【LLM】DeepResearch系列(Search-R1、Search-o1、R1-Searcher)
note
- DeepSearch 的核心理念是通过在搜索、阅读和推理三个环节中不断循环往复,直到找到最优答案。
- DeepResearch 的重心是撰写高质量、可读性强的长篇研究报告。这不仅仅是搜索信息,更是一项系统工程,需要整合有效的可视化元素(如图表、表格),采用合理的章节结构,确保子章节之间逻辑顺畅,全文术语一致,避免信息冗余,并运用流畅的过渡句衔接上下文。
文章目录
- note
- 一、DeepSearch
- 二、DeepResearch
- 三、DeepSearch 代码实现
- 四、Search-R1基于GRPO与PPO实现搜索强化
- 1. 训练数据
- 2. 奖励函数设计
- 3. 训练模型
- 4. 实现效果
- 五、Search-o1融合推理模型完成搜索增强
- 1. 架构设计架构
- 六、R1-Searcher两阶段强化学习方案
- 1、训练数据
- 2、训练方法
- 六、DeepResearcher开源模型
- 1、关于训练架构
- 2、关于训练数据
- 3、训练选型方面
- 六、AutoAgent
- 七、智谱autoglm模型
- Reference
一、DeepSearch
DeepSearch 的核心理念是通过在搜索、阅读和推理三个环节中不断循环往复,直到找到最优答案。 搜索环节利用搜索引擎探索互联网,而阅读环节则专注于对特定网页进行详尽的分析(例如使用 Jina Reader)。推理环节则负责评估当前的状态,并决定是应该将原始问题拆解为更小的子问题,还是尝试其他的搜索策略。
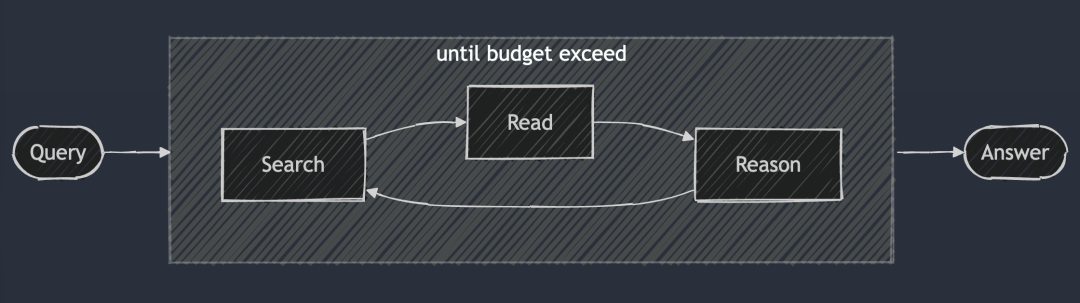
与 2024 年的 RAG 系统不同,RAG 一般只运行一次搜索-生成过程,DeepSearch 执行多次迭代,需要明确的停止条件。这些条件可以是基于 token 使用限制,或者失败尝试的次数。
二、DeepResearch
DeepSearch 是 DeepResearch 的构建模块,是后者赖以运转的核心引擎。
DeepResearch 的重心是撰写高质量、可读性强的长篇研究报告。这不仅仅是搜索信息,更是一项系统工程,需要整合有效的可视化元素(如图表、表格),采用合理的章节结构,确保子章节之间逻辑顺畅,全文术语一致,避免信息冗余,并运用流畅的过渡句衔接上下文。这些要素与底层的搜索功能并没有直接关联,因此我们更将 DeepSearch 作为公司(Jina)发展重点。
总结 DeepSearch 和 DeepResearch 的区别,详见下表。DeepSearch 和 DeepResearch 都离不开长上下文和推理模型,但原因略有不同。
DeepResearch 生成长报告需要长上下文,这很好理解。而 DeepSearch 虽然看起来是搜索工具,但为了规划后续操作,它也需要记住之前的搜索尝试和网页内容,所以长上下文同样不可或缺。

DeepResearch 是在 DeepSearch 的基础上,增加了一个结构化的框架,用于生成长篇的研究报告。它的工作流程一般从创建目录开始,然后系统性地将 DeepSearch 应用于报告的每一个所需部分:从引言到相关工作、再到方法论,直至最后的结论。报告的每个章节都是通过将特定的研究问题输入到 DeepSearch 中来生成的。最后将所有章节整合到一个提示词中,以提高报告整体叙述的连贯性。
三、DeepSearch 代码实现
开源链接:https://github.com/jina-ai/node-DeepResearch
DeepResearch 的核心在于其循环推理机制。与大多数 RAG 系统试图一步到位地回答问题不同,我们采用了一种迭代循环的方式。它会持续搜索信息、阅读相关来源并进行推理,直到找到答案或耗尽 token 预算。
以下是这个大型 while 循环的精简骨架:
// 主推理循环
while (tokenUsage < tokenBudget && badAttempts <= maxBadAttempts) {
// 追踪进度
step++; totalStep++;
// 从 gaps 队列中获取当前问题,如果没有则使用原始问题
const currentQuestion = gaps.length > 0 ? gaps.shift() : question;
// 根据当前上下文和允许的操作生成提示词
system = getPrompt(diaryContext, allQuestions, allKeywords,
allowReflect, allowAnswer, allowRead, allowSearch, allowCoding,
badContext, allKnowledge, unvisitedURLs);
// 让 LLM 决定下一步行动
const result = await LLM.generateStructuredResponse(system, messages, schema);
thisStep = result.object;
// 执行所选的行动(回答、反思、搜索、访问、编码)
if (thisStep.action === 'answer') {
// 处理回答行动...
