什么是向量搜索Vector Search?
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
现在大家都在采用向量搜索来适应用户需求。顾名思义,向量搜索是通过一种称为向量的概念来查找和比较对象的技术。简单来说,它帮你发现对象之间的相似性,让你能在数据中找到复杂且符合上下文的关联。这项技术是AI搜索类应用的幕后功臣。
向量搜索是现代数据平台(如向量数据库)中的一项AI驱动的搜索功能,帮助用户构建更灵活的应用。你不再局限于基础的关键词搜索,而是能跨越任何数字媒体类型,找到语义相似的信息。
它的核心是众多机器学习系统之一,由各种规模和复杂度的大语言模型LLM驱动。这些模型可以通过数据库和传统平台获取,甚至被推送到边缘设备,在移动端运行。
本文将介绍向量搜索、相关术语、功能及其在现代数据库技术和人工智能AI创新中的应用。
什么是向量?
向量是一种数据结构,存储了一组数字。在这里,它指的是保存了数据集数字摘要的向量,可以看作是数据的指纹或摘要,正式名称叫嵌入。以下是一个简单的例子:
|
"红苹果": [-0.02511234 0.05473123 -0.01234567 ... 0.00456789 0.03345678 -0.00789012] |
向量搜索的好处
向量搜索为数据库及其应用带来了一系列新能力。简而言之,它帮助用户在海量信息(即语料库)中找到更符合上下文的匹配结果。接近度的概念很重要——向量搜索通过统计方法将项目分组,展示它们的相似性或相关性。这不仅适用于文本,还适用于更多类型的数据,尽管我们的例子多为文本,以便与传统搜索系统对比。
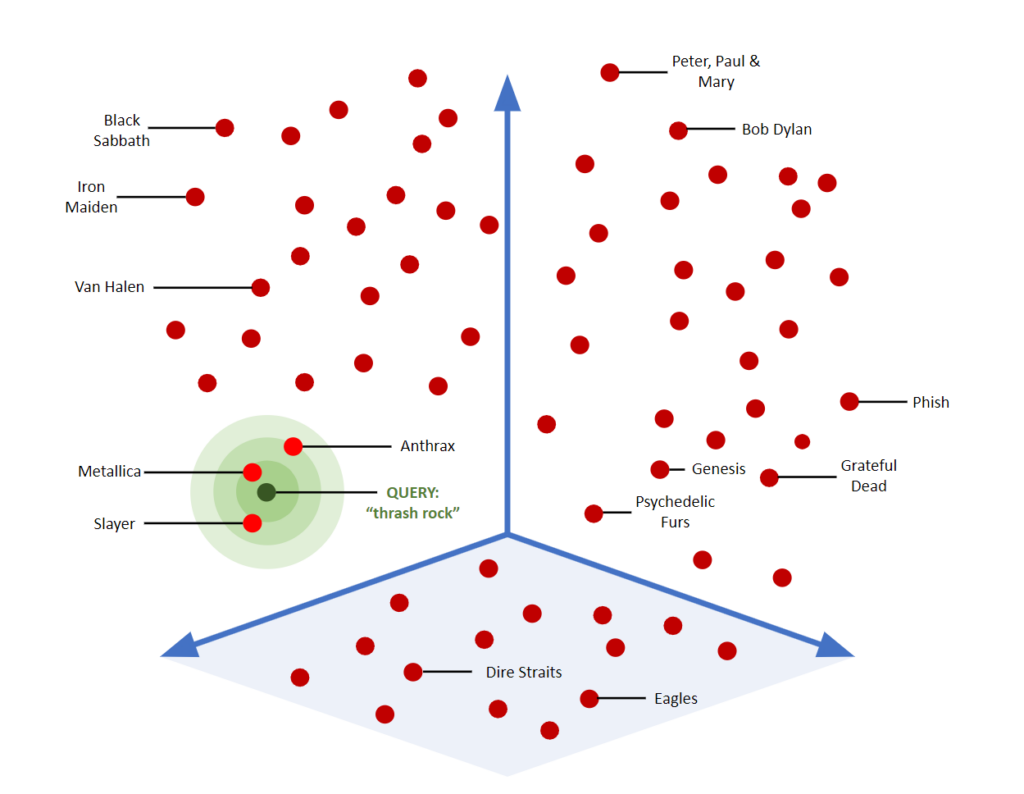
这张图展示了向量搜索如何在3D空间中映射、查找和分组“相似”对象的可视化示例。
获取海量通用知识
向量搜索也是将AI工具引入应用的好方法,提供了传统搜索工具无法实现的灵活适应性。由于有许多公开的大语言模型(LLM),任何公司都可以采用它们作为应用搜索的基础。LLM存储了大量信息,搜索它们的结果能为你的应用带来指数级价值,而无需编写复杂代码。这是许多应用通过新功能升级的方式之一。
超级搜索 vs. 传统搜索
幸运的是,在更复杂的场景中,向量搜索也是一种更快的搜索方法。传统的关键词搜索系统可以优化以在文档中查找匹配文本,但一旦需要应用复杂的模糊匹配算法或极端的布尔谓词变通方案(比如多个WHERE子句),搜索就会变慢且更复杂。
在复杂环境中成功搜索所需的各种权衡,可以通过向量搜索避免。不过,这需要一个服务级API(如OpenAI)和足够的资源来连接应用和LLM。根据你选择的LLM,你会有不同的选择和限制。
传统搜索与向量搜索的区别
上述好处与两种搜索方法的技术差异有所重叠。本节我们将深入探讨这些差异的核心。
上下文与语义搜索
