# 深入了解fasttext
深入解析FastText:高效文本分类与词向量训练工具
引言
在自然语言处理(NLP)领域,FastText 是一个经典且高效的工具包,由Facebook AI Research(FAIR)开发。它以快速训练和预测能力著称,尤其在文本分类和词向量生成任务中表现优异。本文将从核心概念、模型架构、优缺点及实际应用等方面,全面解析FastText的原理与使用。

1. FastText概述
1.1 什么是FastText?
FastText是基于Word2Vec的改进模型,通过引入子词(Subword)信息,解决了传统词向量无法处理未登录词(OOV)的问题。它支持两大核心任务:
- 文本分类:快速构建分类模型(如情感分析、新闻分类)。
- 词向量训练:生成包含语义和形态信息的词向量。
1.2 核心优势
- 速度:利用层次化Softmax和负采样技术,训练速度极快。
- 可扩展性:支持大规模数据集(百万级文本)。
- 鲁棒性:通过子词信息处理未登录词,提升模型泛化能力。
2. 核心概念详解
2.1 子词信息(Subword Representation)
FastText将单词分解为字符级n-gram。例如,单词"apple"在n=3时生成以下子词:
<ap, app, ppl, ple, le>
- 符号含义:
<和>表示词边界,区分前缀和后缀。 - 向量生成:每个子词独立学习向量,单词向量为所有子词向量的平均值。
2.2 层次化Softmax(Hierarchical Softmax)
传统Softmax在大规模词汇表中计算成本高(复杂度O(V))。层次化Softmax通过构建霍夫曼树优化计算:
- 树形结构:高频词靠近根节点,路径更短。
- 概率计算:通过路径上的二分类节点(Sigmoid)概率相乘,复杂度降至O(logV)。
2.3 负采样(Negative Sampling)
负采样通过简化目标函数加速训练:
- 核心思想:将多分类问题转为二分类(区分正样本与负样本)。
- 实现方式:仅更新正样本和少量负样本的参数,而非整个词汇表。
- 优势:计算复杂度从O(V)降至O(k)(k为负样本数,通常取5-20)。
3. 模型架构
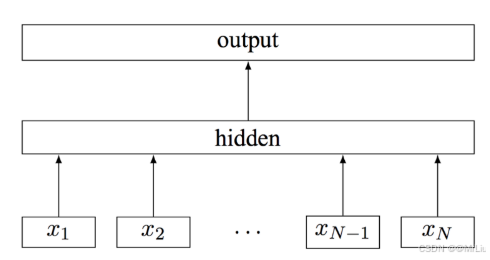
FastText的模型架构分为三层:
- 输入层:文本的词向量或子词向量表示。
- 隐藏层:对输入向量求平均(Bag of Words思想)。
- 输出层:通过层次化Softmax或负采样生成分类结果或词向量。
3.1 训练模式
- Skip-gram模式:通过中心词预测上下文词。
- CBOW模式:通过上下文词预测中心词。
4. 优缺点分析
4.1 优点
- 高效性:适合工业级大规模数据,分钟级训练百万文本。
- 鲁棒性:子词信息有效解决未登录词问题。
- 轻量级:模型结构简单,易于部署。
4.2 缺点
- 忽略词序:基于词袋模型,无法捕捉序列信息。
- 数据依赖:需要大量数据才能发挥优势。
- 短文本局限:对短文本(如推文)效果可能不如深度模型。
5. 应用场景
5.1 文本分类
- 案例:情感分析、垃圾邮件检测。
- 代码示例:
import fasttext # 训练分类模型 model = fasttext.train_supervised(input="train.txt", epoch=25, lr=0.5) # 预测 model.predict("This is a positive review.")
5.2 词向量训练
- 案例:生成领域特定词向量,用于下游任务(如命名实体识别)。
- 代码示例:
model = fasttext.train_unsupervised("corpus.txt", model='skipgram') # 获取词向量 vector = model.get_word_vector("example")
6. 安装与使用
6.1 安装
pip install fasttext
6.2 数据格式
- 分类任务:每行格式为
__label__类别 文本内容。__label__sports 篮球比赛今晚开始 __label__tech 新款手机发布
7. 总结
FastText凭借其高效性和鲁棒性,成为NLP工具包中的“瑞士军刀”。尽管存在忽略词序等局限,但在资源有限或需要快速迭代的场景中,它仍是理想选择。未来,结合深度学习模型(如BERT)的混合架构可能进一步提升其性能。
参考资料:FastText官方文档
代码仓库:GitHub项目地址
通过本文,您应能掌握FastText的核心原理与应用方法。无论是处理大规模文本分类,还是生成高质量词向量,FastText都是一个值得尝试的工具!