make_striding_cnn_model():
model = Sequential()
model.add(Conv2D(30,(5,5), activation='relu', padding='same', strides=(2,2),kernel_constraint=max_norm(3),input_shape=(image_height,image_width,1)))
model.add(Dropout(0.2))
model.add(Conv2D(16,(3,3), activation='relu', padding='same', strides=(2,2),kernel_constraint=max_norm(3)))
model.add(Dropout(0.2))
model.add(Conv2D(8,(3,3), activation='relu', padding='same', strides=(2,2),kernel_constraint=max_norm(3)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(64,activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(number_of_classes, activation='softmax')) #加入输出层,归一化指数输出,网络输出转换成概率
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
#生成网络
striding_cnn_model = make_striding_cnn_model()
striding_cnn_model.summary() #输出模型相关信息
#调用fit()训练模型并存储历史数据
striding_cnn_history = striding_cnn_model.fit(
X_train, y_train,validation_data=(X_test, y_test), epochs=100, batch_size=256, verbose=2) #训练epochs为100次,训练批次大小256
这里笔者要说明的是要想代码顺畅运行需要安装keras和tensorflow包,它们是开源的可以免费下载,直接pip install keras,即可自动安装,下面介绍一下代码的内容,首先是载入训练和测试数据,该数据可从这里13类目标图像声呐数据集下载,分别是X_train表示训练的图片大小是18720x64x64,y_train表示每种训练用的图片的标签大小是18720x1,取值为0~12,分别代表前面所说的13种目标。X_test表示测试用的图片,y_test表示测试用的图片对应的标签。
然后是搭建深度学习网络部分代码网络结构如下图:
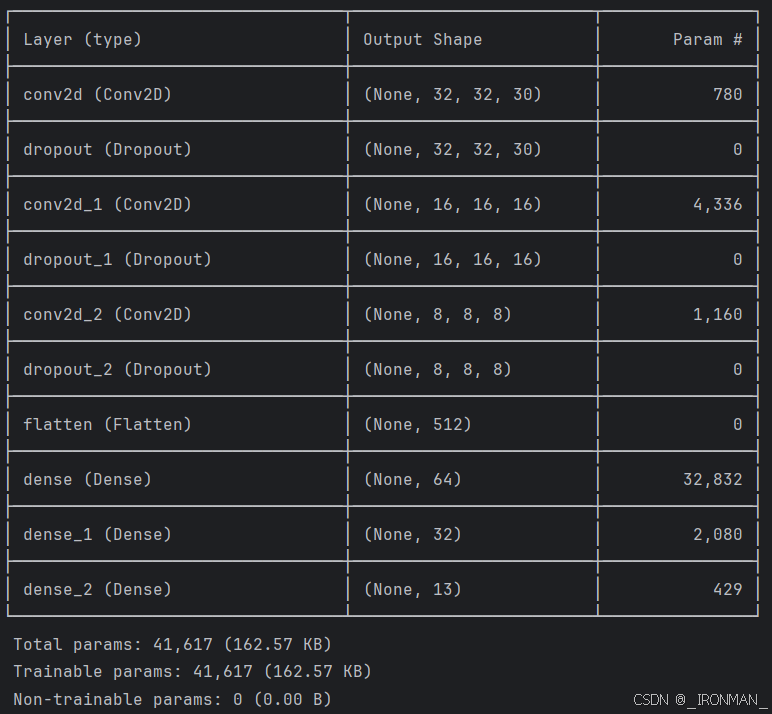
一共分为6层,前3层位卷积层,参数量分别为780,4336,1160、第4、5层为全连接层,参数量分别为32832,2080、最后一层为输出层参数量为429,一共有41617个训练参数,激活函数使用的是relu,其数学表达式为f(x)=max(0,x),当然还有其它的,如tanh等函数,损失函数使用的是交叉熵函数,还使用了dropout层,即在每次计算是随机屏蔽20%的权重,不参与计算,目的是为了防止过早出现过拟合,提高模型的泛化能力,输出层使用了softmax层,即柔性最大输出,保证输出的数值范围在0~1之间,对应的为每个类别的概率。最后就是训练模型,我们一共训练了100次,训练结果如下图所示:
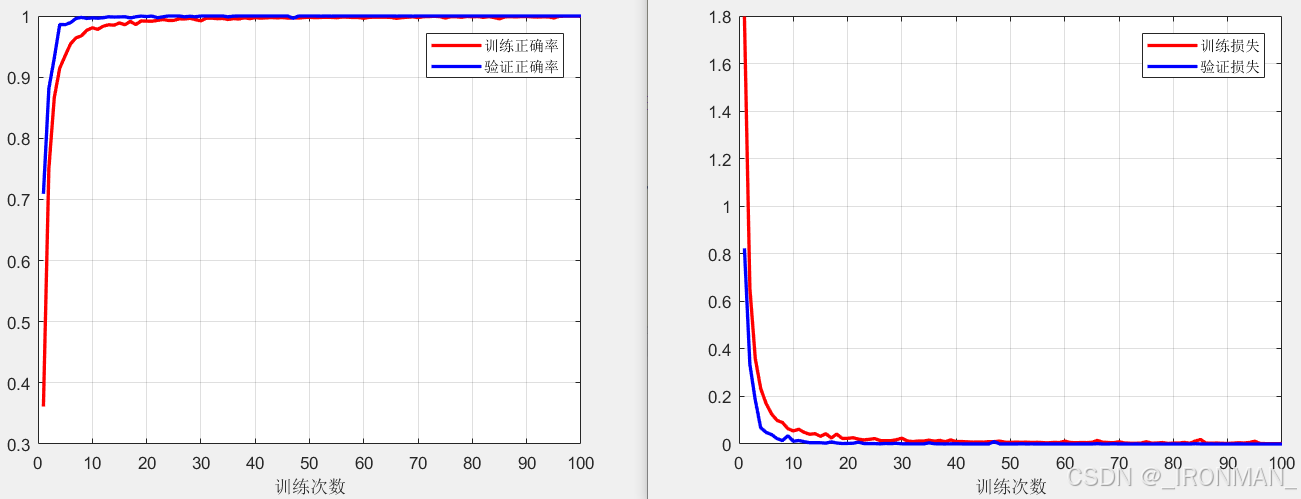
可以看到经过100次迭代后,无论是训练还是验证的正确率都是超过了99%,而训练和验证损失一直在下降,说明没有出现过拟合。是不是很神奇很强大!