Doris:打破 SQL 方言壁垒,构建统一数据查询生态
在大数据领域,不同的数据库系统往往使用不同的 SQL 方言。这就好比不同地区的人说着不同的语言,给数据分析师和开发人员带来极大的困扰。当企业需要整合多个数据源进行分析时,可能要花费大量时间和精力,在不同的 SQL 语法之间切换。然而,Apache Doris 凭借强大的 SQL 方言兼容能力,打破了这一壁垒,为用户构建了一个统一的数据查询生态。
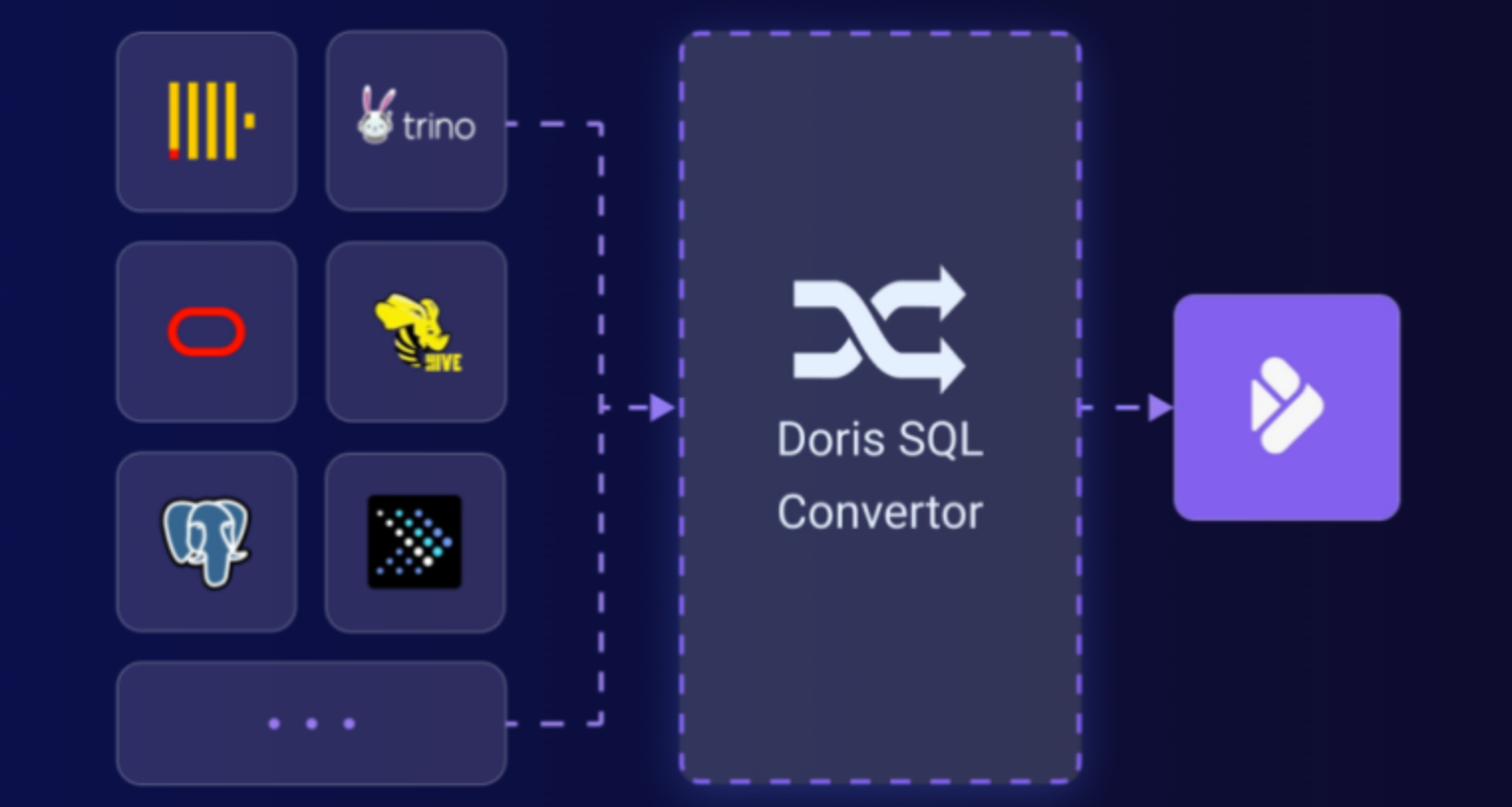
SQL 方言兼容:复杂数据环境下的 “通用语言”
在当今企业的数据架构中,数据分散在多个数据库系统中是常见现象。这些数据库系统各有特点,像 MySQL 常用于在线事务处理(OLTP),以高并发写入和事务处理见长;而 Hive 则是大数据离线分析的佼佼者,能处理海量数据。不同的数据库系统,使用不同的 SQL 方言,这使得数据分析师和开发人员,在跨系统查询和整合数据时困难重重。
Apache Doris 的 SQL 方言兼容功能,就像是一位翻译大师,帮助用户在不同数据库系统之间自由沟通。Doris 不仅支持标准 SQL 语法,还兼容多种主流数据库的 SQL 方言,极大降低了学习和使用成本。用户无需再为不同数据库系统的语法差异而烦恼,通过 Doris 就能轻松查询和分析来自多个数据源的数据。
Doris 如何实现 SQL 方言兼容
1. 解析器与优化器的 “智慧协作”
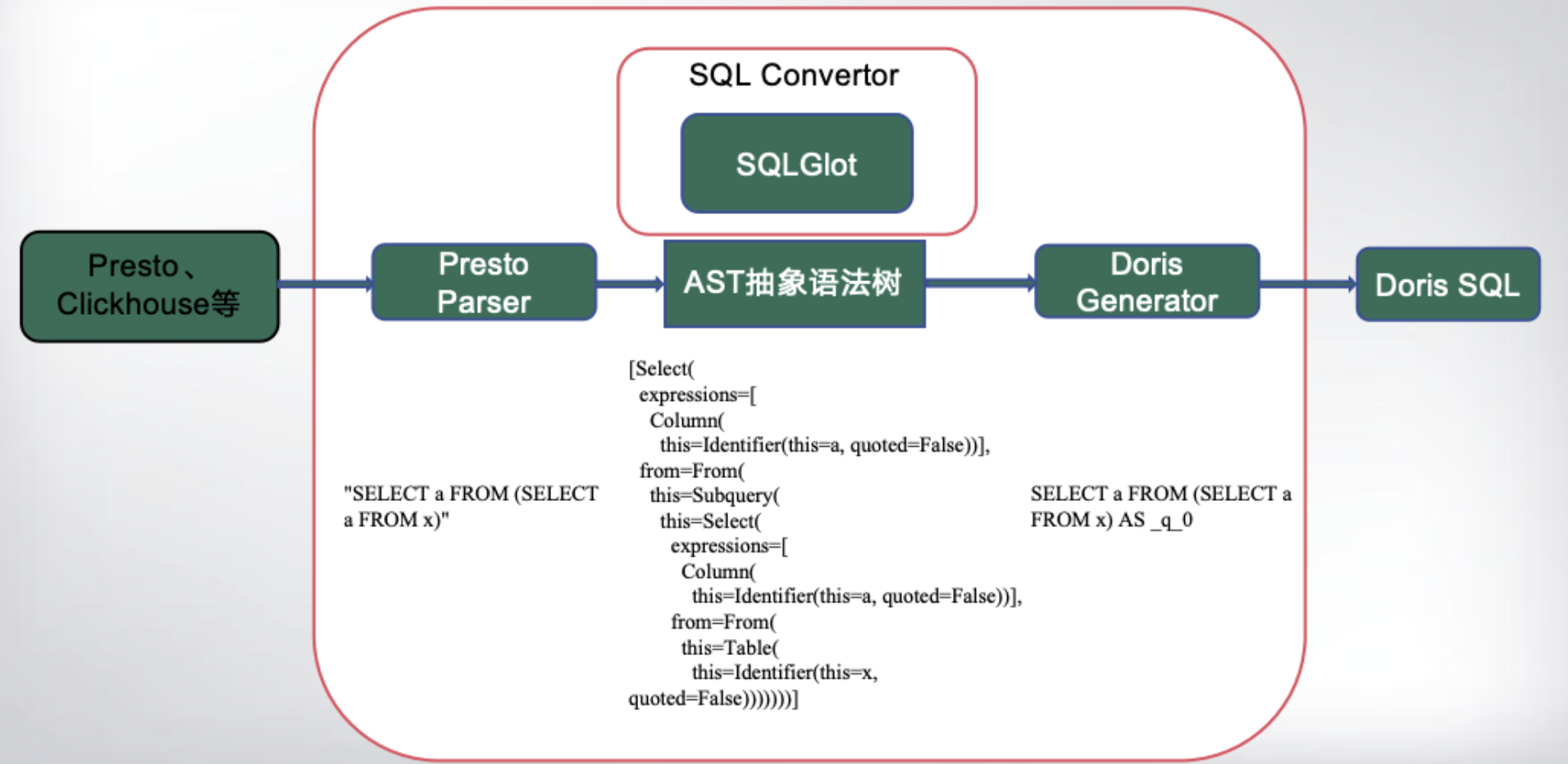
