大语言模型中的嵌入模型
本教程将拆解什么是嵌入模型、为什么它们在NLP中如此重要,并提供一个简单的Python实战示例。

分词器将原始文本转换为token和ID,而嵌入模型则将这些ID映射为密集向量表示。二者合力为LLMs的语义理解提供动力。图片来源:[https://tzamtzis.gr/2024/coding/tokenization-by-andrej-karpathy/]
什么是嵌入模型?
在LLMs的语境中,嵌入模型是一种神经网络,旨在将文本(如单词、短语、句子)表示为连续向量空间中的密集向量。这些向量表示能捕捉文本项之间的语义关系,是现代NLP系统的基石。
例如:
- "king"和"queen"这两个词的嵌入向量可能在向量空间中非常接近。
- "king"和"man"之间的向量关系可能与"queen"和"woman"之间的关系类似。
想象完这些语义关系在向量空间中的样子后,我们可能会认为单词直接变成了这些能保留语义关系的向量。这种想法在讨论LLM处理流程中的令牌时可能会引起一些混淆。让我们稍微澄清一下关于分词的内容。
分词器和嵌入模型有什么区别?
在使用BERT、GPT等大语言模型(LLMs)时,经常会遇到两个关键概念:分词器和嵌入模型。虽然它们相关,但在处理单词的流程中扮演着不同的角色。
LLMs处理原始文本的一般流程如下:
- 原始输入文本:我们输入给模型的纯文本(例如“我爱机器学习”)。
- 分词器:将原始文本拆分为更小的单元(令牌)并将其转换为数字ID。
- 嵌入模型:将这些数字令牌ID映射到连续向量空间中的密集向量表示,捕捉语义含义。
- Transformer模型:使用自注意力层处理嵌入并生成预测(如下一个单词、情感、分类等)。
现在我们对流程中的分词器和嵌入模型有了更清晰的认识,让我们进一步明确什么是分词器,什么是嵌入模型。
什么是分词器?
分词器是流程中的第一个组件,负责:
- 将文本拆分为令牌:一个令牌可以是一个单词、子词甚至是一个字符。例如,句子“我爱机器学习”可能被分词为:
['我', '爱', '机器', '学习']
- 将令牌转换为ID:每个令牌被映射到模型词汇表中的唯一数字ID。例如:
['我', '爱', '机器', '学习'] → [101, 2173, 5956, 3627]
分词器使用预定义的词汇表(在模型训练期间构建)以确保训练和推理之间的一致性。分词器通常采用以下技术:
- WordPiece(BERT使用):将罕见词拆分为更小的子词单元。例如,“unbelievable”可能被分词为
["un", "##believable"],其中##表示子词。 - 字节对编码(BPE)(GPT使用):类似于WordPiece,但编码方式不同。
推荐观看Andrej Karpathy的这个视频:https://youtu.be/zduSFxRajkE?si=KGKPLninpxnHu3jN
什么是嵌入模型?
嵌入模型在分词之后发挥作用,其职责是:
- 将令牌ID转换为密集向量:每个令牌ID被映射到连续向量空间中的一个固定大小的向量(例如,BERT-base的向量大小为768)。这些向量称为嵌入。
- 捕捉语义含义:生成的嵌入表示令牌的含义,使得相似的单词或令牌在向量空间中更接近。
例如:
- "king"和"queen"这两个词的嵌入向量可能非常接近。
- 子词如“un”和“##believable”可能组合成“unbelievable”的有意义嵌入。
嵌入模型本质上是一个查找表,但它也可以编码上下文信息(例如,在BERT等模型中,嵌入是上下文感知的)。
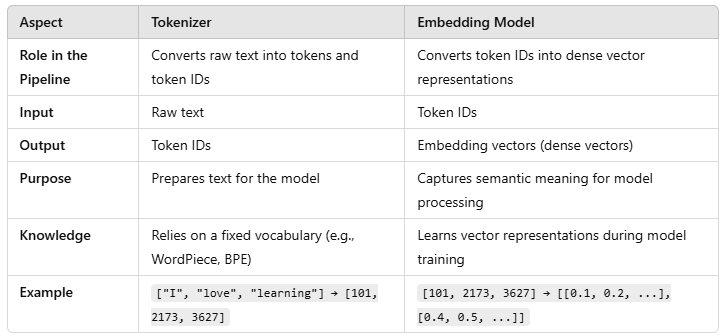
分词器和嵌入模型如何协同工作
让我们在LLM流程的更大背景下连接分词器和嵌入模型:
- 分词器:分词器为模型准备输入文本。例如:
输入文本:"我爱机器学习"
分词器输出:[101, 2173, 5956, 3627]
这里,[101, 2173, ...]是令牌ID。
2. 嵌入模型:令牌ID随后传递给嵌入层,将其转换为密集向量表示:
令牌ID:[101, 2173, 5956, 3627]
嵌入向量:[[0.1, 0.2, ...], [0.4, 0.5, ...], ...]
这些向量在训练期间学习,表示每个令牌的含义。
3. Transformer层:嵌入通过Transformer层(如自注意力)处理,计算上下文表示并生成预测。
为什么这种区分很重要?
理解分词器和嵌入模型之间的区别至关重要,因为:
- 分词器定制:在特定领域任务(如法律或医学文本)中,可能需要自定义分词器来处理专业术语(如“诉讼”、“MRI扫描”)。
- 预训练嵌入:你可以微调嵌入层以适应你的领域。例如,在医学文本上训练的嵌入与在一般新闻文章上训练的嵌入会有显著差异。
- 错误调试:下游任务中的问题通常源于分词问题,如词汇表外(OOV)单词或次优的分词策略。
一个类比来澄清概念
将LLM想象成一个工厂:
- 分词器:分词器就像原材料处理器,将文本拆分为工厂可以处理的单元。
- 嵌入模型:嵌入模型是生产线上的第一台机器,将这些原材料转换为中间产品(密集向量),供工厂的其他部分处理。
没有分词器,嵌入模型就不知道要处理什么。没有嵌入模型,Transformer层就没有有意义的输入。
分词器和嵌入模型的实战示例
from transformers import AutoTokenizer, AutoModel
# 第一步:加载分词器和模型
tokenizer