数据清洗的具体内容
(一)ETL介绍
“ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
在Transform的过程中,我们经常会做数据清洗这个操作。它是指对采集到的原始数据进行预处理,以去除错误、重复、不完整或不一致的数据,使数据符合分析要求的过程。它在整个数据分析和数据处理流程中处于非常重要的位置,因为数据质量的好坏直接影响到后续分析结果的准确性和可靠性。
清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序。
(二)需求分析
我们有去除日志中字段个数小于等于11的日志。
(1)输入数据
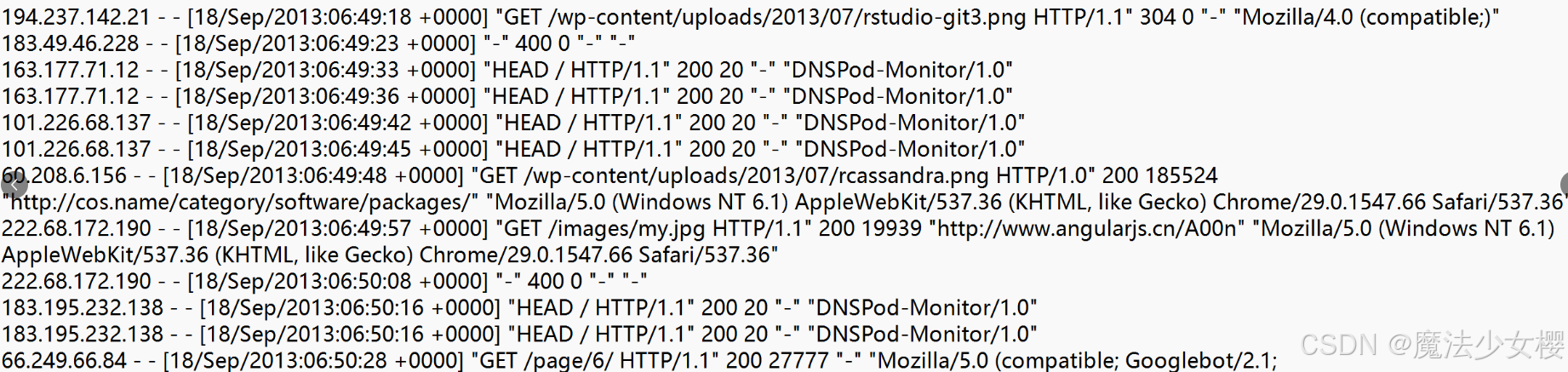
(2)期望输出数据:每行字段长度都大于11。
需要在Map阶段对输入的数据根据规则进行过滤清洗,并不需要进行汇总。
(三)思路分析
map阶段:按行读入内容,对内容进行检查,如果字段的个数少于等于11,就删除这条日志(不保留)去除日志中字段个数小于等于11的日志内容。
对于map函数来说,它的输入参数是:<偏移量,第一行的内容>
<偏移量,每一行的内容> → <刷选后的没一行的内容,null>
对于reduce函数来说,它的输入参数是:<刷选后的每一行的内容,[null,null,...]>,对于我们的需求来说,并不需要这个阶段。
(三)实现代码
在之前的项目的基础之上,重写去写一个包,并创建两个类:WebLogMapper和WebLogDriver类。
(1)编写WebLogMapper类
package com.root.mapreduce.weblog;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WebLogMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1. 获取一行数据,使用空格进行拆分,判断是否有8个字段
String[] fields = value.toString().split(" ");
if (fields.length > 7) {
// 这条数据是有意义的,保留
System.out.println(fields[0]);
context.write(value, NullWritable.get());
} else {
// 这条数据是无意义的,不保留
return;
}
}
}
- 编写WebLogDriver类
package com.root.mapreduce.weblog;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WebLogDriver {
public static void main(String[] args) throws Exception {
// 1 获取job信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 加载jar包
job.setJarByClass(LogDriver.class);
// 3 关联map
job.setMapperClass(WebLogMapper.class);
// 4 设置最终输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 设置reducetask个数为0
job.setNumReduceTasks(0);
// 5 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path("E:\\vm\\web.log"));
FileOutputFormat.setOutputPath(job, new Path("E:\\vm\\ouput2"));
// 6 提交
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
说明:reduceTask为0,表示没有reduce阶段,那么最终输出的文件个数与mapperTask的数量一致。