} else if (thisStep.action === 'reflect') {
// 处理反思行动...
} // ... 其他行动依此类推
}
为了保证输出的稳定性和结构化,我们采取了一个关键措施:在每个步骤中,有选择地禁用某些操作。
比如,当内存里没有 URL 时,我们会禁止 “visit” 操作;如果上次的回答被拒绝,我们会阻止 Agent 立即重复 “answer” 操作。这种约束机制能引导 Agent 沿着正确的方向前进,避免在原地打转。
参考:DeepSearch 与 DeepResearch 的设计和实现
四、Search-R1基于GRPO与PPO实现搜索强化
仓库:https://github.com/PeterGriffinJin/Search-R1
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning(Search-R1:利用强化学习训练LLM进行推理并利用搜索引擎)。这篇文章是关于如何训练大型语言模型(LLMs)有效地利用搜索引擎来增强其推理和文本生成能力。
核心创新:允许LLM在推理过程中自主决定何时以及如何进行搜索。
论文提出了一个名为SEARCH-R1的框架,该框架仅仅通过强化学习(RL)让LLM学习如何在逐步推理过程中自主生成搜索查询并与实时检索交互。
该方法特点总结如下:
1)使用检索token mask技术稳定RL训练,
2)支持多轮交错推理和搜索,以支持复杂的任务解决,
3)设计了一个简单而有效的基于结果的奖励函数。通过在七个问答数据集上的实验,SEARCH-R1在三个LLM上实现了相对于SOTA基线的显著性能提升。
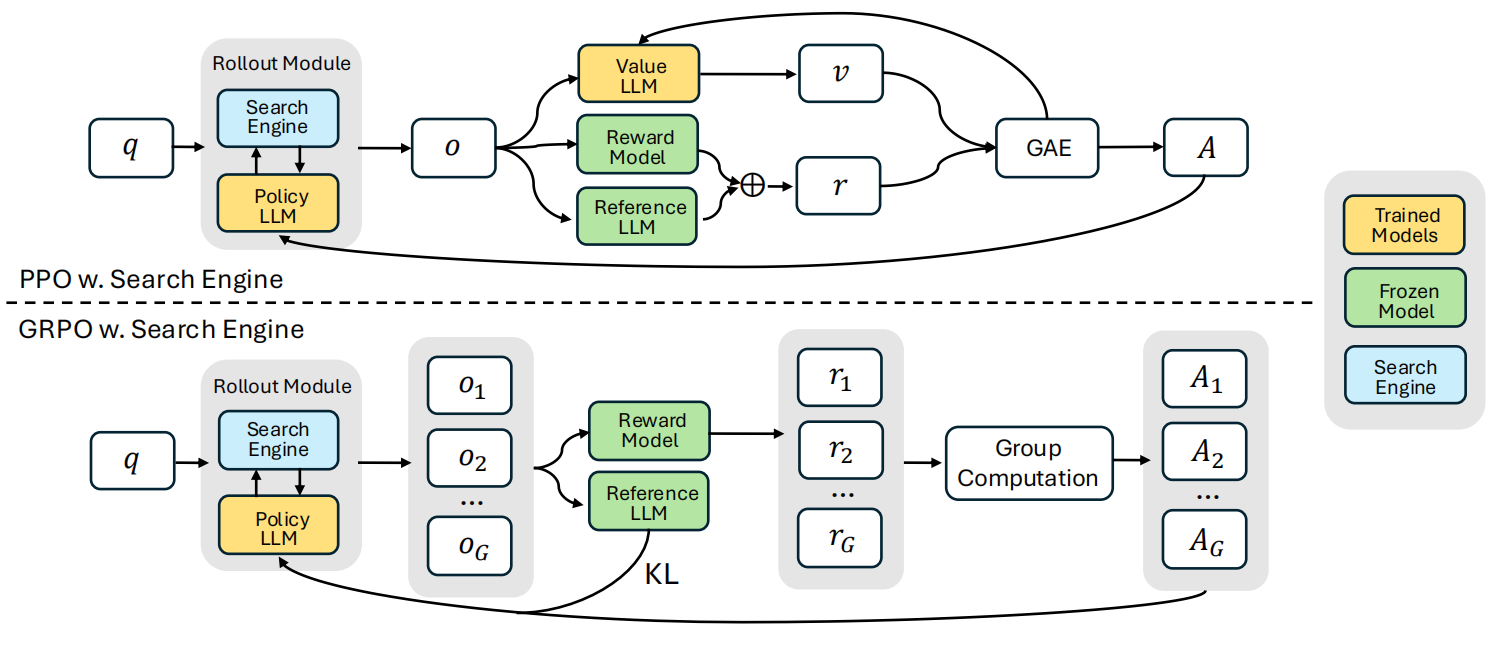
1. 训练数据
训练数据模版设计上,该模板以迭代的方式将模型的输出结构化为三个部分:首先是推理过程,然后是搜索引擎调用功能,最后是答案。通过特殊token<search>和</search>触发搜索,<information>和</information>包含检索到的内容,<think>和</think>包含推理步骤,<answer>和</answer>包含最终答案。

2. 奖励函数设计
