深度学习处理文本(10)
保存自定义层
在编写自定义层时,一定要实现get_config()方法:这样我们可以利用config字典将该层重新实例化,这对保存和加载模型很有用。该方法返回一个Python字典,其中包含用于创建该层的构造函数的参数值。所有Keras层都可以被序列化(serialize)和反序列化(deserialize),如下所示。
config = layer.get_config()
new_layer = layer.__class__.from_config(config) ←---- config不包含权重值,因此该层的所有权重都是从头初始化的
来看下面这个例子。
layer = PositionalEmbedding(sequence_length, input_dim, output_dim)
config = layer.get_config()
new_layer = PositionalEmbedding.from_config(config)
在保存包含自定义层的模型时,保存文件中会包含这些config字典。从文件中加载模型时,你应该在加载过程中提供自定义层的类,以便其理解config对象,如下所示。
model = keras.models.load_model(
filename, custom_objects={"PositionalEmbedding": PositionalEmbedding})
你会注意到,这里使用的规范化层并不是之前在图像模型中使用的BatchNormalization层。这是因为BatchNormalization层处理序列数据的效果并不好。相反,我们使用的是LayerNormalization层,它对每个序列分别进行规范化,与批量中的其他序列无关。它类似NumPy的伪代码如下
def layer_normalization(batch_of_sequences): ←----输入形状:(batch_size, sequence_length, embedding_dim)
mean = np.mean(batch_of_sequences, keepdims=True, axis=-1) ←---- (本行及以下1行)计算均值和方差,仅在最后一个轴(−1轴)上汇聚数据
variance = np.var(batch_of_sequences, keepdims=True, axis=-1)
return (batch_of_sequences - mean) / variance
下面是训练过程中的BatchNormalization的伪代码,你可以将二者对比一下。
def batch_normalization(batch_of_images): ←----输入形状:(batch_size, height, width, channels)
mean = np.mean(batch_of_images, keepdims=True, axis=(0, 1, 2)) ←---- (本行及以下1行)在批量轴(0轴)上汇聚数据,这会在一个批量的样本之间形成相互作用
variance = np.var(batch_of_images, keepdims=True, axis=(0, 1, 2))
return (batch_of_images - mean) / variance