许多搜索系统使用关键词或短语搜索,优化为查找精确的文本匹配或使用关键词频率最高的文档。但问题是,这些方法可能缺乏上下文和灵活性。例如,搜索“树”可能永远无法匹配实际树种名称的数据,尽管这些数据非常相关。这种上下文匹配是语义搜索的一种形式——单词之间的上下文和关系很重要。
相似性
向量搜索不仅关乎语义关系。例如,在文本应用中,它超越了使用单词和短语,还能通过输入单词、句子、段落等,在更深层次上匹配语义和上下文,找到相似的文档。
相似性搜索也适用于图像。如果你要写一个比较两张图像的应用,你会怎么做?如果只是逐个像素比较,你只能找到颜色、分辨率、编码等完全相同的图像。但如果你能分析图像并生成内容向量嵌入,就可以比较它们并找到匹配项。在图像例子中,向量嵌入描述了每张图像的内容,然后让你比较它们——这是一种更强大的比较和发现“接近度”的方法。
向量搜索的工作原理
向量搜索通过创建和比较向量嵌入来工作。其原理是数据可以转换为数字向量表示(嵌入),并与其他以类似数字表示(使用LLM)编目的数据进行比较。
它将不同类型的数字内容(文本、音频、视频等)索引为神经网络能理解的通用语言。
LLM创建的模型保存了代表训练数据的向量。例如,维基百科的每个段落都可以被摘要并索引为向量。然后,用户可以提交自己的数据向量(通常通过嵌入过程生成)到向量搜索系统,以找到相似的段落。
虽然背后有很多复杂的工作,但这就是其核心。
构建向量搜索应用的三个步骤
构建或使用向量搜索应用包括三个阶段:
- 为自定义数据或查询创建嵌入
- 使用基于大语言模型(LLM)训练的向量引擎比较结果,找到与模型中数据语料库最匹配的语义数据
- 将LLM结果与自定义应用数据或数据库进行比较,找到更相关的匹配
第一步——为请求创建嵌入
嵌入在向量应用中就像数据的指纹,类似于稍后可以在索引中使用的键。一段数据(文本、图像、视频等)被发送到向量嵌入应用,转换为数字表示(向量)。这个向量嵌入代表了输入到嵌入应用的对象。幕后,一个大语言模型(LLM)引擎被用来创建嵌入,以便在下一步中从同一LLM中检索匹配项。
在数据库领域,表列中的文本可以通过嵌入引擎处理,向量对象可以保存在该行或JSON对象的属性中。每个文档或记录的嵌入被索引,以便在搜索请求期间进行内部比较。
假设有一个零售目录的网页应用,用户可以输入描述服装类型和颜色的文本来搜索库存。应用将用户请求发送到LLM进行向量嵌入处理。LLM用于计算向量表示以供下一步使用。“红苹果”可能变成如下所示的高维数组向量,以JSON存储:
|
{ "word": "红苹果", "embedding": [0.72, -0.45, 0.88, 0.12, -0.65, 0.31, 0.55, 0.76] } |
这是一个过度简化的例子,但本质上,向量嵌入只是通过特定机器学习过程分析数据后生成的多维数组。嵌入有不同的类型和大小,基于各种LLM,但这超出了本文的范围。
第二步——从LLM中查找匹配项
假设LLM已经为其构建数据的所有部分创建了嵌入。如果LLM是用维基百科训练的,那么每个段落可能都有自己的嵌入。大量的嵌入!