采用了一个基于规则的奖励系统,该系统仅由最终结果奖励组成,这些奖励评估模型响应的正确性。例如,在事实推理任务中,正确性可以使用基于规则的标准来评估,如精确字符串匹配。不纳入格式奖励。强化学习算法上,兼容PPO和GRPO等多种RL算法。
强化学习算法上,兼容PPO和GRPO等多种RL算法。在训练时,使用检索token掩码(retrieved tokenmasking)来保证训练的稳定性,仅对LLM生成的token计算损失,排除检索内容。
3. 训练模型
训练模型上,使用三种类型的模型:Qwen-2.5-3B(Base/Instruct)和Qwen-2.5-7B(Base/Instruct)以及Llama-3.2-3B(Base/Instruct)。检索使用2018年维基百科转储作为知识源和E5作为检索器。训练时,将所有检索方法的检索段落数设置为三个。
4. 实现效果

五、Search-o1融合推理模型完成搜索增强
Search-o1《Search-o1: Agentic Search-Enhanced Large Reasoning Models》
(https://arxiv.org/pdf/2501.05366,
https://search-o1.github.io/,
https://github.com/sunnynexus/Search-o1)
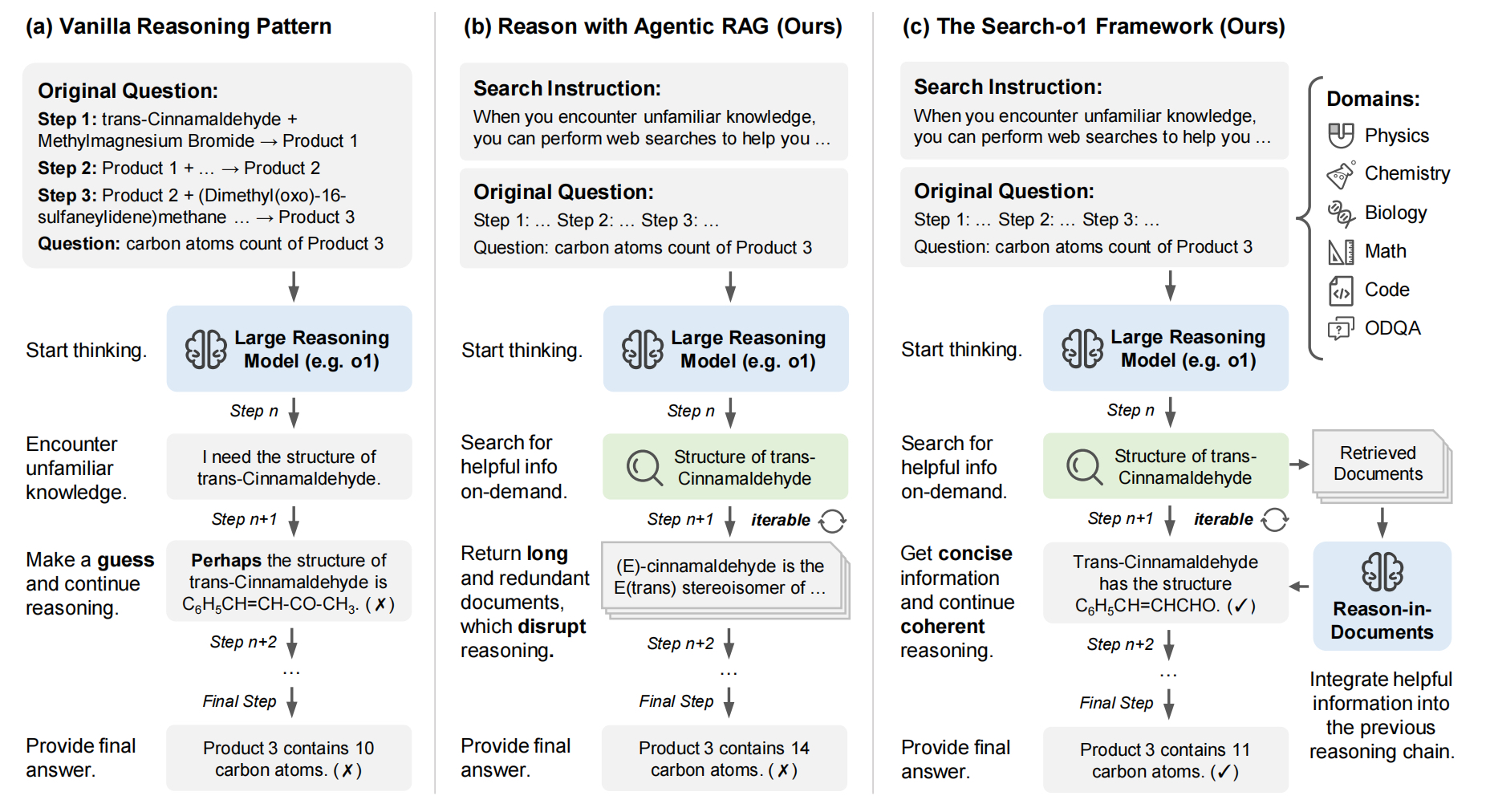
检索到的文档通常篇幅较长且包含冗余信息,直接将其输入到LRM可能会干扰原有的推理连贯性,甚至引入噪声。大多数LRM在预训练和微调阶段已被特别对齐,以适应复杂推理任务。这种关注导致他们在一般能力上出现了某种程度的灾难性遗忘,最终限制了他们对检索到的文档的长上下文理解。
1. 架构设计架构
包括代理RAG机制以及文档内推理模块(Reason-in-Documents)两种。
六、R1-Searcher两阶段强化学习方案
仓库:https://github.com/RUCAIBox/R1-Searcher
关于两阶段的强化学习方案,R1-Searcher《R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning》,https://arxiv.org/pdf/2503.05592