BatchNormalization层从多个样本中收集信息,以获得特征均值和方差的准确统计信息,而LayerNormalization层则分别汇聚每个序列中的数据,更适用于序列数据。我们已经实现了TransformerEncoder,下面可以用它来构建一个文本分类模型,如代码清单11-22所示,它与前面的基于GRU的模型类似。代码清单11-22 将Transformer编码器用于文本分类
vocab_size = 20000
embed_dim = 256
num_heads = 2
dense_dim = 32
inputs = keras.Input(shape=(None,), dtype="int64")
x = layers.Embedding(vocab_size, embed_dim)(inputs)
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
x = layers.GlobalMaxPooling1D()(x) ←---- TransformerEncoder返回的是完整序列,所以我们需要用全局汇聚层将每个序列转换为单个向量,以便进行分类
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()
我们来训练这个模型,如代码清单11-23所示。模型的测试精度为87.5%,比GRU模型略低。代码清单11-23 训练并评估基于Transformer编码器的模型
callbacks = [
keras.callbacks.ModelCheckpoint("transformer_encoder.keras",
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=20,
callbacks=callbacks)
model = keras.models.load_model(
"transformer_encoder.keras",
custom_objects={"TransformerEncoder": TransformerEncoder}) ←----在模型加载过程中提供自定义的TransformerEncoder类
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")
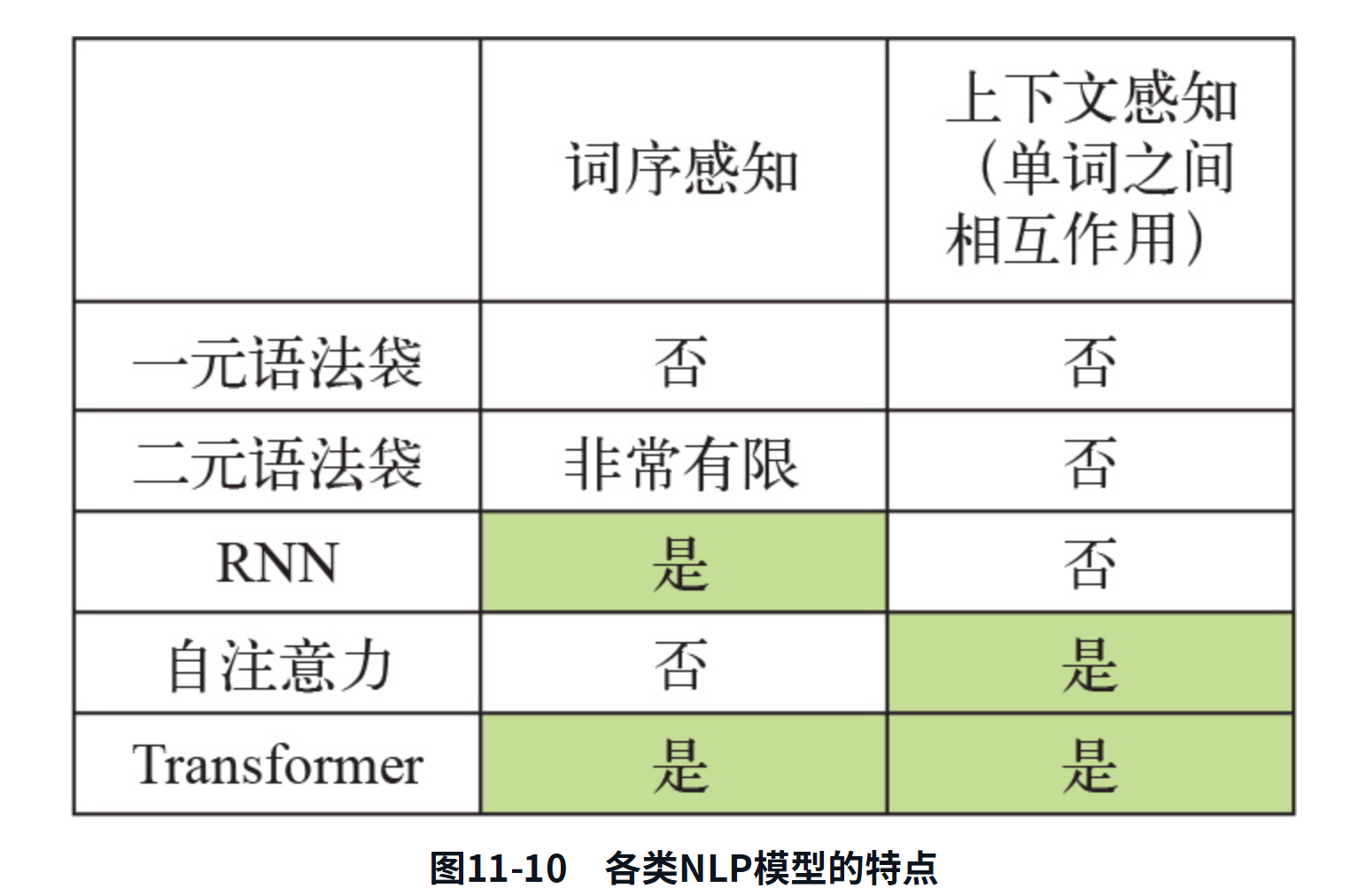
现在你应该已经开始感到有些不对劲了。你能看出是哪里不对劲吗?本节的主题是“序列模型”。我一开始就强调了词序的重要性。我说过,Transformer是一种序列处理架构,最初是为机器翻译而开发的。然而……你刚刚见到的Transformer编码器根本就不是一个序列模型。你注意到了吗?它由密集层和注意力层组成,前者独立处理序列中的词元,后者则将词元视为一个集合。你可以改变序列中的词元顺序,并得到完全相同的成对注意力分数和完全相同的上下文感知表示。如果将每篇影评中的单词完全打乱,模型也不会注意到,得到的精度也完全相同。自注意力是一种集合处理机制,它关注的是序列元素对之间的关系,如图11-10所示,它并不知道这些元素出现在序列的开头、结尾还是中间。既然是这样,为什么说Transformer是序列模型呢?如果它不查看词序,又怎么能很好地进行机器翻译呢?