Doris 通过独特的解析器和优化器设计,实现对多种 SQL 方言的支持。当用户提交一条 SQL 查询时,解析器会首先对查询语句进行词法和语法分析,将其转化为抽象语法树(AST)。在这一过程中,解析器能够识别不同方言的语法结构,并进行相应处理。
随后,优化器会对抽象语法树进行优化。它会根据查询的语义和数据分布情况,生成高效的执行计划。这一过程中,优化器充分考虑了不同数据源的特点,选择最优的查询策略,从而确保查询在不同数据源上都能高效执行。
2. 元数据管理的 “无缝对接”
为了实现对不同数据源的统一查询,Doris 建立了一套完善的元数据管理机制。它能够自动发现并同步多个数据源的元数据信息,包括表结构、字段类型、索引等。这样,用户在 Doris 中查询数据时,就像在查询本地表一样方便,无需关心数据的实际存储位置。
同时,Doris 的元数据管理机制还支持实时更新,确保用户始终能获取到最新的数据源信息。这为用户提供了极大的便利,使其能够及时响应业务变化。
实际应用场景剖析
1. 使用 Doris 替换原来的OLAP系统
比如原有系统为 Trino、ClickHouse,切换到Doris。上游业务有大量已存在SQL业务逻辑,如果让业务方改变SQL方言,成本非常高。业务希望能够使用原有的SQL方言在Doris进行查询。
2. 统一SQL入口
Doris 作为OLAP统一入口。用户可能通过Doris查询Hive表,希望使用Hive/Spark的SQL方言。
3. 查询降级