第一阶段专注于让模型学会如何正确地发起检索请求;
第二阶段则让模型学会在真正回答问题时有效利用检索结果。
1、训练数据
在训练数据集上,选用多跳问答数据集HotpotQA 和2WikiMultiHopQA进行训练。通过初步的推理尝试把问题按解题难度(需要检索次数)分为轻松、中等、困难三类。

2、训练方法
在训练方法上,分成两个阶段。两阶段的奖励设计,在第一阶段快速让模型学会正确地调用检索接口并遵循输出格式,第二阶段再综合考察答案准确度,使得模型对检索信息的使用更有效,从而提升整体问答质量。
拆开来看:
(1)阶段一只关注检索行为,给检索次数和输出格式设定正奖励或零奖励。
检索奖励上,令n表示推理过程中检索调用(即发起检索请求)的次数,如果模型在一次完整推理中至少调用了1次检索接口,则奖励为0.5,否则奖励为0。
格式奖励上,为了确保输出格式符合要求(例如正确使用…、…以及 <|begin_of_query|>…</|end_of_query|> 标签),我们设定一个格式奖励:若模型输出符合所有格式规范,则奖励 0.5,否则为0。此阶段并不评价答案本身是否正确,因此在阶段一中没有针对答案准确度的奖励项。最终的阶段一总奖励为以上两项之和。
(2)第二阶段的目标是让模型有效利用检索结果来回答问题。此时的奖励包括答案奖励和格式奖励。
答案奖励,使用答案与标注答案的F1分数作为奖励,若预测答案与真实答案越吻合,F1得分越高,模型获得的奖励也越高。格式奖励也是奖励格式是否满足要求。
六、DeepResearcher开源模型
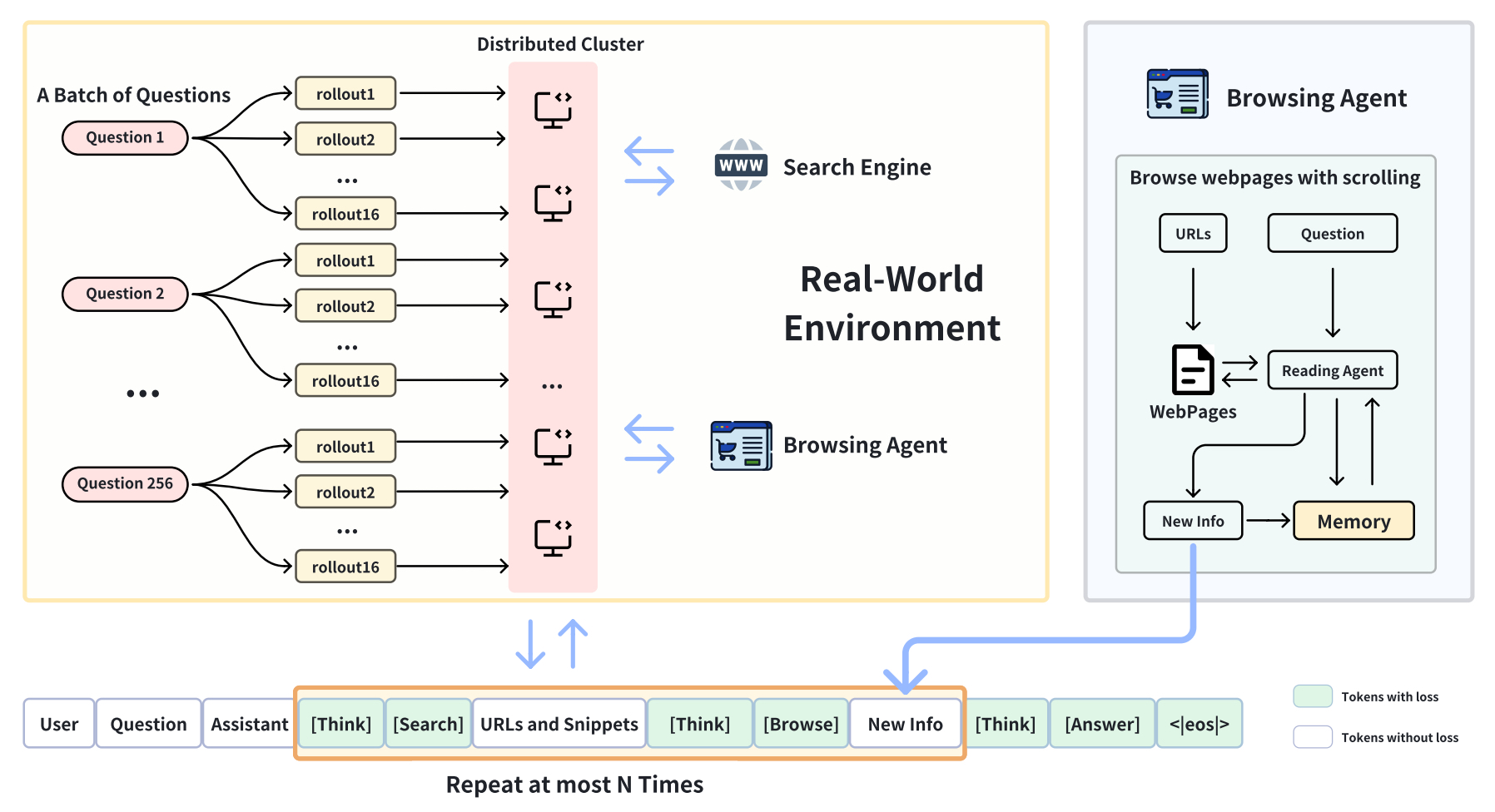
《DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments》,https://github.com/GAIR-NLP/DeepResearcher/blob/main/resources/DeepResearcher.pdf,通过在真实环境中扩展强化学习(RL,GRPO)来实现基于LLM的DeepResearcher的端到端训练。
代码地址在https://github.com/GAIR-NLP/DeepResearcher
模型地址在https://huggingface.co/GAIR/DeepResearcher-7b
