【C++ SIMD】第3篇:数据对齐与跨步访问(Windows/VS2022版)——以AVX为例
一、 理解数据对齐
1.1 什么是数据对齐
数据对齐指数据在内存中的起始地址是特定数值的整数倍。对于AVX指令集:
- AVX-256要求32字节对齐(地址末5位为0)
- AVX-512要求64字节对齐(地址末6位为0)
// VS2022中测试地址对齐的简单方法
#include <immintrin.h>
__m256 aligned_data; // 自动对齐的栈变量
printf("Aligned address: %p\n", &aligned_data);
float raw_data[8];
printf("Unaligned address: %p\n", raw_data);
1.2 对齐失败的后果
# 运行时错误示例(当使用_mm256_load_ps加载未对齐数据时)
Exception thrown at 0x...: Access violation reading location 0x...
1.3 编译器差异对比
| 编译器 | 默认栈对齐 | 动态内存对齐 | AVX支持标志 |
|---|---|---|---|
| MSVC | 16字节 | _aligned_malloc | /arch:AVX2 |
| GCC | 16字节 | aligned_alloc | -mavx2 |
| Clang | 16字节 | posix_memalign | -mavx2 |
二、AVX内存操作指令详解
2.1 关键指令对比
| 指令 | 对齐要求 | 吞吐量(Skylake) | 延迟(周期) |
|---|---|---|---|
| _mm256_load_ps | 强制对齐 | 0.5 | 4 |
| _mm256_loadu_ps | 无 | 1 | 6 |
| _mm256_store_ps | 强制对齐 | 1 | 4 |
| _mm256_storeu_ps | 无 | 1 | 5 |
2.2 性能实测对比
测试代码:
#include <immintrin.h>
#include <chrono>
#include <iostream>
#include <iomanip>
#include <cstdlib>
const int LOOP_COUNT = 10000000;
const int STRIDE = 16;
const size_t VECTOR_SIZE = sizeof(__m256); // 256-bit = 32字节
// 带宽计算工具函数
double calculate_bandwidth(double seconds, size_t bytes_transferred) {
const double GB = 1024.0 * 1024.0 * 1024.0;
return (bytes_transferred / GB) / seconds;
}
int main() {
// 内存分配(同之前版本)
float* aligned_ptr = static_cast<float*>(_mm_malloc(8 * sizeof(float) * LOOP_COUNT, 32));
char* unaligned_buffer = static_cast<char*>(_mm_malloc(8 * sizeof(float) * LOOP_COUNT + 32, 32));
float* unaligned_ptr = reinterpret_cast<float*>(unaligned_buffer + 4);
float* stride_ptr = static_cast<float*>(_mm_malloc(STRIDE * sizeof(float) * LOOP_COUNT, 32));
volatile float* sink_addr = static_cast<float*>(_mm_malloc(8 * sizeof(float), 32));
// 计算理论最大带宽(用于参考)
const size_t total_bytes = VECTOR_SIZE * LOOP_COUNT;
// 对齐访问测试
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < LOOP_COUNT; ++i) {
__m256 data = _mm256_load_ps(aligned_ptr + i * 8);
_mm256_store_ps(const_cast<float*>(sink_addr), data);
}
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> aligned_time = end - start;
double aligned_bw = calculate_bandwidth(aligned_time.count(), total_bytes);
// 非对齐访问测试
start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < LOOP_COUNT; ++i) {
__m256 data = _mm256_loadu_ps(unaligned_ptr + i * 8);
_mm256_store_ps(const_cast<float*>(sink_addr), data);
}
end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> unaligned_time = end - start;
double unaligned_bw = calculate_bandwidth(unaligned_time.count(), total_bytes);
// 跨步访问测试
start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < LOOP_COUNT; ++i) {
__m256 data = _mm256_load_ps(stride_ptr + i * STRIDE);
_mm256_store_ps(const_cast<float*>(sink_addr), data);
}
end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> stride_time = end - start;
double stride_bw = calculate_bandwidth(stride_time.count(), total_bytes);
// 输出格式化
std::cout << std::fixed << std::setprecision(2);
std::cout << "================== 内存带宽分析 ==================\n";
std::cout << "访问模式\t耗时(s)\t\t带宽(GB/s)\n";
std::cout << "-------------------------------------------------\n";
std::cout << "对齐访问\t" << aligned_time.count() << "\t\t" << aligned_bw << "\n";
std::cout << "非对齐访问\t" << unaligned_time.count() << "\t\t" << unaligned_bw << "\n";
std::cout << "跨步访问\t" << stride_time.count() << "\t\t" << stride_bw << "\n";
// 释放资源
_mm_free(aligned_ptr);
_mm_free(unaligned_buffer);
_mm_free(stride_ptr);
_mm_free(const_cast<float*>(sink_addr));
return 0;
}
测试结果:
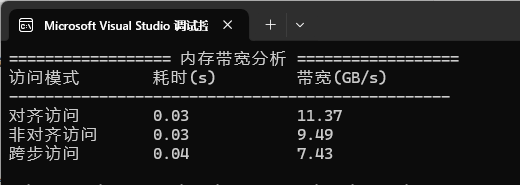
注:测试结果会根据不同的CPU数值上显示不同。