Transformer是一种混合方法,它在技术上是不考虑顺序的,但将顺序信息手动注入数据表示中。这就是缺失的那部分,它叫作位置编码(positional encoding)。我们来看一下。
使用位置编码重新注入顺序信息
位置编码背后的想法非常简单:为了让模型获取词序信息,我们将每个单词在句子中的位置添加到词嵌入中。这样一来,输入词嵌入将包含两部分:普通的词向量,它表示与上下文无关的单词;位置向量,它表示该单词在当前句子中的位置。我们希望模型能够充分利用这一额外信息。你能想到的最简单的方法就是将单词位置与它的嵌入向量拼接在一起。你可以向这个向量添加一个“位置”轴。在该轴上,序列中的第一个单词对应的元素为0,第二个单词为1,以此类推。然而,这种做法可能并不理想,因为位置可能是非常大的整数,这会破坏嵌入向量的取值范围。如你所知,神经网络不喜欢非常大的输入值或离散的输入分布。
在“Attention Is All You Need”这篇原始论文中,作者使用了一个有趣的技巧来编码单词位置:将词嵌入加上一个向量,这个向量的取值范围是[-1, 1],取值根据位置的不同而周期性变化(利用余弦函数来实现)。这个技巧提供了一种思路,通过一个小数值向量来唯一地描述较大范围内的任意整数。这种做法很聪明,但并不是本例中要用的。我们的方法更加简单,也更加有效:我们将学习位置嵌入向量,其学习方式与学习嵌入词索引相同。然后,我们将位置嵌入与相应的词嵌入相加,得到位置感知的词嵌入。这种方法叫作位置嵌入(positional embedding)。我们来实现这种方法,如代码清单11-24所示。代码清单11-24 将位置嵌入实现为Layer子类
class PositionalEmbedding(layers.Layer):
def __init__(self, sequence_length, input_dim, output_dim, **kwargs): ←----位置嵌入的一个缺点是,需要事先知道序列长度
super().__init__(**kwargs)
self.token_embeddings = layers.Embedding( ←----准备一个Embedding层,用于保存词元索引
input_dim=input_dim, output_dim=output_dim)
self.position_embeddings = layers.Embedding(
input_dim=sequence_length, output_dim=output_dim) ←----另准备一个Embedding层,用于保存词元位置
self.sequence_length = sequence_length
self.input_dim = input_dim
self.output_dim = output_dim
def call(self, inputs):
length = tf.shape(inputs)[-1]
positions = tf.range(start=0, limit=length, delta=1)
embedded_tokens = self.token_embeddings(inputs)
embedded_positions = self.position_embeddings(positions)
return embedded_tokens + embedded_positions ←----将两个嵌入向量相加
def compute_mask(self, inputs, mask=None): ←---- (本行及以下1行)与Embedding层一样,该层应该能够生成掩码,从而可以忽略输入中填充的0。框架会自动调用compute_mask方法,并将掩码传递给下一层
return tf.math.not_equal(inputs, 0)
def get_config(self): ←----实现序列化,以便保存模型
config = super().get_config()
config.update({
"output_dim": self.output_dim,
"sequence_length": self.sequence_length,
"input_dim": self.input_dim,
})
return config
你可以像使用普通Embedding层一样使用这个PositionEmbedding层。我们来看一下它的实际效果。