考虑到与受控的RAG(检索增强生成)环境不同,实际的网络搜索呈现出嘈杂、非结构化且异构的信息源,需要复杂的过滤和相关性评估能力。所以,与基于提示和SFT的方法不同,仅使用结果奖励直接扩展深度研究的强化学习训练。
1、关于训练架构
推理部分,限制深度研究者在采取行动之前进行推理。每个推理过程都用一个<思考>标签包裹起来,遵循DeepSeek-R1的设置。
网络搜索部分,通过生成一个JSON格式的请求来调用网络搜索工具,该请求包含工具名称web_search和作为参数的搜索查询。搜索结果以结构化格式返回,包括每个网页的标题、URL和内容摘要。当前实现采用固定的前K个(例如,10个)值来检索搜索结果。
网页浏览代理部分,代理为每个查询维护一个短期记忆库。在接收到网页浏览请求后,它会处理请求中URL的第一页段。随后,网页浏览代理根据查询、历史记忆和新获取的网页内容采取两个行动:
(1)确定是继续阅读下一个URL/段还是停止,
(2)将相关信息追加到短期记忆中。一旦代理决定停止进一步浏览,它会将所有新添加的信息从短期记忆中编译并返回。
2、关于训练数据
在训练数据上,利用现有的开放领域问答数据集,这些数据集包含从单跳到多跳的问题,这些问题本质上需要在线搜索以找到准确的答案。训练语料库包括一系列需要不同。所以,具体使用NaturalQuestions(NQ)和TriviaQA(TQ)来处理单跳场景,通常答案可以在单个网页文档中找到。对于需要跨多个来源整合信息的更复杂的多跳场景,纳入了HotpotQA和2WikiMultiHopQA(2Wiki)的例子,这两个例子都是专门设计来评估多步骤推理能力的。
为了防止污染,先进行低质量问题过滤Low-Quality Question Filtering,具体提示DeepSeek-R1排除那些可能产生不可靠或有问题搜索结果的问题,如剔除:时效性问题(例如,“苹果公司现任CEO是谁?”)、高度主观的问题(例如,“最好的智能手机是什么?”)以及潜在有害或违反政策的内容。
为了确保模型真正学会使用搜索工具而不是死记硬背答案,采用了污染检测Contamination Detection。对于每个候选问题,从训练中将使用的基模型中随机抽取10个响应,并检查是否有任何响应包含正确答案(即,准确率@10)。如果模型在未经搜索的情况下就表现出先验知识(即,直接给出正确答案),则将其排除在训练集之外。