用户使用Doris作为高速查询引擎,但如果一些查询不支持或失败(比如内存不够),SQL需要降级路由到比如 Spark 集群上运行。这种情况,用户希望统一用Spark方言,先发送给Doris,如果失败,直接再发送给Spark。
使用 Doris 实现 SQL 方言兼容的优势
1. 降低技术门槛
对于数据分析师和开发人员来说,Doris 的 SQL 方言兼容功能降低了学习和使用成本。他们无需花费大量时间学习不同数据库系统的 SQL 语法,通过 Doris 就能轻松查询和分析来自多个数据源的数据。这使得他们能够将更多精力集中在业务分析上,提高工作效率。
2. 提升数据整合效率
Doris 打破了不同数据库系统之间的隔阂,实现了数据的快速整合和分析。企业可以通过 Doris 建立统一的数据查询平台,让不同部门的人员都能方便地获取所需数据,促进数据的共享和利用,为企业的决策提供有力支持。
3. 保障业务连续性
在企业的数据架构不断演进的过程中,Doris 的 SQL 方言兼容功能为业务连续性提供了保障。即使企业更换或新增数据源,Doris 依然能够无缝对接,确保数据查询和分析不受影响。
结语
Apache Doris 的 SQL 方言兼容功能,为企业在复杂的数据环境中,提供了一种高效、便捷的数据查询解决方案。它打破了 SQL 方言的壁垒,让数据能够自由流动,为企业的数字化转型注入了强大动力。相信在未来,随着 Doris 的不断发展和完善,它将在更多领域发挥重要作用,助力企业实现数据价值的最大化。
如果你对 Doris 的 SQL 方言兼容功能感兴趣,不妨亲自尝试一下,感受它带来的便捷与高效!