搜索阶段是找到最接近匹配的嵌入的过程。向量搜索引擎可以接受现有嵌入,或从搜索查询动态创建一个。例如,它可以接受应用中的用户文本输入或数据库查询,并使用LLM查找模型中的相关内容。然后,它将最相关的匹配返回给应用。
继续零售例子,“蓝色T恤”的向量嵌入可以作为查找相似数据的键。应用将该向量发送到中央LLM,根据构建LLM时分析的文本描述或图像,找到最相似和语义相关的内容。
例如,你可能会得到一个包含五个文档的列表,它们的向量嵌入在相似性上匹配。如下所示,每个文档都有自己的向量表示。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "embeddings": [ { "word": "红苹果", "embedding": [0.72, -0.45, 0.88, 0.12, -0.65, 0.31, 0.55, 0.76] }, { "word": "烂苹果", "embedding": [0.71, -0.42, 0.85, 0.15, -0.68, 0.29, 0.53, 0.78] }, { "word": "小柯基", "embedding": [0.73, -0.46, 0.87, 0.11, -0.64, 0.33, 0.56, 0.74] }, { "word": "大别野", "embedding": [0.75, -0.41, 0.89, 0.14, -0.67, 0.28, 0.54, 0.77] }, { "word": "云南滇红", "embedding": [0.72, -0.44, 0.86, 0.13, -0.66, 0.30, 0.55, 0.76] }, { "word": "牛仔裤", "embedding": [0.70, -0.43, 0.84, 0.16, -0.69, 0.27, 0.52, 0.79] } ] } |
第三步——查找与自定义数据的匹配项
如果你只需要查找LLM中存储的信息匹配项,那么工作就完成了。但真正自适应的应用会希望从内部数据源(如企业数据库)中提取匹配和信息。
假设数据库中的文档或记录已经保存了向量嵌入,并且你从LLM中获得了匹配项。现在,你可以将这些匹配项发送到数据库的向量搜索功能中,找到相关的数据库文档。操作上,它就像另一个索引字段,但会给搜索结果带来更定性的感觉。
向量搜索如何找到匹配项?
向量搜索结合了三个概念:用户生成的数据(请求)、包含代表数据源模型的LLM语料库(模型),以及数据库中的自定义数据(自定义匹配)。向量搜索让这三个因素协同工作。
向量搜索支持什么?
只要能为任何类型的数据创建嵌入,并以相同方式(来自同一LLM)与其他嵌入进行比较,向量搜索就能找到相似性。
根据使用的LLM,结果可能会有很大差异,因为LLM的训练数据来源不同。例如,如果你想搜索相似的图像,但使用的LLM只包含古典文学,那么你会得到无法使用的结果(尽管如果是古典作家的图片,可能还有点希望)。
同样,如果你正在构建一个法律案例,而你的LLM只在Reddit数据上训练,那么你可能会陷入一个独特的场景,或许有一天能拍成一部好电影(当然,是在你被取消律师资格之后)。
这就是为什么确保支持你体验的LLM针对正确的向量搜索用例和你所需的信息非常重要。非常通用的LLM会有更多上下文,但针对你行业的专业LLM会为你的业务提供更准确和细致的信息。
大规模进行向量搜索
任何执行向量搜索的企业系统在生产环境中都必须能够扩展(参见我们的云数据复制指南)。这使得能够复制和分片索引的向量搜索系统尤为关键。
当系统需要搜索索引以查找匹配项时,工作负载可以分布在多个节点上。
同样,创建新嵌入并为其建立索引也将受益于资源隔离,这样其他应用功能不会受到影响。资源隔离意味着向量搜索相关功能拥有自己的内存、CPU和存储资源。
在数据库环境中,确保所有服务都正确分配资源非常重要,这样服务之间不会竞争。例如,表查询、实时分析、日志记录和数据存储服务都需要自己的空间,向量搜索服务也是如此。
分布式LLM访问API也很重要。由于许多其他服务可能调用嵌入,生成嵌入的API和系统也必须能够随着流量增长而扩展。对于基于云的LLM服务,确保在开始原型设计之前,它们的服务级别协议能够满足你的生产需求。
外部服务通常可以快速高效地扩展,但随着规模扩大,需要额外资金。在评估选项时,确保清楚了解价格滑动比例。
向量搜索的未来
大多数应用开发将由混合搜索场景驱动。单一的搜索或查询方法将无法满足未来的灵活性需求。混合搜索能力意味着你可以使用向量搜索获取语义匹配,同时使用基础SQL谓词甚至地理空间索引缩小结果范围。
将这些功能结合到单一的混合搜索体验中,将使开发者更容易从应用中提取最大灵活性。这包括将所有向量搜索功能扩展到边缘移动设备以及在云端和本地。
检索增强生成(RAG)将允许开发者在LLM之上添加更多自定义上下文感知。这将减少重新训练LLM的需求,同时为开发者提供保持嵌入和匹配最新的灵活性。
向量搜索还将通过一种可插拔知识模块定义,允许企业基于来自不同来源的LLM引入广泛的信息。想象一个维护电线杆的移动现场应用。语义图像搜索可能帮助识别电线杆物理结构的等等问题。
向量搜索常见问题
为什么向量搜索很重要?
向量搜索很重要,因为它提供了一种新颖的方法,利用最新的机器学习和AI技术,在数字数据之间找到相似性和上下文。
什么是向量搜索嵌入?
向量嵌入是保存了分析数据独特数字表示的向量。机器学习(ML)工具使用大语言模型(LLM)分析输入数据并生成描述数据的向量嵌入。然后,向量嵌入被保存在数据库或文件中供后续使用。
传统搜索和向量搜索有什么区别?
主要区别在于传统搜索优化为查找精确的关键词或短语匹配,而向量搜索旨在在更明确的语义上下文中找到相似概念。
向量搜索面临哪些挑战?
主要挑战是应用必须依赖大语言模型(LLM)来帮助创建嵌入和查找上下文匹配。