3、训练选型方面
采用Qwen2.5-7B-Instruct作为训练流程的主干模型。训练使用Verl框架进行。在每个训练步骤中,采样256个提示,并对每个提示采样16次展开。每次展开包括最多10次工具调用,然后是最终答案步骤。训练方法上,利用强化学习(RL)来训练智能体,具体采用群体相对策略优化(GRPO)算法,由于使用的是包含短答案真实标签的开放领域问答数据集,所以在奖励函数上包括格式惩罚和F1奖励。
格式惩罚(如果格式不正确(例如,缺少标签或结构错误),代理将受到-1的惩罚)和F1奖励(如果格式正确,奖励基于词级F1分数,该分数衡量生成的答案与参考答案相比的准确性。更高的F1分数带来更高的奖励)。
六、AutoAgent
智能搜索:自动搜索网络信息,整合分析内容
自动编程:能处理各种复杂的编程任务
数据分析:进行深入的数据挖掘和分析
智能报告:生成可视化报告
参考:一句话全自动创建AI智能体,港大AutoAgent打造开源最强Deep Research
七、智谱autoglm模型
https://autoglm-research.zhipuai.cn/
Reference
[1] Search-R1:让大模型学会“检索+推理”的新范式
[2] DeepSearch 与 DeepResearch 的设计和实现
[3] A Visual Guide to LLM Agents:https://substack.com/home/post/p-156659273
[4] Search-o1《Search-o1: Agentic Search-Enhanced Large Reasoning Models》(https://arxiv.org/pdf/2501.05366,https://search-o1.github.io/,https://github.com/sunnynexus/Search-o1)
[5] R1-Searcher《R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning》,https://arxiv.org/pdf/2503.05592